In all the LDoms workshops I’ve been doing in the past years, I’ve always been cautioning customers to keep their expectations within reasonable limits when it comes to virtual IO. And I’ll not stop doing that today. Virtual IO will always come at a certain cost, because of the additional work necessary to translate physical IOs to the virtual world. Until we invent time travel, this will always need some additional time to be done. But there’s some good news about this, too:
First, in many cases the overhead involved in virtualizing IO isn’t that much – the LDom implementation is very efficient. And in many of these many cases, it doesn’t hurt. Often, because the workload involved doesn’t care and virtual IO is fast enough.
Second, there are good ways to configure virtual IO, and not so good ways. If you stick to the good ways (which I previously discussed here), you’ll increase the number of cases where virtual IO is more than just good enough.
But of course, there are always those other cases where it just isn’t. But there’s more good news, too:
For virtualized network, we’ve introduced a new implementation utilizing large segment offload (LSO) and some other techniques to increase throughput and reduce latency to a point where virtual networking has gone away as a reason for performance issues. This was in LDoms release 3.1. Now is when we introduce a similar enhancement for virtual disk.
When we talk about disk IO and performance, the most important configuration best practice is to spread IO load to multiple LUNs. This has always been the case, long before we started to even think about virtualization. The reason for this is the limited number of IOPS a single LUN will deliver. Whether that LUN is a single physical disk or a volume in a more sophisticated disk array doesn’t matter. IOPS delivered by one LUN are limited, and IOs will queue up in this LUN’s queue in a very sequential manner. A single physical disk might deliver 150 IOPS, perhaps 300 IOPS. A SAN LUN with a strong array in the backend might deliver 5000 IOPS or a little more. But that isn’t enough, and has never been. Disk striping of any kind was invented to solve this problem. And virtualization of both servers and storage doesn’t change the overall picture. Which means that in LDoms, the best practice has always been to configure several LUNs, which means several vdisks, into a single guest system. This often provided the required IO performance, but there were quite a few cases where this just wasn’t good enough and people had to move back to physical IO. Of course, there are several ways to provide physical IO and still virtualize using LDoms, but the situation was not ideal.
With the release of Solaris 11.1 SRU 19 (and a Solaris 10 patch shortly afterwards) we are introducing a new implementation of the vdisk/vds software stack, which significantly improves both latency and throughput of virtual disk IO. The improvement can best be seen in the graphs below.
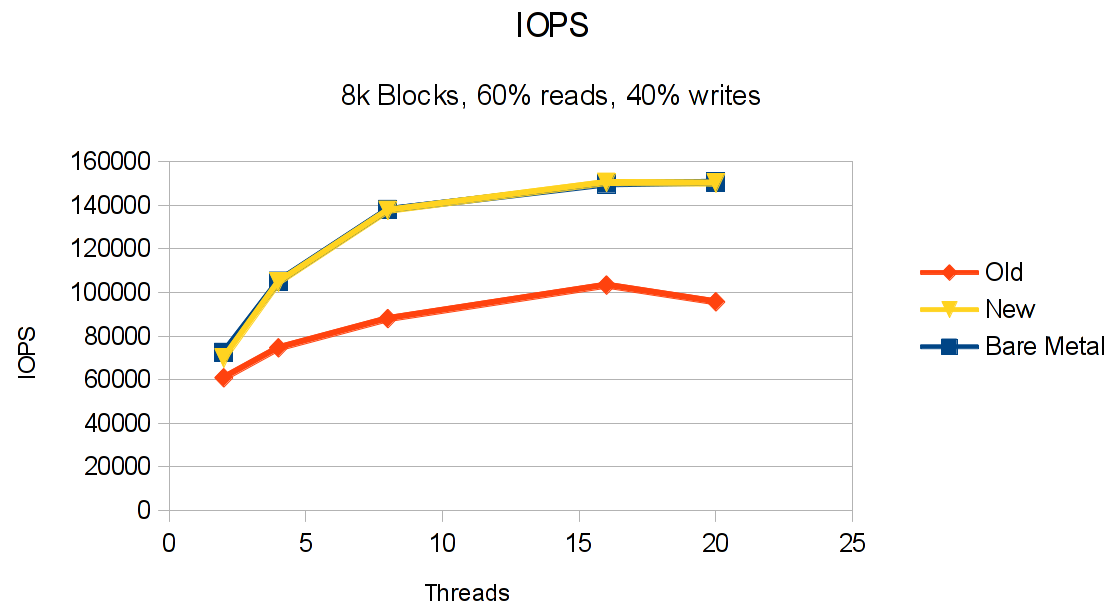
This first graph shows the overall number of IOPS during a performance test, comparing bare metal with the old and the new vdisk implementation. As you can see, the new implementation delivers essentially the same performance as bare metal, with a variation that might as well be statistical deviation. Note that these tests were run on a total of 28 SAN LUNs, so please don’t expect a single LUN to deliver 150k IOPS anytime soon 🙂 The improvement over the old implementation is significant, with differences of up to 55% in some cases. Again, note that running only a single stream of IOs against a single LUN will not show as much of an improvement as running multiple streams (denoted as threads in the graphs). This is due to the fact that parts of the new implementation have focused on de-serializing the IO infrastructure, something you’ll not notice if you run single threaded IO streams. But then, most IO hungry applications issue multiple IOs. Likewise, if your storage backend can’t provide this kind of performance (perhaps because you’re testing on a single, internal disk?), don’t expect much change!
So we know that throughput has been fixed (with 150k IOPS and 1.1 GB/sec virtual IO in this test, I believe I can safely say so). But what about IO latency? This next graphs shows a similar improvement here:
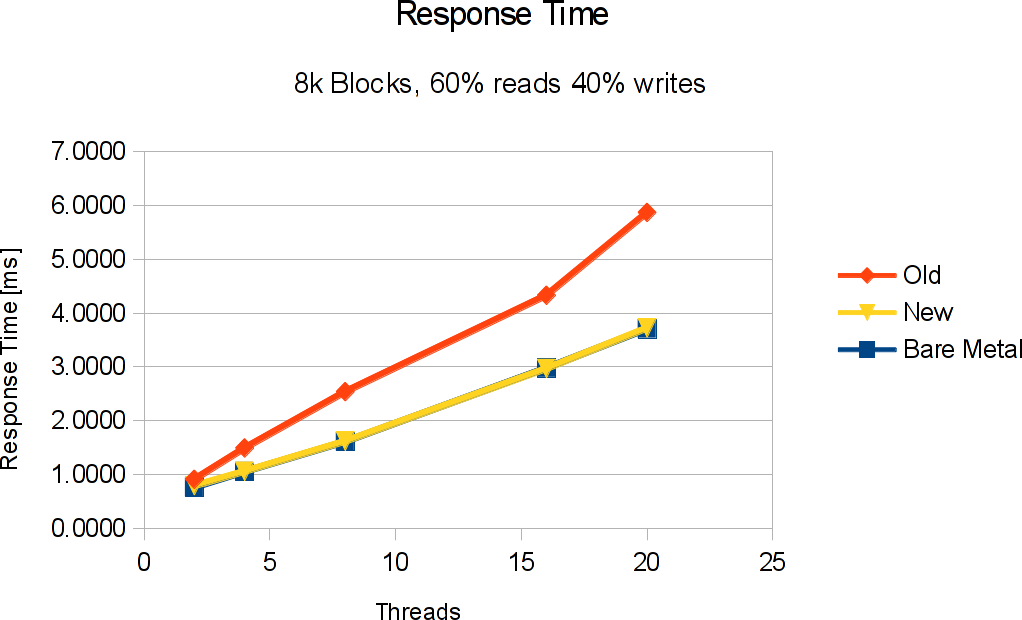
Again, response time (or service time) with the new implementation is very similar to what you get from bare metal. The maximum difference is in the 2 thread case with less than 4% difference between virtual IO and bare metal. Close enough to actually start talking about zero overhead IO (at least as far as the IO performance is concerned). Talking about overhead: I sometimes call the overhead involved in virtualization the “Virtualization Tax” – the resources you invest in virtualization itself, or, in other words, the performance (or response time) you lose because of virtualization. In the case of LDoms disk IO, we’ve just seen a signifcant reduction in virtualization taxes:
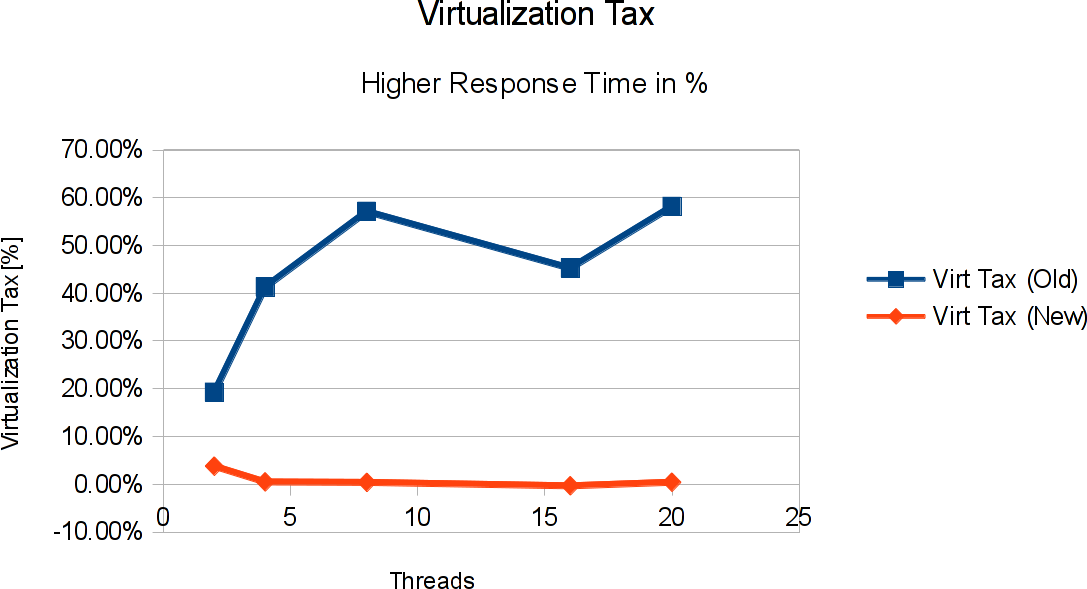
The last graph shows how much higher the response time for virtual disk IO was with the old implementation, and how much of that we’ve been given back by this charming piece of engineering in the new implementation. Where we paid up to 55% of virtualization tax before, we’re now down to 4% or less. A big “Thank you!” to engineering!
Of course, there’s always a little disclaimer involved: Your milage will vary. The results I show here were obtained on 28 LUNs coming from some kind of FC infrastructure. The tests were done using vdbench in a read/write mix of 60%/40% running from 2 to 20 threads doing random IO. While this is quite a challenging load for any IO subsystem and represents the load pattern that showed the highest virtualization tax with the old implementation, this still means that real world benefits from this new implementation might not achieve the same improvements. Although I am very optimistic that they will be similar.
In conclusion, with the new, improved virtual networking and virtual disk IO that are now available, the range of applications that can safely be run on fully virtualized IO has been expanded significantly. This is in line with the expectations I often find in customer workshops, where high end performance is naturally expected from SPARC systems under all circumstances.
Before I close, here’s how to use this new implementation:
- Update to Solaris 11.1 SRU 19 in
- all guest domains that want to use the new implementation.
- all IO domains that provide virtual disks to these guests
- This will also update LDoms Manager to 3.1.1
- If only one in the pair (guest|IO domain) is updated, virtual IO will continue to work using the old implementation.
- A patch for Solaris 10 will be available shortly.
Update 2014-06-16: Patch 150400-13 has now been released for Solaris 10. See the Readme for details.
