There’s a question I get asked over and over again: How do you measure single thread performance?
As much as I’d like, the answer isn’t as easy as the question. And it’s a little longer, too.
Let’s start with a definition of single thread performance, because even that isn’t as clear as one would think. In this blog,
single thread performance is the amount of work completed by some software that runs as a single stream of instructions in a certain amount of time.
All of this, of course, is used to evaluate the performance (yet another use of that term!) of a computer system, or sometimes a component of a computer system with regards to the single thread performance one can expect.
But enough of this, what we really want to know is what possibilities we have to measure, and of course compare, single thread performance.
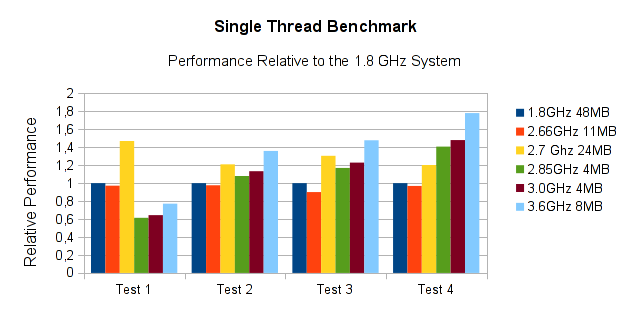
The first thing that comes to mind is a little test program. Something that you know is single threaded and takes a while. Depending on what you usually do, that might be a shell script counting from 1 to 1 million, or an sql loop creating fibonacci numbers, or a little program to create cryptographic hashes, etc. But does that really do what we want – deliver a reliable idea of the general single thread performance of a system? After all, the requirements of all these micro-benchmarks are very different. Some favor large caches to hide memory latency. Some require huge memory bandwidth, yet others simply scale with CPU clockrate. So how would we evaluate a systems’ single thread performance for these very different requirements? Let’s look at an example. The graph below shows the performance of several tests in a little test suite I habitually run on any SPARC system I get my hands on. It’s not important what it actually does. I know all the tests are CPU bound and single threaded.
There are a few things I’d like you to note here:
- Test 1 seems to be very cache friendly, as the three CPUs with caches larger than 8MB clearly win. It also seems that this test favors cache over clock rate, as the two results with 2.66 and 1.8 GHz are very close, with the 1.8 GHz system in the lead.
- All the other tests seem to perform roughly along the clockrate of the CPU, with the 3.6GHz system in the lead.
- However, there’s not a fixed ratio between clockrate and performance. In test 1, all results are very close, while there are more significant differences for example in test 4.
What all this leads to is this: Single thread performance depends on the application and the data set – there is no “one size fits all” result. This should not be a surprise, it’s essentially very much the same in any other benchmarking exercise. But in single thread performance, this is more important, because the differences can be larger. Look at the chart above once more. According to test 1, the 2.66GHz system would be about 1/3 faster than the 2.85GHz system, and about as fast as the 1.8 GHz one. According to tests 2 and 3, the 1.8 GHz system would be clearly faster than the 2.66 GHz one, and all the others would beat either of them. The trouble with this is, that you don’t really know which one you hit with whatever your favorite test program happens to be. So whatever your results are, using them for performance projections is difficult at best.
So let’s look at the “official” benchmarks. The only one of any relevance that still covers single thread performance is SPEC CPU2006. For the sake of simplicity, I’ll just focus on CINT2006. There are two variants of CINT2006, the single threaded SPECint_2006 and the throughput version SPECint_rate2006. Since we’re looking for single thread performance, SPECint_2006 is the natural selection. Unfortunately, there are two problems here:
- SPECint_2006 isn’t truely single threaded according to the definitions above. Some of the benchmarks used in SPECint_2006 can be nicely parallelized by modern compilers. This is allowed by the benchmark rules.
- Not all vendors publish SPECint_2006. There are numerous publications of SPECint_rate2006, but far less publish the single threaded version along with the parallel run.
These two issues look like SPEC CPU2006 wouldn’t be a solution to our question either. However, many people believe they can overcome this limitation. They argue somewhere along these lines:
“SPECint_rate2006 is just done by running multiple copies of SPECint_2006 on a larger system. So if I want to know the single thread performance of that system, all I need to do is divide the SPECint_rate2006 result by the number of CPU threads, or perhaps by the number of program copies documented in the result, to calculate the single threaded result.”
Sounds easy. But does it work? Let’s check it in a few examples where we’re lucky enough to find both SPECint_2006 and SPECint_rate2006 results. To keep it a little more simple, I’ll do this with the perlbench sub-benchmark only, not the composite result. If you like, check it with any other sub-benchmark…
| System | SPECint_2006 perlbench | SPECint_rate2006 perlbench | Number of copies | SPECint_rate2006 perlbench / Number of copies | Accuracy of single thread estimate |
| M3000 | 16.4 | 83.5 | 8 | 10.4 | 64% |
| Power780 4.14 GHz | 28.1 | 1120 | 128 | 8.75 | 31% |
| Sun Fire X4-2 (Intel Xeon E5-2697 v2 2.7GHz) |
41 |
894 |
96 | 9.3 |
23% |
All these results are from spec.org as of March 17, 2014. Each quoted result links to the full result on spec.org.
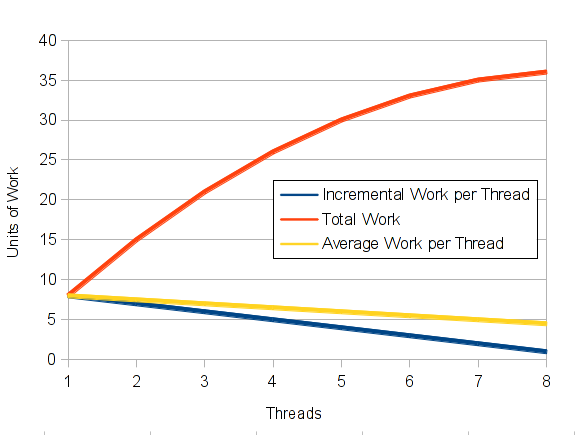 As we can clearly see, estimating single thread performance with this simple scheme will not work. Why not? Because today’s CPUs are all multi-threading CPUs. Not only do they all have multiple cores that share L2 or L3 caches as well as memory bandwidth. They also have multiple threads running off of each core. The rationale behind these threads is increasing core utilization: A single thread would not be able to fully utilize todays fast running cores, mostly because of memory latencies, which have not kept up with CPU clock rate improvements. This means that a second, third or fourth thread will be able to do additional work without significantly interfering with the other active threads on that core. But of course at one point, the core is mostly busy, so the incremental work done by additional threads will decrease with the number of busy threads. The graph at the right shows an idealized plot of this. Depending on the characteristic of the workload, the optimal number of threads running on a single core can vary between 1 and 8. This is normal, and in everyday operation, this provides great throughput for applications, although in some cases it might present a challenge for capacity planning. In the case of a benchmark configuration, however, the goal (in a throughput benchmark like SPECint_rate2006) is to maximize throughput. So even if the last additional copy of the application will only add another 2% on top of the previous result, this improvement is welcome. Throughput benchmarks like SPECint_rate2006 or SAP SD 2 Tier are optimized for maximum throughput.
As we can clearly see, estimating single thread performance with this simple scheme will not work. Why not? Because today’s CPUs are all multi-threading CPUs. Not only do they all have multiple cores that share L2 or L3 caches as well as memory bandwidth. They also have multiple threads running off of each core. The rationale behind these threads is increasing core utilization: A single thread would not be able to fully utilize todays fast running cores, mostly because of memory latencies, which have not kept up with CPU clock rate improvements. This means that a second, third or fourth thread will be able to do additional work without significantly interfering with the other active threads on that core. But of course at one point, the core is mostly busy, so the incremental work done by additional threads will decrease with the number of busy threads. The graph at the right shows an idealized plot of this. Depending on the characteristic of the workload, the optimal number of threads running on a single core can vary between 1 and 8. This is normal, and in everyday operation, this provides great throughput for applications, although in some cases it might present a challenge for capacity planning. In the case of a benchmark configuration, however, the goal (in a throughput benchmark like SPECint_rate2006) is to maximize throughput. So even if the last additional copy of the application will only add another 2% on top of the previous result, this improvement is welcome. Throughput benchmarks like SPECint_rate2006 or SAP SD 2 Tier are optimized for maximum throughput.
This necessarily means that the average performance per thread is lower than the potential maximum performance per thread. And that is why we can not use the per thread average of a throughput benchmark to establish single thread performance.
But what other solution is there? Let’s take a step back and look at what we really want to know. Single thread performance isn’t a value in it’s own. It serves a purpose. In most cases, that purpose is application response time – application response time that meets or exceeds our expectations. Fortunately, there’s a benchmark that addresses just that: SPECjbb2013. Now, I know that this benchmark specifically focuses on application server behaviour. Which is very different from say a datawarehouse. Nevertheless, it will give us a reliable hint about single thread performance and, more importantly, something that we can use to help us understand the single thread performance of different systems (provided there are published results…)
So let’s have a short look at SPECjbb2013 and how it might be helpful in providing an answer to our question:
SPECjbb2013 provides two performance metrics: max-jOPS and critical-jOPS. max-jOPS is a pure throughput metric, not interesting to this discussion. critical-jOPS, on the other hand, is “a metric that measures critical throughput under service level
agreements (SLAs) specifying response times ranging from 10ms to 500ms.” (quote from SPEC’s benchmark description.) As such, it puts a lot of stress both on the system and on the benchmarking teams. They need to optimize a system for the very realistic requirement to deliver low latency responses and yet deliver maximum throughput at the same time. So how does this help in our quest to measure and compare single thread performance? Well, let’s assume we have two systems with comparable configuration and price. System A delivers 10000 max-jOPS and 5000 critical-jOPS. System B delivers 7500 max-jOPS and 6000 critical-jOPS. So System A delivers more throughput, but only if we ignore response time. System B, on the other hand, didn’t do as well in overall throughput, but delivered more critical-jOPS than System A. This is a hint for us that the single thread performance of system B is better than that of system A – giving us more throughput under response time constraints. Now, this too, isn’t the great, “one size fit’s all” single thread performance answer you might have been looking for. You will definitely not get a “System A’s single thread perfomance is 3x better than system B’s.” Simply because throughput and the way a system scales and deals with highly scalable workloads plays a strong role in this benchmark. But it’s a very realistic scenario which will give us some good hints, helping us set the right expectations about single thread performance of different machines. As with every benchmark, conclusions are specific to the application, data set, testing circumstances, etc, but SPECjbb2013 is a good example of how we can asses single thread performance.
Before I close, one more note about SPECjbb2013: Benchmark teams from different vendors are just starting to understand this benchmark. Seeing that there are 3 submissions for the Oracle SPARC T5-2 with critical-jOPS ranging from 23334 to 43963 it should be obvious that results need to be compared carefully to get apples to apples comparisons. The major difference between these results is the version of Java that was used. The first score was obtained using JDK 7u17 while the just announced Java 8 JDK delivers a 1.89x higher score! This not only shows the software release needs to be taken into account when comparing results, but it can also be highly beneficial to consider using a more recent version. Fortunately, submissions are starting to come in for this benchmark, so finding a set to compare should be easier going forward.
Thanks for reading this very long post! For those still not fed up, here’s some additional reading:
- SPECcpu2006
- SPECjbb2013
- How the SPARC T4 Processor Optimizes Throughput Capacity: A Case Study by Ruud van der Pas
Thanks to Ruud van der Pas and Patrick McGehearty for their contributions to this blog post!
Benchmark Disclosures:
SPEC and the benchmark names SPECjbb2013 and SPECint are registered trademarks of the Standard Performance Evaluation Corporation. Results as of March 17, 2014 from www.spec.org
