Often you want to see if two tables have the same data content. For example, to check data loads worked, verify query changes return the same data or see what’s changed recently.
The basic way to do this is with set operations:
This finds all the rows in the first table not in the second (t1 minus t2). Then the opposite (t2 minus t1). Finally it combines the result of these queries together to return the differences.
It does the job, but has a major downside: it reads both tables twice!
When comparing large tables or complex queries this can lead to lots of unnecessary work. Luckily there ways to compare tables while reading each once.
Read on to learn how to:
- Find different rows with full outer joins
- Find unmatched rows between tables with group by
- Make a reusable data comparison function
- Compare complex queries
- Find recent data changes
- Show the column differences for mismatched rows
To see these in action, watch the recording of the Ask TOM Office Hours session on this topic. For a quick summary, check the cheat sheet at the end of this post. Scripts to setup the tables to play along are also at the end of this post.
How to find different rows with full outer joins
Instead of using set operations, you can join the tables together on the columns you want to compare.
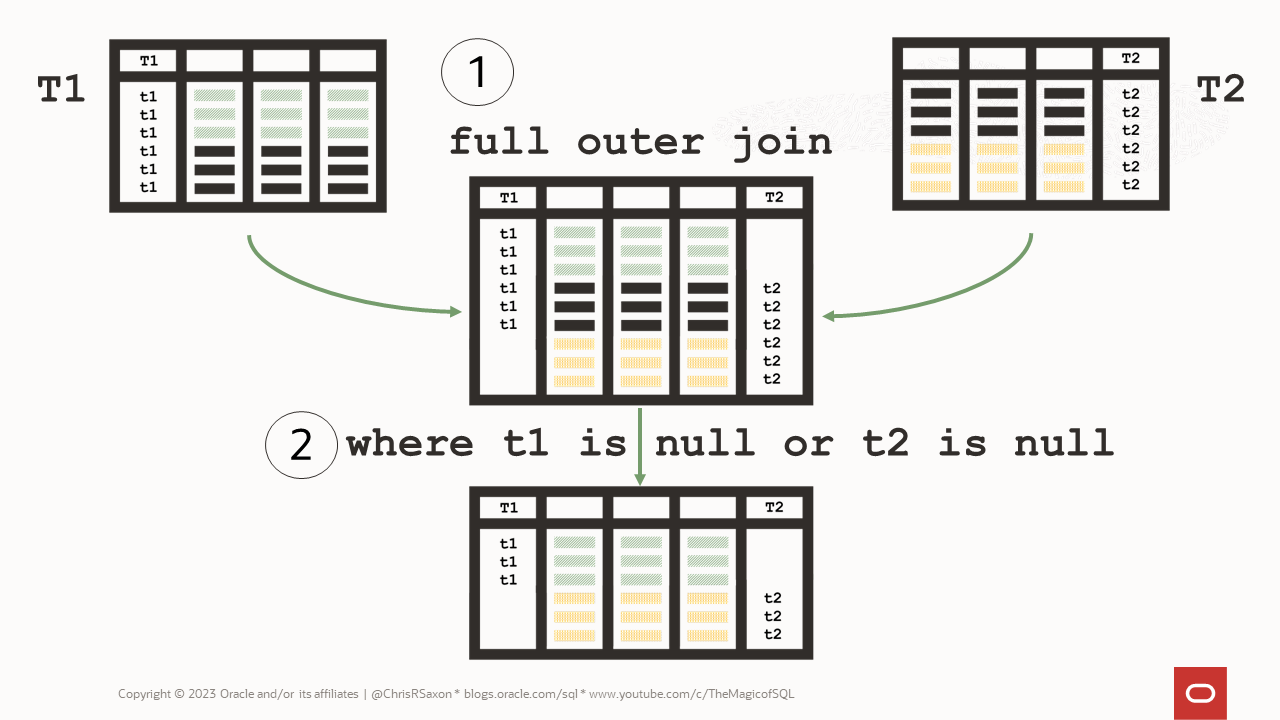
The process is:
- Query each table, adding an expression to each stating its source
- Full outer joining these queries together
- Filter the result to show the rows only in one table
To do this you need to list all the comparison columns in the join clause. If the tables have many columns this can be tedious.
Lukas Eder came up with a trick to simplify this: a natural full join! This generates the join clause from the common column names.
Which looks like:
In the query above:
- The
natural full joinclause joins the tables, returning the matched and unmatched rows in each - The
whereclause returns only those rows with no match in the other; i.e. the differences
This method has a few advantages:
- There’s minimal typing
- It automatically finds columns with common names
You can adapt this technique to compare columns with different names that (should) store the same values. Manually write the join clause to do this.
A big drawback to this method is you’ll get wrong results if any of the columns return null. You can overcome this by writing the join clause to handle nulls. This is a faff if there are many optional columns.
An alternative to compare nulls is to convert the columns to JSON objects. Then see if these are the same in the join clause.
To do this:
- Use
json_objectto turn the columns into a JSON object. From Oracle Database 19c you can usejson_object(*)to create JSON using all the table’s columns - Use
json_equalin the join clause to compare the objects. Because the comparison is across the whole JSON object, it handlesnullvalues automatically.
Which looks like:
Ensure you include a column comparison in the join clause! Ideally on the tables’ primary keys.
Without this the optimizer is unable to use a hash join to link the tables. It falls back to nested loops instead. Even on small data sets this can be incredibly slow.
Even with the primary key in the join, comparing JSON objects is the slowest of the methods in this post by far.
So why bother with this approach?
Comparing JSON objects has an advantage over all the other methods:
It handles lob columns.
The other methods will raise an exception if there are clob or blob columns. To compare these types you need techniques like hashing the data or dbms_lob.compare. Using JSON “just works”.
However you write a full outer join, it has another challenge: handling duplicates.
If a row appears twice in one table and once in the other, the join method ignores the extra row. In some cases this may be acceptable. Often you want to see the excess rows.
You can do this by adding a row_number to each query. This partitions the data by the comparison columns. Then include the output of this function in the join clause.
This gets fiddly. A simpler method is to use group by to find the mismatches.
How to get unmatched rows between tables with group by
Another way to find different rows is to count the number in each table. Then return rows where there is a mismatch in these counts.

Do this like so:
- Query each table, adding two columns. These return one and zero, e.g.
select … 1 as t1, 0 as t2. Flip the one and zero for these columns when querying the other table so they’re the opposite way around. union allthese queries together- Group by the columns to compare
- Use the
havingclause to filter out the rows where thesumof the source column values added at the start are equal.
This gives a query like:
This is compares the count of rows from each source. Meaning you’ll see duplicates in one but not the other.
Another advantage of this method is it automatically handles null. This is my favourite way to compare tables.
Make a reusable data comparison function
Whichever method you use to compare tables, they can be hard to remember and fiddly to write. It would be easier if you could put the logic in a function. Then pass the tables and columns you want to compare to that.
These enable you to create query templates. At parse time the database can swap in the names you pass for the tables and columns to form the query.
With table SQL macros you can build a template based on your favourite comparison method.
Here’s an example macro using the group by method:
The beauty of macros is you can tailor them to your preferred methods. For example, Stew Ashton has built a more thorough comparison macro.
So far we’ve assumed that you’re comparing plain tables. But everything in SQL is a table! Meaning these approaches also work when comparing query results.
This enables you to use them to solve common challenges.
How to compare complex queries
If you refactor a select statement to make it faster or easier to maintain, it’s important to verify the old and new queries are the same.
While you can plug the whole statements into the queries above, this leads to large, unwieldy SQL.
You can simplify this by placing the queries in views. This enables you use to them as regular tables. Use the views in the queries above to find any differences:
How to find recent row changes
When you investigate data errors or want to undo mistakes by users you want to see what’s changed recently.
Using Flashback Query, you can view data as it was in the past. So to find the delta, compare a table now to how it existed at a known good time in the past.
How to compare rows and show the column differences
Rows for given keys may exist in both data sets with different values for a few columns. In these cases you’d like to see these column differences.
If the tables have many columns, these can be hard to spot. Returning a row for each column that’s different makes these clearer.
To do this:
- First convert the columns into rows with
unpivot. - Use your favourite method above to find the differences
Ensure you exclude the primary and/or unique keys from the unpivot list. Without this you won’t know which row the different columns are from!
Here’s an example:
See these in action
Here’s the recording of my Ask TOM Office Hours session on comparing tables. This shows the methods above in action. Watch to the end to see how the performance of these techniques compare.
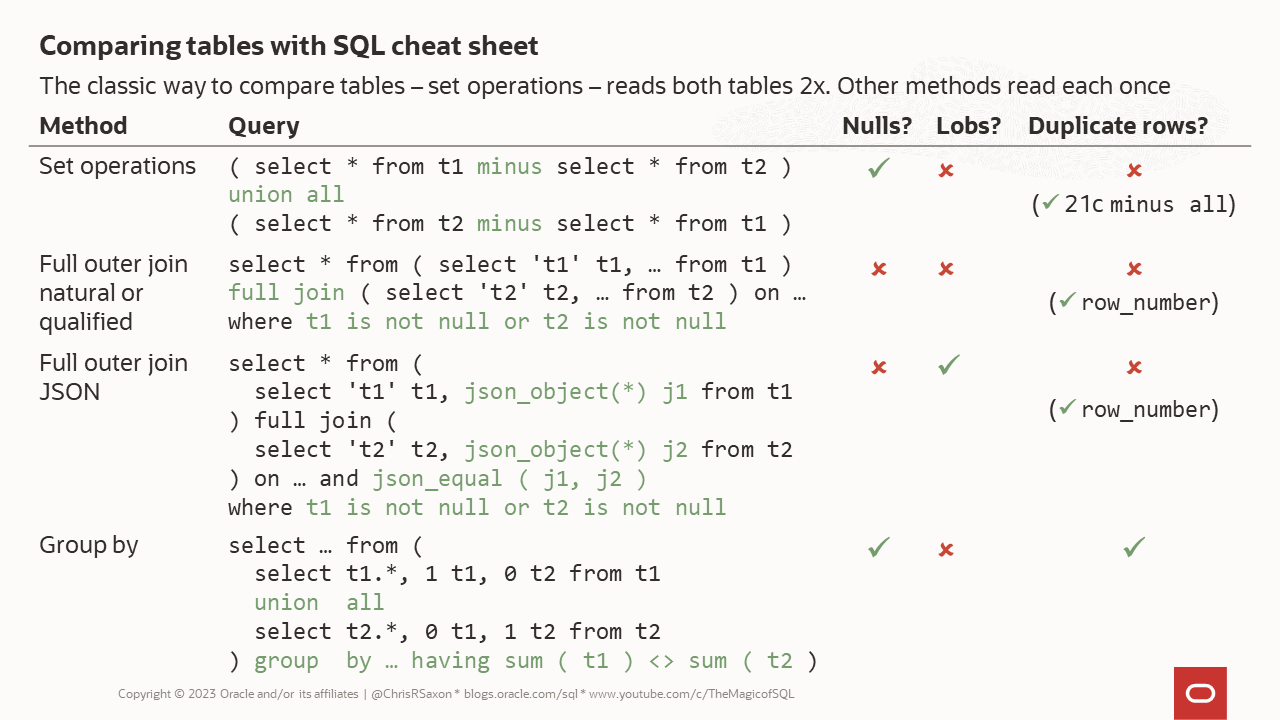
Table comparison cheat sheet
Here’s a summary of the different methods in this post. Other ways exist, for example the dbms_comparison package.
Setup scripts
Create these tables to run the examples above. To run it interactively in the browser, get the scripts on Live SQL.
Want to practice your SQL skills? Play SQuizL, a Wordle-style guess the SQL statement challenge.
UPDATE 26 Oct 2023: Added recording of the Office Hours session on this
UPDATE 15 Apr 2025: Changed Live SQL link to new platform
