Databases have five core constraints: check, not null, unique, primary keys, and foreign keys. Defining these helps improve data quality.
The challenge comes if you want to update an existing constraint. For example:
How do you alter the search condition for a check constraint? Or modify the columns in a unique constraint?
Short answer: You can’t ☹
The alter table ... modify constraint command only supports enabling or disabling it. If you want to change a constraint, you need to drop the current one and recreate it with the new criteria:
Easy enough. But there’s a problem.
There’s a period where neither the old nor the new constraint are present! It’s possible invalid data could sneak in during this window if the application is live.
Running the process above while applications are online has a further challenge. By default, adding, dropping, and disabling constraints are all blocking DDL statements in Oracle Database. This means you can’t change data while running these statements.
Luckily you can overcome these problems.
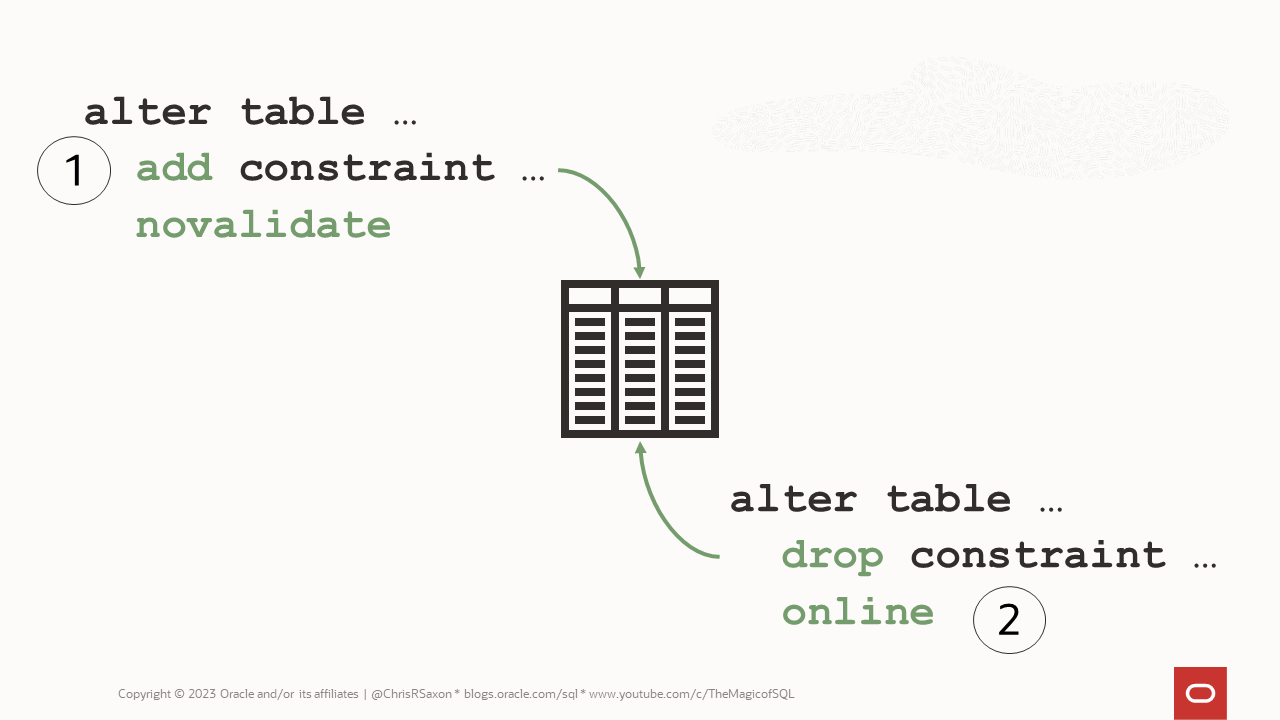
The basic process is:
- Add a new, unvalidated constraint
- Drop the old constraint online
⚠ Note: Like many online options, dropping constraints online is an Enterprise Edition feature.
There are some subtle differences in this method for each constraint type. We’ll investigate these in this post. Let’s dive into how to:
- Change check constraints
- Rename constraints
- Add not null conditions
- Alter unique constraints
- Modify primary keys
- Update foreign keys
- Add surrogate keys
- Watch the demo
- Get the cheat sheet
Disclaimer: for the purposes of this post, I’m assuming that the old and new constraints can coexist for at least a brief period. i.e. it’s still possible to change data while both constraints are active. If this is not the case you’ll need to use solutions like dbms_redefinition or Edition-based redefinition to handle the change online. This problem also only applies to changing data. You can still query tables while modifying their constraints. If you can make the affected parts of the application read-only while you do these changes you can keep it online.
If you want to play along at home, we’ll be using these tables:
How to alter check constraints
To change the condition for a check constraint while applications are online, the process is:
- Create a new constraint, unvalidated with the updated criteria
- Validate the new constraint
- Drop the old constraint online
Which looks like:
At this point you may be wondering:
What’s with novalidate?
This step is necessary to make the statement non-blocking. To see why, let’s compare the validate and novalidate states.
VALIDATE vs NOVALIDATE constraints
When you add a new constraint the database checks it’s not false for all existing rows. (This is subtly different to ensuring it’s true because the condition could evaluate to null).
On large tables this can take a long time. As this is blocking DDL, it could be impractical to impossible to do while customers can write to the table.
To speed up this process, you can create the constraint in the novalidate state. This only applies the constraint to DML you run after creating it. Existing rows are ignored.
This is a fast, online operation.

So why not leave it unvalidated?
There could be data in the table which violates an unvalidated constraint. So the database can no longer rely on it to optimize some operations. For example, using constraints to get better execution plans.
To overcome this it’s good practice to validate constraints. This ensures all existing rows satisfy the condition. Doing this is a fully online operation. How long this process takes depends on the size of the table.
It’s possible the new constraint conflicts with existing data. For example, if you remove a status from an in list or use more restrictive inequalities.
In these cases, you have to leave the new constraint unvalidated or clean the data first. Which path you take depends on why you’re changing it.
If you’re fixing a bug in the original constraint, you should also fix the existing data. If you’re changing a constraint to reflect business rule changes which don’t apply to old data, leaving the constraint unvalidated may be the way to go.
Once you’ve added the new constraint you can remove the original one. After doing this you may want to rename the new constraint to the original’s name.
How to rename constraints in Oracle Database
You can change the name of constraints with an alter table statement:
Sadly renaming is a blocking operation. The good news is it’s instant, so you only need to make the app read-only or offline for a brief period to do this.
How to add not null constraints online
To change whether a column is mandatory, you can modify it to make it (not) null. This is blocking DDL by default.
So are you stuck if you want to change the nullness without an outage?
No!
As with check constraints, you can add an unvalidated not null constraint online. To do this, tack novalidate after not null or use the add constraint command:
If there’s an existing not null constraint you want to remove, you can drop it online. To do this you need to find its name. Assuming – like most people – you defined the column not null without a specific name, you’ll have to look it up first.
You can do this by checking the data dictionary:
How to change columns in a unique constraint
Over time you may want to add or remove columns from a unique constraint. As with check constraints, you’ll need to create a new constraint and drop the original.
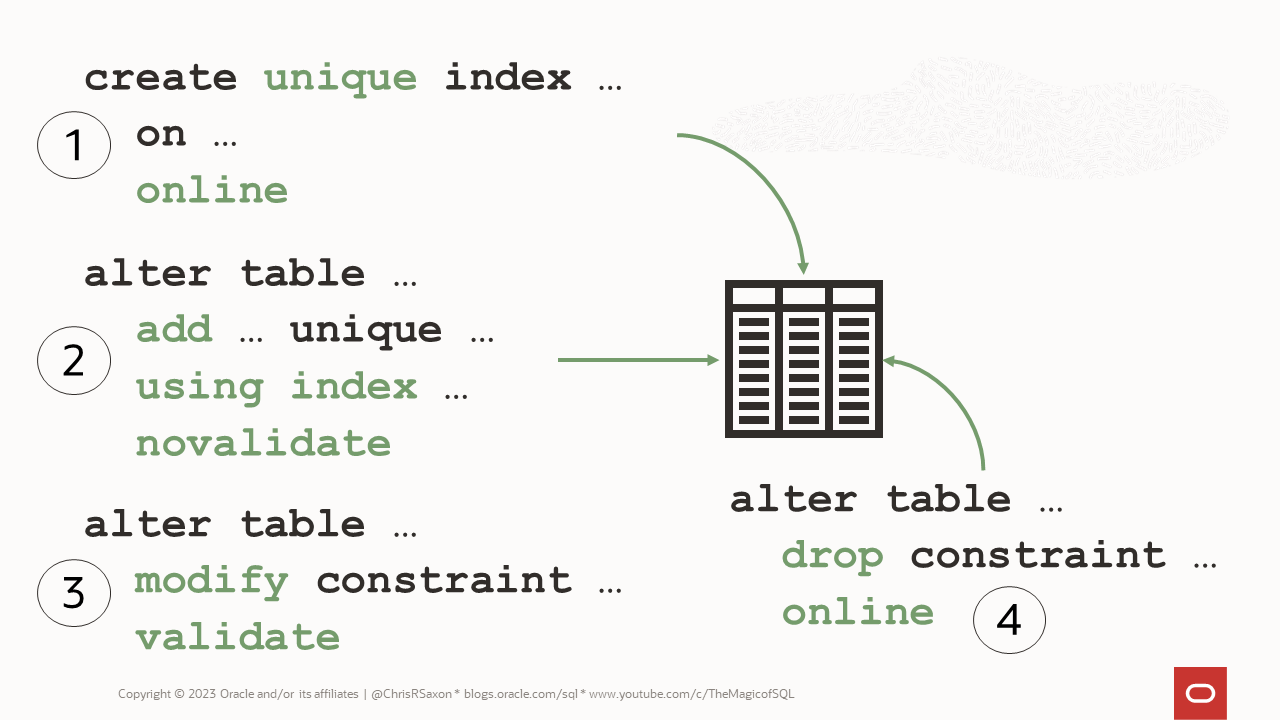
The process for doing this online has an extra step:
- Create a new unique index online (the online clause requires Enterprise Edition)
- Add an unvalidated constraint using this index
- Validate the constraint
You can then drop the original constraint and rename the new constraint and index if you want. Here it is in action:
It’s worth noting that the validation step is instant. The unique index means the database already knows there can be no duplicate values in its columns. All it needs to do is set the constraint’s state; there’s no need to check the data.
How to swap primary key constraints
The process of changing a primary key constraint is similar to a unique constraint. Namely you build a unique index online first, then make the new primary key on top of this index.
There are a couple of important differences though:
- A table can only have one primary key
- There may be foreign keys pointing to the current primary key
(Technically the second point also applies to unique constraints. Foreign keys can point at both unique and primary keys. In practice almost all foreign keys reference primary keys; usually you only have to consider them when changing primary keys.)
So while old and new unique constraints can co-exist, you must first drop the current primary key if you want to create a new one. The unique index for the new constraint means you can prevent duplicates during this process.
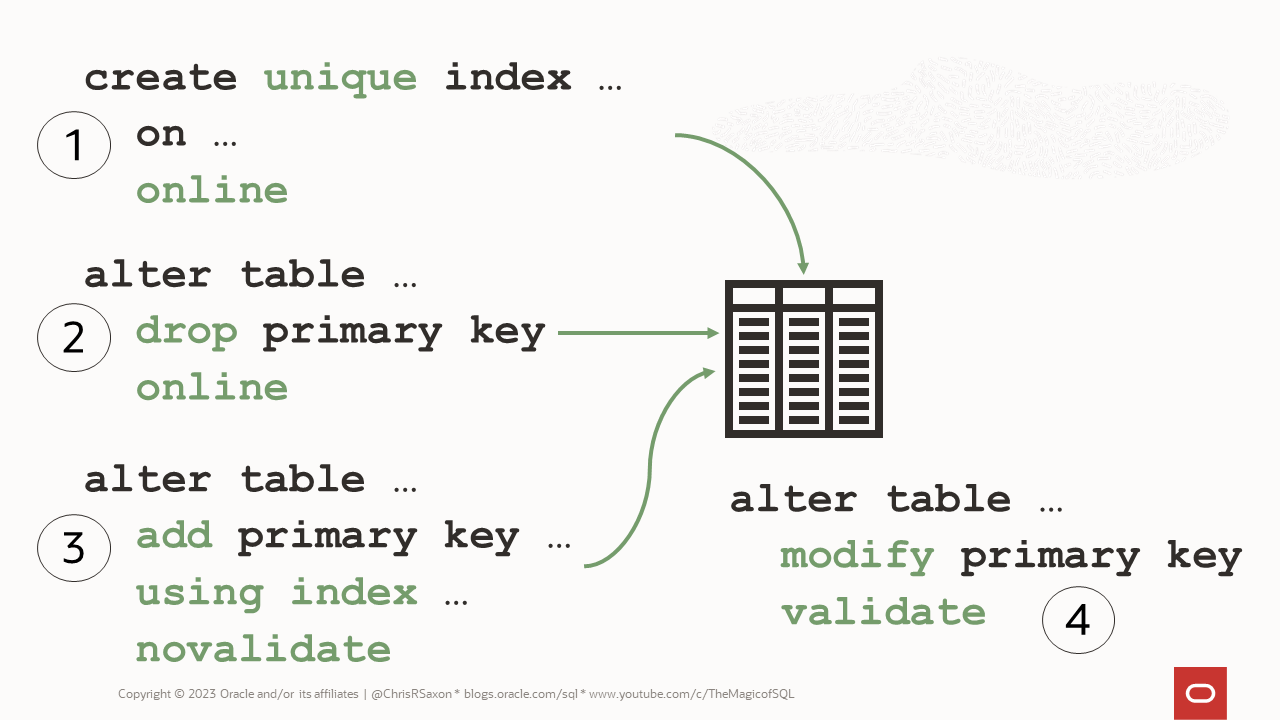
To drop a primary key you also have to remove any foreign keys pointing to it. You can do this in one command with the cascade clause:
This is an offline-only operation – the online clause is invalid. Any child tables will be unprotected until you can add foreign keys back onto them too.
So it’s worth asking:
Do you really need to change the primary key? Can you add a unique constraint instead?
As noted above, foreign keys can point to both of these constraints. The process could be:
- Create a unique index online
- Create an unvalidated unique constraint on this & validate it
- Update any child tables to use the unique constraint instead of the primary key
This allows you to minimize the time child tables have no foreign keys. Once these are all migrated, you can remove the old primary key (if it’s no longer relevant) or swap it for a unique constraint.
Which leads us nicely on to: how do you go about changing foreign keys?
How to change foreign key constraints
As discussed above, to change a primary key, you’ll have to update the foreign keys in all child tables. This normally means adding the new primary key’s columns to the child tables; a complex process.
So we’ll start with an easier problem: changing foreign keys on existing columns. You may be wondering:
Why would I ever need to do this?!
There are at least a couple of reasons. You may want to change:
- Its
on deleteordeferrableproperties - Which table the foreign key points to
The second is less common but also easier. This could happen if you decide to merge or split the parent table. Either way, one column can have foreign keys to two different tables.
So the process is the same as with check constraints:
- Create the new unvalidated foreign key
- Validate it
- Drop the old one (online)
If you want to modify the on delete or deferable properties it’s messier. A column can only have one foreign key pointing to each parent constraint. So to change these properties, you’ll need to remove the old constraint first.
This leaves you with a brief period where the table is unprotected. To overcome this you could use dbms_redefinition to define the new constraint.
To do this, create a temporary table cloning the current table. Add a foreign key this staging table with the new on delete status. Then run the redefinition process to copy the data over.
For example:
You can also use the dbms_redefinition method to change the deferrable state for any constraint. You can’t have two identical constraints on a table (except for check constraints!), so you need a process like this to change deferrable online.
Either way, this process only works if the foreign key columns are the same. Let’s finish with a harder problem: changing the parent key.
How to add a surrogate key to a table and its children
There’s one challenge all developers dread: changing a natural primary key to a surrogate.
This is a hard problem!
Primary key columns could be referenced by many tables and millions of rows. Even worse, the columns could be several tables deep. Cascading the new key to all child tables can be time consuming and fiddly.
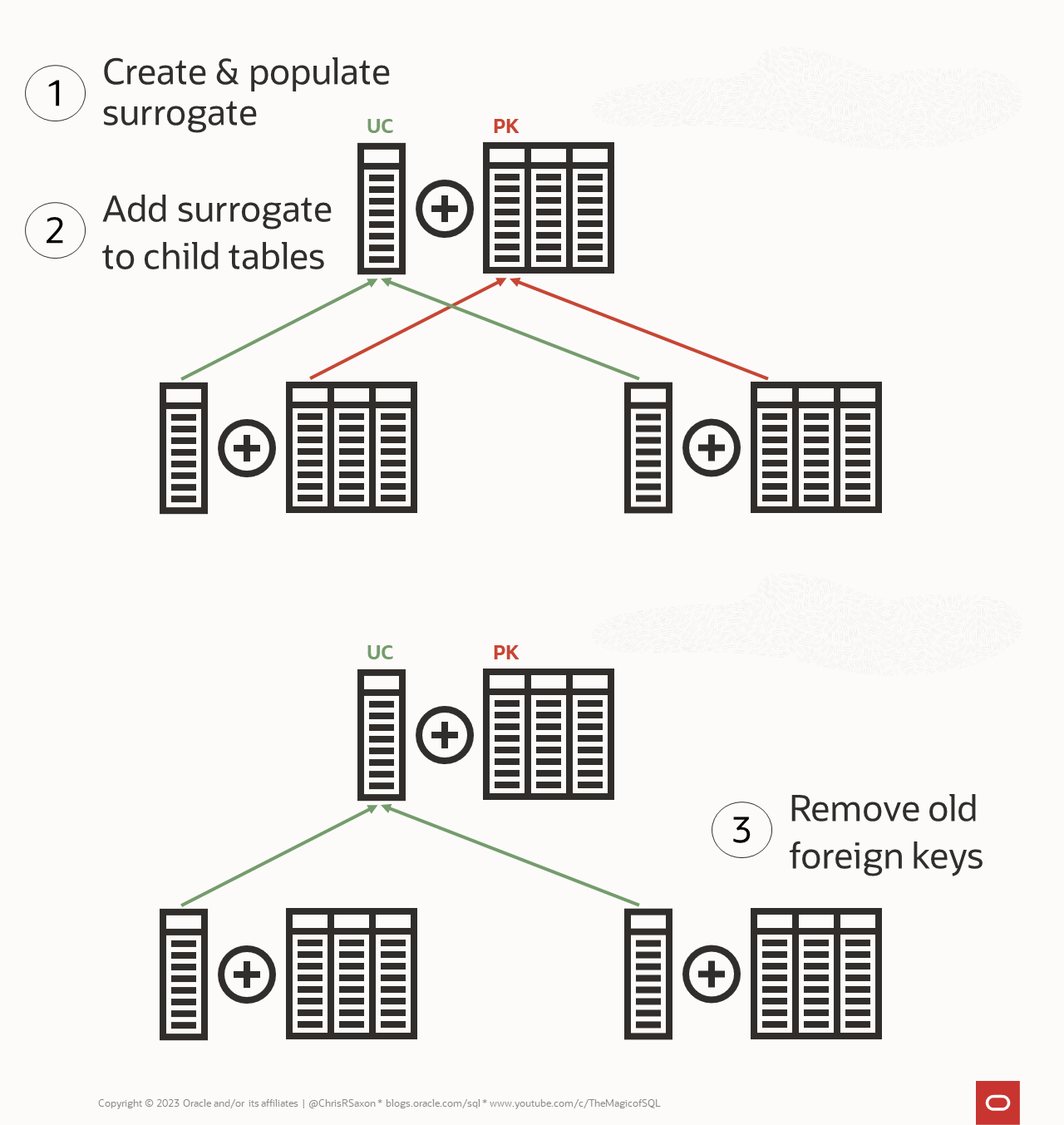
Here’s an overview of how to add a surrogate key with minimal downtime:
- Add & populate the surrogate column to the parent table
- Add a unique constraint on this surrogate
- Add & populate the surrogate column on the child tables
- Add foreign keys on the surrogate columns
- Drop the old foreign keys
- Remove the old foreign key columns (this can be deferred as long as needed)
How you carry this out depends on many factors, including:
- Uptime requirements
- Number of tables and rows affected
- Urgency of changing the PK
For example, if you need to switch the primary key now and can afford to take an extended outage, take the app offline. Then use create-table-as-select to rebuild the child tables.
Of, if you can only afford a few minutes of downtime and can continue with the current primary key for a while, a more online process is:
- Add the surrogate to the parent table with a unique constraint
- Add the surrogate columns to the child tables
- Use
dbms_redefinition.execute_updateto populate these child columns - Add the new foreign keys
- Remove the current foreign keys
You could also use Edition-based redefinition to run the process with zero downtime. The difference is you use cross-edition triggers to populate the new surrogate columns.
At this point you’re done. But now you have a table where all the foreign keys point to its unique constraint instead of the primary key. Most people would find this surprising!
A major reason for using primary keys instead of unique constraints is a form of documentation. You’re telling future developers: “This should be the target of foreign keys”. To reduce confusion, it’s a good idea to replace the old primary key with a unique constraint.
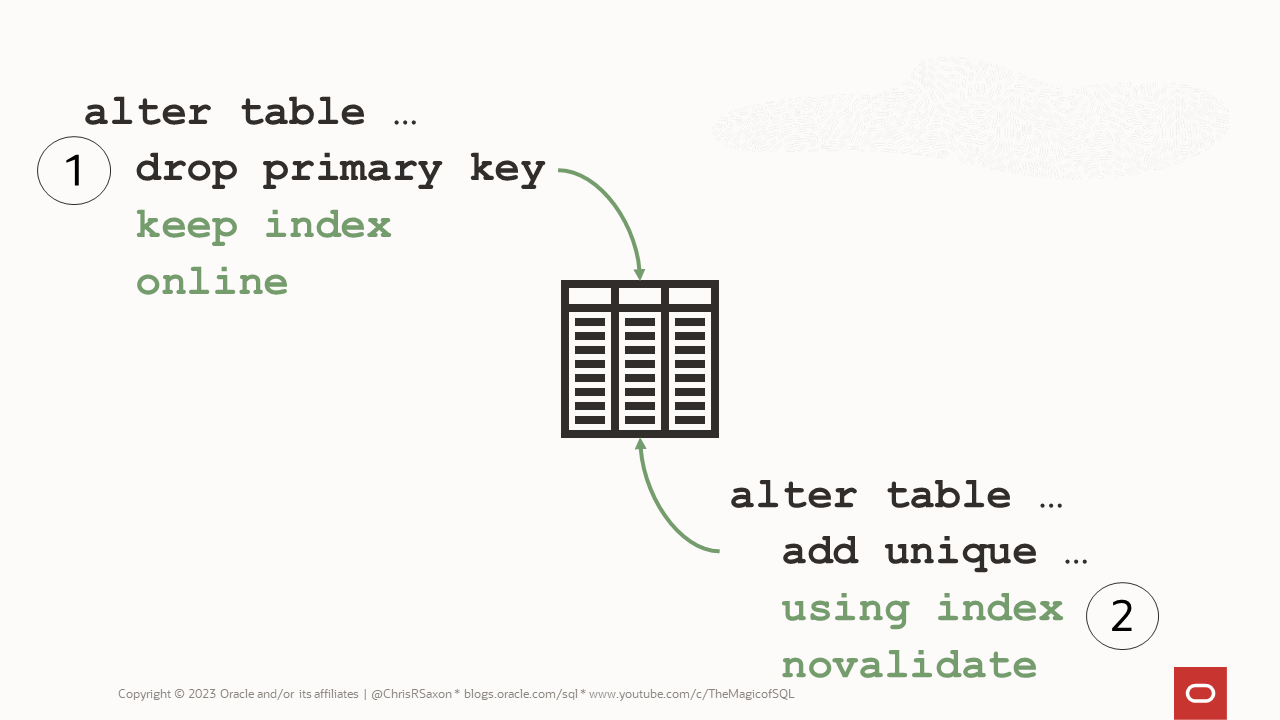
The best way to do this is:
- Drop the primary key, keeping its index
- Build a unique constraint using this index
This avoids having to recreate an index. On large tables this can be a huge time saver. Assuming the old primary key used a unique index (the default), duplicates are also prevented while you do this switch.
The SQL to do this is:
See it in action
Want to see a demo of these processes?
I showed how to swap constraints in July’s Ask TOM SQL Office Hours; here’s the recording:
Changing constraints online cheat sheet
Here’s a summary of the commands to change constraints online:

UPDATED 9 Aug 2023: Embedding recording of Office Hours session.
