Indexes. They’re one of the most powerful and misunderstood aspects of SQL performance. In this post we’ll look at the purpose of an index, how to create and choose choose your index type. Then finish with a discussion of how to decide what to index and how to see if it’s useful.
Why Index?
Database tables can get big. Stupendously, colossally big. For example the Large Hadron Collider at CERN generates 10 TB of summary data per day.
As I discuss in this video, scanning through millions, billions or trillions of rows to return just two or three is a huge waste. Waste an index can help you avoid:
An index stores the values in the indexed column(s). And for each value the locations of the rows that have it. Just like the index at the back of a book. This enables you to hone in on just the data that you’re interested in.
They’re most effective when they enable you to find a “few” rows. So if you have a query that fetches a handful of rows, there’s a good chance you’ll want it to use an index. The first thing you need to do is create it!
How to Create an Index
Creating an index is easy. All you need to do is identify which column(s) you want to index and give it a name!
create index <index_name> on <table_name> ( <column1>, <column2>, … );
So if you want to index the color column of your toys table and call it toys_color_i, the SQL is:
create index toys_color_i on toys ( color );
Simple, right?
But, as always, there’s more to it than that. You can place many columns in the same index. For example, you could also include the type of the toys in the index like so:
create index toys_color_type_i on toys ( color, type );
This is known as a composite or compound index. Which order you place columns in your index has a big effect on whether the optimizer will use it. We’ll discuss the ins and outs of this later.
But first, let’s delve into the different types of indexes available in Oracle Database.
How to Choose the Index Type
Oracle Database offers many different types of index to improve your SQL. One of the key decisions you need to make is whether to go with a bitmap or B-tree index.
B-tree vs. Bitmap

By default indexes are B-tree. These are balanced. This means that all the leaf nodes are at the same depth in the tree. So it’s the same amount of work (O(log n)) to access any value.
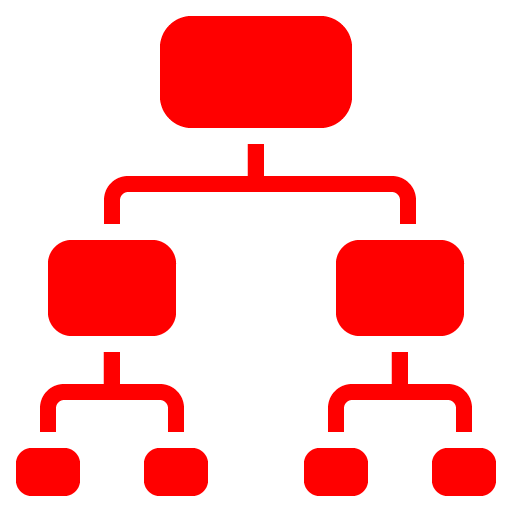
Each leaf index entry points to exactly one row.
Bitmaps are different. As with B-trees, they store the indexed values. But instead of one row per entry, the database associates each value with a range of rowids. It then has a series of ones and zeros to show whether each row in the range has the value (1) or not (0).
Value Start Rowid End Rowid Bitmap VAL1 AAAA ZZZZZ 001000000... VAL2 AAAA ZZZZZ 110000000... VAL3 AAAA ZZZZZ 000111100... ...
Note that the start and end rowid ranges cover all the rows in the table. But large tables may have to split the rows into several ranges. So each indexed value has many entries.
This brings about a key difference between bitmaps and B-trees:
Rows where all the indexed values are null are NOT included in a B-tree. But they are in a bitmap! So the optimizer can use a bitmap to answer queries like:
where indexed_column is null;
But normally it won’t for a B-tree. You can get around this with B-trees by adding a constant to the end of an index. This makes the following composite index:
create index enable_for_is_null_i on tab ( indexed_column, 1 );
Another benefit of bitmaps is it’s easy to compress all those ones and zeros. So a bitmap index is typically smaller than the same B-tree index.
For example, using a table of Olympic medal winners. Creating indexes on edition, sport, medal, event and athlete gives the following sizes (in blocks)
| Column |
B-tree |
Bitmap |
| Edition |
61 |
6 |
| Sport |
83 |
1 |
| Athlete |
117 |
115 |
| Medal |
71 |
3 |
| Event |
111 |
5 |
| Gender |
64 |
1 |
As you can see, in most cases the bitmap indexes are substantially smaller. Though this advantage diminishes as the number of different values in the index increases.
If you’re familiar with Boolean logic truth tables, you may spot another big advantage for bitmaps:
It’s trivial for the optimizer to combine them.
By overlaying the rowid ranges of two indexes, you can find which rows match the where clause in both. Then go to the table for just those rows.
This means indexes which point to a large number of rows can still be useful. Say you want to find all the female gold medal winners in the 2000 Athens Olympics. Your query is:
select * from olym_medals where gender = 'Women' and medal = 'Gold' and edition = 2000;
Each medal is about one third of the rows. And you’d think there’d be roughly a 50/50 split between men and women. Sadly it’s more like 75/25 men to women. But in any case it’s unlikely an index on just gender or medal will be useful. The table has 26 Olympic games. Which is getting close to “few” rows. But there’s no guarantee the optimizer will choose this index.
But combined these conditions will identify roughly:
(1/2) * (1/3) * (1/26) = 1/156 ~ 0.64% of the rows
That’s definitely getting into the realm of “few” rows. So it’s likely the query will benefit from some sort of index.
If you create single column bitmaps, the database can combine using a BITMAP AND like so:
--------------------------------------------------------------- | Id | Operation | Name | --------------------------------------------------------------- | 0 | SELECT STATEMENT | | | 1 | TABLE ACCESS BY INDEX ROWID BATCHED| OLYM_MEDALS | | 2 | BITMAP CONVERSION TO ROWIDS | | | 3 | BITMAP AND | | |* 4 | BITMAP INDEX SINGLE VALUE | OLYM_EDITION_BI | |* 5 | BITMAP INDEX SINGLE VALUE | OLYM_MEDAL_BI | |* 6 | BITMAP INDEX SINGLE VALUE | OLYM_GENDER_BI | ---------------------------------------------------------------
This gives a lot of flexibility. You only need to create single column indexes on your table. If you have conditions against several columns the database will stitch them together!
B-trees don’t have this luxury. You can’t just plonk one on top of the other to find what you’re looking for. While Oracle Database can combine B-trees (via a “bitmap conversion from rowids”), this is relatively expensive. In general to get the same performance as the three bitmaps, you need to place all three columns in a single index. This affects how reusable an index is, which we’ll come to later.
At this point it looks like a slam dunk victory for bitmaps over B-trees.
- Smaller? Check
- More flexible? Check
- Include null values? Check
So you may be wondering:
Why are B-trees the default instead of bitmaps?
Well, bitmap indexes come with a massive drawback:
Killing write concurrency.
They’re one of the few situations in Oracle Database where an insert in one session can block an insert in another. This makes them questionable for most OLTP applications.
Why?
Well, whenever you insert, update or delete table rows, the database has to keep the index in sync. This happens in a B-tree by walking down the tree, changing the leaf entry as needed. You can see how this works with this visualization tool.
But bitmap locks the entire start/end rowid range! So say you add a row with the value RED. Any other inserts which try to add another row with the value RED to the same range are blocked until the first one commits!
This is an even bigger problem with updates. An update from a B-tree is really a delete of the old value and insert of the new one. But with a bitmap Oracle Database has to lock the affected rowid ranges for both the old and new values!
As a result, bitmap indexes are best suited for tables that will only have one process at a time writing to them. This is often the case on reporting tables or data warehouses. But not your typical application.
So if more than one session will change the data in a table at the same time, think carefully before using bitmap indexes.
And of course, there’s the cost reason. Bitmap indexes are an Enterprise Edition only feature. Or, if you like your database in the cloud, an Enterprise Package DBaaS or better.
So, great as bitmaps may be, for most applications B-trees are the way to go!
If you’d like to run these comparisons yourself, use this LiveSQL script. That covers one of the biggest differences in index types. Here are some other common index types.
Function-based Indexes

These are simply indexes where one or more of the columns have a function applied to them. The index stores the result of this calculation. For example:
create index date_at_midnight_i on table ( trunc ( datetime ) );
or
create index upper_names_i on table ( upper ( name ) );
You can use functions in bitmap or B-tree indexes.
Bear in mind if you have a function-based index, to use it the function in your where clause must match the definition in the index exactly(*). So if your index is:
create index dates_i on dates ( trunc (datetime) );
Your where clause must be:
where trunc (datetime) = :some_date
This reduces the reusability of your index. So it’s better to avoid function-based indexes if you can. Instead move the calculation off the column to the variable. Examples include:
Simple formulas
Using standard math, rearrange the formula so there are no functions on the column:
| column + 10 = val | becomes | column = val – 10 |
| column * 100 = val | becomes | column = val / 100 |
Findings rows on a given day
The date data type in Oracle Database always includes the time of day. So to guarantee you have all the rows that fall on a given day, you can normalize the date to midnight. Then compare the result to a date, like so:
trunc( datetime_col ) = :dt
But there is another way to do this. Check that the column is greater than or equal to the variable and strictly less than the variable plus one day:
datetime_col >= :dt and datetime_col < :dt + 1
Changing your SQL like this makes means you can create regular indexes.
Note that the reverse isn’t always true. You can have a normal index on a column. Then apply a function to that column in your where clause. Sticking with the dates example, you can index:
create index date_i on table ( datetime_col );
And a where clause like:
where trunc( datetime_col ) = :dt
And the database can still use it. This is because it can filter the rows in the index. This is often faster than full scanning the table.
*Starting in 11.2.0.2, Oracle Database can use function-based indexes to process queries without the function in the where clause. This happens in a special case where the function preserves the leading part of the indexed values. For example, trunc() or substr().
I still think it’s better to create the regular index. But at least this helps if you must use the function-based index for some reason. For worked examples, head over to LiveSQL.
Unique Indexes

A unique index is a form of constraint. It asserts that you can only store a given value once in a table. When you create a primary key or unique constraint, Oracle Database will automatically create a unique index for you (assuming there isn’t an index already available). In most cases you’ll add the constraint to the table and let the database build the index for you.
But there is one case where you need to manually create the index:
Function-based unique constraints.
You can’t use functions in unique constraints. For example, you might want to build a “dates” table that stores one row for each calendar day. Unfortunately, Oracle Database doesn’t have a “day” data type. Dates always have a time component. To ensure one row per day, you need lock the time to midnight. You apply the trunc() function to do this. But a constraint won’t work:
alter table dates add constraint date_u unique ( trunc ( calendar_date ) );
So you need to resort to a unique function-based index:
create unique index date_ui on dates ( trunc ( calendar_date ) );
Or you can hide the function in a virtual column. Then index that. For example:
alter table dates add cal_date_no_time as ( trunc(calendar_date) ); alter table dates add constraint date_u unique ( cal_date_no_time );
(HT to Stew Ashton for pointing this out).
Note you can’t create unique bitmap indexes.
Descending Indexes
B-tree indexes are ordered data structures. New entries have to go in the correct location, according to the logical order imposed by the columns. By default these sort from small to large.
But you can change this. By specifying desc after the column, Oracle Database sorts the values from large to small.
Usually this makes little difference. The database can walk up or down the index as needed. So it’s rare you’ll want to use them.
But there is a case where they can help. If your query contains “order by descending”, the descending index can avoid a sort operation. The simplest case is where you’re searching a range of values, sorting these descending and another column.
For example, finding the orders for customer_ids in a given range. Return these ids in reverse order. Then sort by sale date:
select * from orders where customer_id between :min_cust_id and :max_cust_id order by customer_id desc, order_datetime;
If you use a regular composite index on ( customer_id, order_datetime ), the plan will look like:
------------------------------------------------- | Id | Operation | Name | ------------------------------------------------- | 0 | SELECT STATEMENT | | | 1 | SORT ORDER BY | | | 2 | TABLE ACCESS BY INDEX ROWID| ORDERS | | 3 | INDEX RANGE SCAN | ORDERS_I | -------------------------------------------------
But create it with ( customer_id desc, order_datetime ) and the sorting step disappears!
------------------------------------------------ | Id | Operation | Name | ------------------------------------------------ | 0 | SELECT STATEMENT | | | 1 | TABLE ACCESS BY INDEX ROWID| ORDERS | | 2 | INDEX RANGE SCAN | ORDERS_I | ------------------------------------------------
This could be a big time saver if the sort is “expensive”.
JSON Search Indexes

Storing data as JSON documents is (sadly) becoming more common. All the attributes are part of the document, instead of a column in their own right. This makes indexing the values tricky. So searching for documents that have specific values can be agonizingly slow. You can overcome this by creating function-based indexes on the attributes you search.
For example, say you store the Olympic data as JSON. You regularly look for which medals an athlete’s won. You can index this like so:
create index olym_athlete_json_i on olym_medals_json ( json_value ( jdoc, '$.athlete' ) );
And your queries with that json_value expression should get a nice boost.
But you may want to do ad-hoc searching of the JSON, looking for any values in the documents. To help with this you can create an index specifically for JSON data from Oracle Database 12.2. It’s easy to do:
create search index olym_medals_json_i on olym_medals_json ( jdoc ) for json;
The database can then use this for any SQL using the various JSON functions. You can read more about this in the JSON Developer’s indexes guide or try these out over on LiveSQL.
If you’re wondering how the JSON search index works, underneath the covers it uses Oracle Text. This brings us nicely to:
Oracle Text Indexes
Maybe you have large bodies of free text in your database. The kind that you want to do fuzzy searches, semantic analysis on and so on. For these you can create a Text Index. These come in three flavors:
- Context
- Category
- Rule
Using these indexes is a huge topic in itself. So if you want to do this kind of search, I recommend starting with the Text Developer’s Guide.
Advanced Index Types
There are a couple of other index types available. You’ll probably never need to create these, but I’ve included them just in case 😉
Application Domain Indexes
From time-to-time, you want create a specialized index, customized to your data. Here you specify how the database indexes and stores your data.
If you want to do this, check out the Data Cartridge Developer’s Guide.
Reverse Key Indexes
If you have an index on a column that stores ever-increasing values, all the new entries must go on the right hand edge of the index. Sequence based primary keys and insert timestamps are common examples.
If you have a large number of sessions doing this at the same time, this can lead to problems. They all need to access the same index block to add their data. As only one can change it at a time, this can lead to contention. A term called “hot blocks”.
Reverse key indexes avoid this problem by flipping the byte order of the indexed values. So instead of storing 12345, you’re effectively storing 54321. The net effect of this is it spreads new rows throughout the index.
It’s rare you’ll need to do this. And because the entries are not stored in their natural sort order, you can only use these indexes for equality queries. So it’s often better to solve this problem in other ways, such as hash partitioning the index.
OK, so that covers the different types of index available. But we still haven’t got to the bottom of which indexes you should create for your application. It’s time to figure out:
How to Decide What to Index
Oracle Autonomous Database can analyze your workload and – via the magic of Automatic Indexing – create indexes for you.
First up, it’s important to know there’s no “right” answer here (though there are some wrong ones ;). It’s likely you’ll have many different queries against a table. If you create an index tailored to each one, you’ll end up with a mass of indexes. This is a problem because each extra index adds storage and data maintenance overheads.
So for each query you need to make a compromise between making it as fast as possible and overall system impact. Everything is a trade-off!
The most important thing to remember is that for the database to use an index, the column(s) must be in your query! So if a column never appears in your queries, it’s not worth indexing. With a couple of caveats:
- Unique indexes are really constraints. So you may need these to ensure data quality. Even if you don’t query them columns themselves.
- You should index any foreign key columns where you delete from the parent table or update its primary key.
Beyond this, an index is most effective when its columns appear in your where clause to locate “few” rows in the table. I give a brief overview of what “few” means in this video series:
A key point is it’s not so much about how many rows you get, but how many database blocks you access. Generally an index is useful when it enables the database to touch fewer blocks than a full table scan reads. A query may return “lots” of rows, yet access “few” database blocks.
This typically happens when logically sorting the rows on the query column(s) closely matches the physical order database stores them in. Indexes store the values in this logical order. So you normally want to use indexes where this happens. The clustering factor is a measure of how closely these logical and physical orders match. The lower this value is, the more effective the index is likely to be. And thus the optimizer to use it.
But contrary to popular belief, you don’t have to have the indexed column(s) in your where clause. For example, if you have a query like this:
select indexed_col from table
Oracle Database can full scan the index instead of the table. Which is good because indexes are usually smaller than the table they’re on. But remember: nulls are excluded from B-trees. So it can only use these if you have a not null constraint on the column!
If your SQL only ever uses one column of a table in the join and where clauses then you can have single column indexes and be done.
But the real world is more complicated than that. Chances are you have relatively few basic queries like:
select * from tab where col = 'value';
And a whole truckload with joins and filters on many columns, like:
select * from tab1 join tab2 on t1.col = t2.col join tab3 on t2.col2 = t3.col1 where t1.other_col = 3 and t3.yet_another_col order by t1.something_else;
As discussed earlier, if you’re using bitmaps you can create single column indexes. And leave the optimizer to combine them as needed. But with B-trees this may not happen. And it’s more work when it does.
So it’s likely you’re going to want some composite indexes. This means you need to think about which order to place columns in the index.
Why?
Because Oracle Database reads an index starting with its leftmost (“first”) column. Then it goes onto the second, third, etc. So if you have an index on:
create index i on tab ( col1, col2, col3 );
And your where clause is:
where col3 = 'value'
To use the index the database either has to wade through all the values in col1 and col2. Or, more likely, read the whole thing to find those matching your conditions.
Bearing this in mind, here’s a few guidelines for composite indexes:
- Columns with equality conditions (=) should go first in the index
- Those with range conditions (<, >=, between, etc.) should go towards the end
- Columns only in the select or order by clauses should go last
To put this into context, let’s return to the Olympic medals table and investigate some queries.
Say you’ve got three common queries on this data:
select listagg(athlete,',') within group (order by athlete) from olym_medals where medal = 'Gold'; select listagg(athlete,',') within group (order by athlete) from olym_medals where event = '100m'; select listagg(athlete,',') within group (order by athlete) from olym_medals where medal = 'Gold' and event = '100m';
What do you index?
With just three values for medal and an even spread between them an index on this is unlikely to help. Queries on event return few rows. So this is definitely worth indexing.
But what about the queries against both columns?
Should you index:
( event, medal )
OR
( medal, event )
For the query searching both columns it will make little difference. Both options will only hit the table for the rows matching the where clause.
But the order affects which of the other queries will use it.
Remember Oracle Database reads index columns from left to right. So if you index (medal, event), your query looking for all the 100m medal winners must first read the medal values.
Normally the optimizer won’t do this. But in cases where there are few values in the first column, it can bypass it in what’s called an index skip scan.
There are only three different medals available. So this is few enough to enable a skip scan. Unfortunately this is more work than when event is first. And, as discussed, SQL looking for the winners of a particular medal are unlikely to use an index anyway. So an index with medal first probably isn’t worth it.
Using ( event, medal ) has the advantage of a more targeted index compared to just ( event ). And it gives a tiny reduction to the work the query on both columns compared to an index on event alone.
So you’ve got a choice. Do you index just event, or event and medal?
The index on both columns reduces the work for queries on event and medal slightly.
But is it worth having two indexes for this saving?
As well as consuming more disk space, adding to DML overheads, etc. there’s another problem with the composite index. Compare the clustering factor for the indexes on event:
| INDEX_NAME |
CLUSTERING_FACTOR |
| OLYM_EVENT_I |
916 |
| OLYM_EVENT_MEDAL_I |
2219 |
Notice that the clustering factor for event_medal is nearly 3 times higher than for medal!
So what’s so bad about that?
The clustering factor is one of the key drivers determining how “attractive” an index is. The higher it is, the less likely the optimizer is to choose it. If you’re unlucky this could be enough to make the optimizer think a full table scan is cheaper…
Sure, if you really need the SQL looking for the gold winners in given events to be ultra speedy, go for the composite index. But in this case it may be better to go one step further. Add athlete to the index too. That way Oracle Database can answer the query by accessing just the index. Avoiding the table access can save you some work. In most other cases I’d stick with the single column event index.
Let’s take another example. Say your dominant query is to find the winners for given events in a particular year:
select listagg(athlete,',') within group (order by athlete) from olym_medals where edition = 2000 and event = '100m';
In most cases this will return three or six rows. Even with those pesky team events with lots of athletes getting medals you’re looking at around 100 rows tops. So a composite index is a good idea.
But which order to you put the columns in?!
If you have no other queries on these columns, it seems to make no difference.
But there is another dimension to consider:
Index compression

You can compress an index. This effectively removes duplicates in its leading column(s). Provided there are “many” rows for each value, this can shrink the size of an index drastically. This saves disk space. And means you have less data to scan when querying. This can reduce the work your SQL does. The uncompressed index sizes (in blocks) are:
| INDEX_NAME |
LEAF_BLOCKS |
| OLYM_EVENT_YEAR_I |
127 |
| OLYM_YEAR_EVENT_I |
127 |
So which column should you put first and compress? Year or event?
There’s many more rows for each year than each event. So this should go first, right?
Let’s see. Rebuilding an index with “compress N” compresses its first N columns. So to compact the leading column, you run:
alter index olym_event_year_i rebuild compress 1; alter index olym_year_event_i rebuild compress 1;
Which brings the index sizes down to:
| INDEX_NAME |
LEAF_BLOCKS |
| OLYM_EVENT_YEAR_I |
64 |
| OLYM_YEAR_EVENT_I |
111 |
Whoa!
Placing event first nearly halves the size of the index compared to year. Even though on average there are three times as many rows per year as per event.
So why’s that?
It’s all to do with the length of the values.
Some of the events have lengthy descriptions, such as the weightlifting “75 – 82.5kg, one-two hand 3 e. (light-heavyweight)”. This leads to an average event length of 15 bytes. Nearly four times more than the 4 bytes needed to store the years.
So you need to look at how compressible the values are, not just how many you have.
Of course, in this case you can go further and compress both columns of both indexes with
alter index olym_event_year_i rebuild compress 2; alter index olym_year_event_i rebuild compress 2;
And they’re back down to the same size:
| INDEX_NAME |
LEAF_BLOCKS |
| OLYM_EVENT_YEAR_I |
59 |
| OLYM_YEAR_EVENT_I |
59 |
So it’s a toss-up for which column to place first. Inspect your other SQL to see if this pushes you to place one or the other first.
So far we’ve only talked about equality checks. Often in SQL you’re searching for a range of values in one of the columns. For example, finding all the 100m medal winners after 2000:
select * from olym_medals where event = '100m' and edition > 2000;
In this case it’s better to make an index on (event, edition) as opposed to the other way around. This is because the database can first identify only the entries for the 100m. Then filter those for Olympic Games this century. As opposed to finding all the post-2000 entries. Then filtering those to find the 100m winners.
Remember: the recommendations for column order here are specific to this data set. What’s more important to understand is the process and the questions you need to ask. Such as:
- Which column(s) appear in the where clause of the most queries?
- Do the conditions on these columns return a small enough set of rows and access few enough blocks for an index to be useful?
- Which columns in the index are most compressible?
- Which SQL statements do you want to prioritize the performance of?
So you’ve gone out and created your indexes. And you want to assess whether they’re helping or not. So that leaves an important question:
How Do I Know Which Indexes a Query Used?
To figure this out, you need to look at the query’s execution plan. This shows you all the steps the database took to process the query. If the optimizer chose an index it will appear as a step in the plan.
For example, this plan shows a query using the index orders_i to access the orders table:
------------------------------------------------ | Id | Operation | Name | ------------------------------------------------ | 0 | SELECT STATEMENT | | | 1 | TABLE ACCESS BY INDEX ROWID| ORDERS | | 2 | INDEX RANGE SCAN | ORDERS_I | ------------------------------------------------
At this point you may discover the optimizer didn’t choose your index. You’re certain it’s the “right” index and the SQL should use it. So you may be wondering:
How Can I Force a SQL Statement to Use an Index?
I’m sure some of you are now tempted to reach for the index hint. This instructs the database to use the index. This can be useful for seeing if it really is more efficient than the plan the optimizer chose instead.
But I strongly discourage you from using these in your production SQL. Although they’re called hints, they’re really directives. The database has to use the hinted index if it’s able to. Your data may change, making the index slower than a full table scan. But the query is still forced to use it. This can create maintenance problems for you in the future.
But what if your index really did enable a faster plan? You want some way to force or encourage the database down the right path, right?
In this case I’d point you towards SQL Plan Management instead. Using SQL Baselines ensures queries use the plan you want, with an in built process for moving to better plans if one is available.
Closing Words
A final piece of advice:

Keep the number of indexes you create to a minimum.
It’s hard to prove that your application doesn’t need an existing index. The reasons for creating rarely used indexes tend to get forgotten over time. People will come and go on your team. And no one will know why Dave made that five column function-based monstrosity. You don’t know if it’s never used or critical for year-end reporting and nothing else.
So once you create an index in production, dropping it is risky. This can lead to the bizarre case where a table has more indexes than columns!
Advances such as invisible indexes in 11.1 and better index monitoring in 12.2 help reduce this risk. But it never fully goes away. If torn between creating two “perfect” indexes and one “good enough” index, I’d normally go with the one that’s good enough.
After all, if it turns out you did need a more targeted index I’m sure your customers will be quick to tell you how slow your app is!
But above all, test!
Want to Know More?
Phew! That was a lot. And it only scratches the surface of indexes!
Indexing is a large and important topic. If you want to learn more about these, I recommend reading the following:
- Richard Foote’s blog
- Use the Index Luke a vendor agnostic description of indexes from Markus Winand.
- To know more about how the cost-based optimizer works, check out Jonathan Lewis’ blog or books on this topic. The optimizer blog also gives great insight into how various parts of a plan work.
- And of course you can always put your questions to us over on Ask TOM
- Learn more about SQL Performance Tuning in Databases for Developers: Performance
UPDATED 14 Aug 2017: Clarified section about descending indexes refers to a composite index (thanks to Jonathan Lewis) and some minor formatting edits.
UPDATED 16 Aug 2017: Added virtual column note for function-based unique indexes.
UPDATED 28 Sep 2017: Correction: “The B stands for balanced”: the B in B-tree doesn’t stand for anything! But these indexes are balanced.
UPDATED 18 Apr 2019: Formatting enhancements
UPDATED 9 Jul 2020: Embedded video and added note about Automatic Indexing
UPDATED 27 Jul 2020: Added Databases for Developers link
UPDATED 10 Jan 2023: Fixing video embed
UPDATED 9 May 2024: Fixing typos
UPDATED 15 Apr 2025: Changing Live SQL links to new platform
