There are some things in life it’s great to have spare copy of. Your keys, your kidneys and your backups to name a few.
But there are some things you don’t want duplicated. Rows in your database tables are a perfect example.
So it’s unsurprising a common question people working with relational databases have is:
“How do I find duplicate rows using SQL?”This is often closely followed with:
“How do I delete all but one of the copies?”In this post we’ll look at how you can use SQL to:
But before we can do any of this, we need to define we mean by duplicated rows.

What is a Duplicate Row?
The dictionary definition of this is:
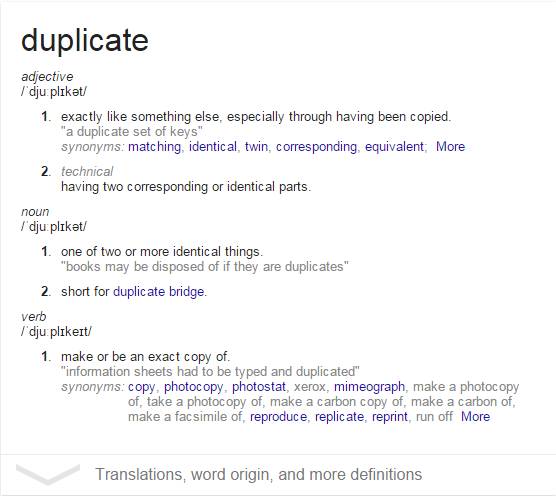
So you’re looking for two (or more) rows that are copies of each other. For example, the two rows below hold identical information:
TITLE UK_RELEASE_DATE LENGTH_IN_MINUTES BBFC_RATING ------- ----------------- ----------------- ----------- Frozen 06-DEC-2013 00:00 102 PG Frozen 06-DEC-2013 00:00 102 PG
But often you need to find copies on a subset of the columns. For example, it’s common for tables to have an ID column. This means the rows are no longer exact copies. But all the “real world” information is repeated:
FILM_ID TITLE UK_RELEASE_DATE LENGTH_IN_MINUTES RATING
---------- ---------- ----------------- ----------------- ------
1 Frozen 06-DEC-2013 00:00 102 PG
2 Frozen 06-DEC-2013 00:00 102 PG
Or maybe there are only one or two column values that are copies. It is common for websites to use your email address as your username. So if you have more than one email address in your user accounts table, how do you know who is who?
USER_ID EMAIL_ADDRESS FIRST_NAME LAST_NAME ------- ------------- ---------- --------- 1 abc@xyz.com Dave Badger 2 abc@xyz.com Sarah Fox
So your first step to finding the duplicates is defining which columns form a repeating group.
In the first films example above the rows are exact duplicates. So you may be tempted to say “all columns”. But what if you insert another row like this:
TITLE UK_RELEASE_DATE LENGTH_IN_MINUTES BBFC_RATING ---------- ----------------- ----------------- ---------- Frozen 06-DEC-2013 00:00 90 U
So when looking for copies here, you want to use:
title, uk_release_date
Once you’ve defined which columns you need to check for duplicates, you can move on to step two.
How to Find the Duplicates
| There are many ways you can find copies. Using group by is one of the easiest. To do this, list all the columns you identified in the previous step in the select and group by clauses. You can then count how many times each combination appears with count(*): select title, uk_release_date,
count(*)
from films
group by title, uk_release_date |
 |
This returns you a single row for each combination. This includes the rows without duplicates. To return just the copied values you need to filter the results. This is those where the count is greater than one. You can do this with a having clause, like so:
select title, uk_release_date, count(*) from films group by title, uk_release_date having count(*) > 1;
If you want to display the all the rows you need another step. Query the table again. Filter it by checking where the rows are in the results of the above query:
select * from films where (title, uk_release_date) in ( select title, uk_release_date from films group by title, uk_release_date having count(*) > 1 )
So far so good. You’ve had to list the table twice though. So it’s likely you’ll have two full scans of the table, as this execution plan shows:

For large tables, this could take a long time. It would be better if you could reference the table once.
Analytics to the rescue!
select f.*,
count(*) over (
partition by title, uk_release_date
) ct
from films f;
So what difference does this make?
Unlike group by, analytics preserve your result set. So you can still see all the rows in the table. This means you only need to list the table once.
You still need to filter the results though. Currently it includes the unduplicated values. You can’t use analytic functions in the where or having clauses:
select f.* from films f where count(*) over (partition by title, uk_release_date) > 1; ORA-00934: group function is not allowed here
So you need to do this in an inline view:
select *
from (
select f.*,
count(*) over (
partition by title, uk_release_date
) ct
from films f
)
where ct > 1
with film_counts as ( select f.*, count(*) over (partition by title, uk_release_date) ct from films f ) select * from film_counts where ct > 1
With a list of the duplicates in hand, it’s time for the next step!
How to Delete the Duplicate Rows

|
Now you’ve identified the copies, you often want to delete the extra rows. For simplicity, I’m going to assume that either the rows are exact copies or you don’t care which you remove. If there is only a handful, you could do this by hand. But this is unworkable if there are a large number of duplicates. It’s better to build a single statement which removes all the unwanted copies in one go. To do this, you must first decide which rows you want to keep. For example, you might want to preserve the oldest row. To do this you’ll need another column in the table (e.g. insert date, id, etc.) that is not one of the copied values. |
Assuming you have this, there are two ways you can build your delete. If your driving column is unique for each group, but may have duplicates elsewhere in the table, you’ll need a correlated delete. Insert dates fall into this category.
In contrast, if the defining column is unique across the whole table, you can use an uncorrelated delete. A good example of this is an id column which is the table’s primary key.
Correlated Delete
Correlated means you’re joining the table you’re deleting from in a subquery. You need to do this on your duplicate column group. Take the minimum value for your insert date:
delete films f where insert_date not in ( select min(insert_date) from films s where f.title = s.title and f.uk_release_date = s.uk_release_date )
This finds, then deletes all the rows that are not the oldest in their group. There is always one oldest row in each batch. So this only removes the extras.
Remember: this solution will only work if the column you’re taking the minimum of is unique for each group. But the column can have copies in other groups.
Uncorrelated Delete
An uncorrelated delete is similar to the previous example. The difference you don’t need the joins. The subquery here is like the original group by example you made to find the copies. Then add the id or other unique column as appropriate. For example:
select min(film_id) from films group by title, uk_release_date
This gives you the value of the first entry for each combination. This includes any unduplicated groups. So you want to get rid of all the rows not in this set. Do this by deleting those not in this subquery:
delete films where film_id not in ( select min(film_id) from films group by title, uk_release_date )
Both these methods only work if you have a column which is not part of the group. If the rows are fully duplicated (all values in all columns can have copies) there are no columns to use! But to keep one you still need a unique identifier for each row in each group.
Fortunately, Oracle already has something you can use. The rowid.
All rows in Oracle have a rowid. This is a physical locator. That is, it states where on disk Oracle stores the row. This unique to each row. So you can use this value to identify and remove copies. To do this, replace min() with min(rowid) in the uncorrelated delete:
delete films where rowid not in ( select min(rowid) from films group by title, uk_release_date )
And hey presto, you’ve removed all the extra rows! If there are many duplicates, this can take a long time. Luckily Oracle Database has many tricks to help you delete rows faster.
How to Prevent More Duplicates
| You’ve gone to all the effort of removing the duplicates. You’re feeling good. But a week later a new ticket comes in: “Please remove duplicate customer accounts”. All that hard work for nothing! OK, you’ve got your delete ready, so you can run it again. And again. And again. |
 |
After a while you’ll likely become bored of this. So you create a job to remove the duplicates. But this doesn’t solve the problem. There will still be times between job runs where the table could have duplicates.
A better solution is to stop people entering new copies. You could do this by adding some front-end validation. But people could still enter duplicates. Either because the code doesn’t handle concurrency properly (note: this is an easy mistake to make) or someone ran a script directly on the database.
Either way, you’re still left dealing with duplicates. So what can you do?
The answer’s easy: create a unique constraint. Include in this all the columns that form the duplicate group you identified at the start:
alter table films add constraint
film_u unique (title, uk_release_date)
With this is in place, any attempts to add copies will throw an error:
insert into films values ( 3, 'Frozen', date'2013-12-06', 100, 'U', sysdate ); SQL Error: ORA-00001: unique constraint (CHRIS.FILM_U) violated
You may need to update your application to handle the ORA-00001 exceptions you’ll now receive.
Alternatively, you can ignore these. As of 11g Release 2 you can change your inserts to use the IGNORE_ROW_ON_DUPKEY_INDEX hint. Or there’s a way to get around this with triggers. Be warned though, both of these solutions cause inserts to fail silently. So the data your users entered “disappears”. People tend to be unhappy when this happens!
So you start creating the constraint. But you hit either or both of the following problems:
- It takes too long to add it.
- It fails because people added new duplicates between you deleting the originals and adding the constraint.
The simple solution to the second problem is to take an outage. But if adding it takes a long time this may not be a viable option.
It would be nice if there was a way to ignore the existing rows, while also ensuring that there are no new duplicates.
Fortunately there is!
Unvalidated Constraints
When you create a constraint, by default Oracle validates it. Meaning is checks all existing rows to ensure they meet it. But you can add a constraint without doing this. You do this by specifying novalidate.
This creates the constraint instantly. It doesn’t work as you would expect with unique constraints though:
alter table films add constraint film_u unique (title, uk_release_date) novalidate SQL Error: ORA-02299: cannot validate (CHRIS.FILM_U) - duplicate keys found
Why is this happening?
Normally Oracle policies a unique constraint with a unique index. It automatically creates this for you, regardless of whether you validate the constraint or not.
To overcome this, you need to use a non-unique index. You can create this beforehand as normal. Or you can define it right in the constraint definition:
alter table films add constraint
film_u unique (title, uk_release_date)
using index (
create index film_i on
films (title, uk_release_date)
) novalidate
To ensure there are no duplicates, you need to validate the constraint.
This opens up another way to find the copies. When you validate it, you can log any violating rows to an error table. You do this with the exceptions into clause.
To use you this you need an exceptions table. You can do this with the supplied script $ORACLE_HOME/rdbms/admin/utlexcpt.sql. Or the following create table:
create table exceptions (
row_id rowid,
owner varchar2(30),
table_name varchar2(30),
constraint varchar2(30)
)
With this in place you can run:
alter table films modify constraint film_u validate exceptions into exceptions
Note that this doesn’t remove the failing rows. You still need to do that yourself. But it does find them for you. You can use this information to filter the rows you’re deleting:
delete films
where rowid in (
select row_id from exceptions
where table_name = 'FILMS'
and constraint = 'FILM_U'
and owner = sys_context('userenv', 'current_user')
)
and rowid not in (
select min(rowid)
from films
where rowid in (
select row_id from exceptions
where table_name = 'FILMS'
and constraint = 'FILM_U'
and owner = sys_context('userenv', 'current_user')
)
group by title, uk_release_date
having count(*) > 1
)
If the number of duplicates relative to the size of the table is small, this approach may make your delete faster. This is because it can swap a full scan of your table for rowid lookups:
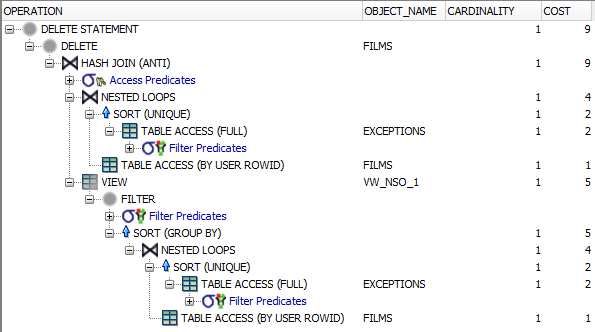
If your table has hundreds of millions of rows or more, this could massively reduce how long the delete takes.
Conclusion
Dealing with duplicate rows is a common problem in poorly designed databases. We’ve seen three ways for finding them:
- Group by
- count(*) over (partition by …)
- Creating a unique constraint with save exceptions
You can then remove the offending rows using uncorrelated deletes (if the driving column is unique across the whole table) or correlated deletes (if it’s only unique within each duplicate group).
Whichever approach you take, it’s a good idea to create an unvalidated unique constraint first. If you don’t, new people may enter new duplicates while your delete is running. Which means you may need to run the delete again. And again. And again…
Adding the constraint prevents you from chasing your tail. You can then clean the data at your leisure.
Do note that having non-unique index supporting a unique constraint could lead to performance issues. So once you’ve fixed your data you may want change the index to be unique. But you can’t change the uniqueness of an existing index. You need to create a new one.
Before Oracle Database 12c you could do this by adding a constant to the index of the unvalidated constraint, like so:
alter table films add constraint
film_u_temp unique (title, uk_release_date)
using index (
create index film_i on films (title, uk_release_date, 'a')
) novalidate;
Then add the unique index once the data are clean:
create unique index film_ui on films (title, uk_release_date);
Fortunately, as of 12c you can create two (or more) indexes on the same columns – provided only one is visible! So there’s no need for the constant nonsense.
Want to try this out for yourself?
Head over to LiveSQL to run the scripts in this post.
What do You Think?
Which method do you like best? Are there any other ways you could find and remove duplicates?
Let us know in the comments!
Learn SQL in Databases for Developers: Foundations
UPDATED: 21 July 2017, fixed explanation about switching normal index for unique (comment from guest on 31 Aug 16) and formatting fixes.
UPDATED: 18 Apr 2019, formatting enhancements
UPDATED: 22 Apr 2019; added “TOC” links and moved picture location
UPDATED: 14 Apr 2025: changed Live SQL link to use new platform
