This post is a continuation of the series – Machine Learning in PeopleSoft. The first post was an overview of the high-level steps involved in the Data Science lifecycle. The post can be found here.
In this post, we will go into the details of the first step, which deals with Data Acquisition. The example that will be used relates to predicting employee attrition in an organization. Considering various HR attributes, the ML Model would try to predict if the employee is an attrition risk or not. The example used in this post is only a sample and is not a representation of what PeopleSoft will deliver as a feature.
PeopleTools 8.58 provides a Data Distribution framework that allows users to flatten data and publish it to Elasticsearch. The Elasticsearch index is used as a data store and Machine Learning platforms like OCI Data Science can pull the data from the indexes for training the ML Model. The PeopleSoft Data Distribution Framework is built on the existing PeopleSoft Search Framework. The mechanism used to create Elasticsearch index definitions and ingesting data in the index is reused from the PeopleSoft Search Framework.
Note: The PeopleTools framework is called the “PeopleSoft Machine Learning Framework” until PeopleTools 8.58.03. From PeopleTools 8.58.04 patch, the name will be the “PeopleSoft Data Distribution Framework”.
More information on the Search Framework can be found in Peoplebooks here.
The following steps are required to flatten the data in PeopleSoft and publish it into an Elasticsearch index.
- Create a Search Definition in PeopleSoft
- Create an ML Data source using the Search Definition in PeopleSoft
- Create the Elasticsearch Index based on this Data source
- Ingest the data for the Elasticsearch Index
Create a Search Definition in PeopleSoft
The first task in any machine learning problem is to identify factors that will affect the outcome. For the attrition problem example that is being considered here, we identified different attributes like employee personal data (gender/marital status), performance-related information, education data, etc. Assume that all these attributes come from different PeopleSoft records. We created a PeopleSoft Query where the records were joined and data was flattened. This Query then becomes the source for creating a standard PeopleSoft Search definition as shown below:
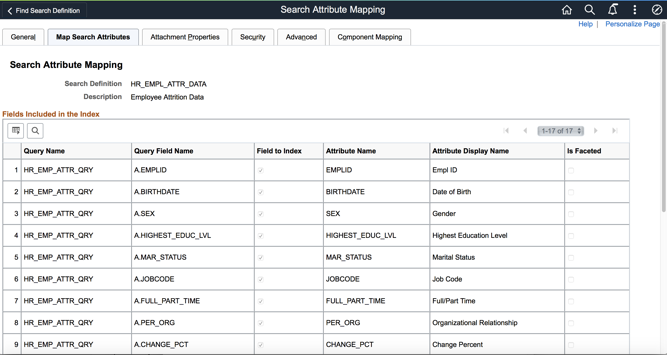
Another point to consider is data transformation, for example, one of the attributes being considered is employee birth date. However, from an ML perspective, the birth date itself doesn’t make much sense. Employee Age, on the other hand, could be a much more relevant factor. Instead of using the attribute birth date directly, the employee age can be calculated and then used in the Search definition. This will make computation easier while the ML Model is being trained. Similar transformations can be done for other variables that are either categorical in nature or related to things like time & date.
Create an ML Data source using the Search Definition in PeopleSoft
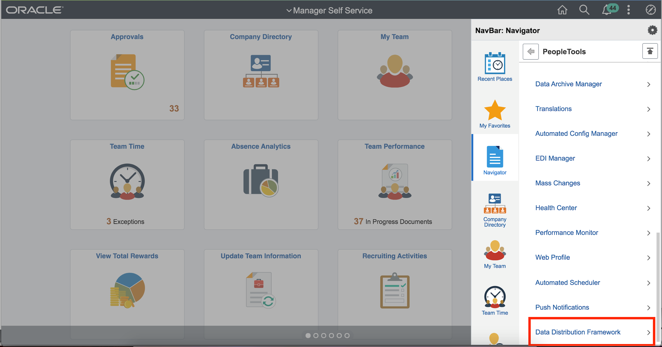
The next step after creating the Search Definition is to create an ML Data source using the same. For this, we need to navigate to the Data Distribution Framework menu under PeopleTools as shown below:
In the Data Distribution framework setup, a new ML Data Source should be created. Clicking on the Data Source link brings up the ML Data Source page:
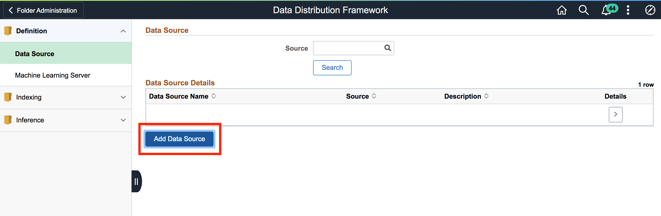
On this page, we click on the “Add Data Source” button to add a new Data Source as shown below:
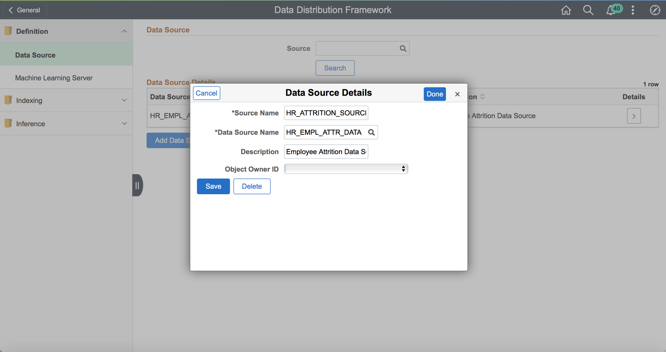
We then provide an appropriate Source Name. For the Data Source Name, the Search Definition created in the earlier step can be chosen. Clicking on the “Save” button creates the ML Data Source.
Create the Elasticsearch Index based on this Data source
Once the ML Data Source is created, an Index can be created in the Elasticsearch instance by clicking on the Index Manager option. After selecting the ML Data Source clicking on the “Create Index” button creates the index in Elasticsearch. The index name is displayed on the page. The Index name is useful while pulling the data from Elasticsearch in the OCI Data Science service. Once the index is created, the Map Status column value changes to “Indexed”.
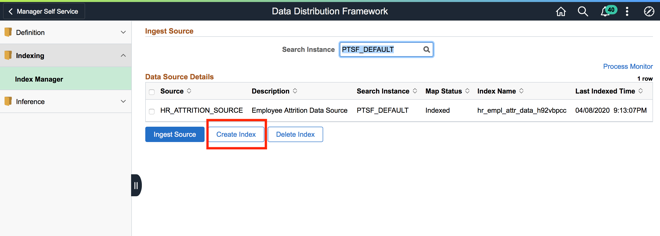
Ingest the data for the Elasticsearch Index
The final step is to ingest the data in the Elasticsearch index that was created. To do this, select the ML Data Source and choose the “Ingest Source” button. This initiates the “PTML_GENFEED” Application Engine program to push the data into the Elasticsearch Index.
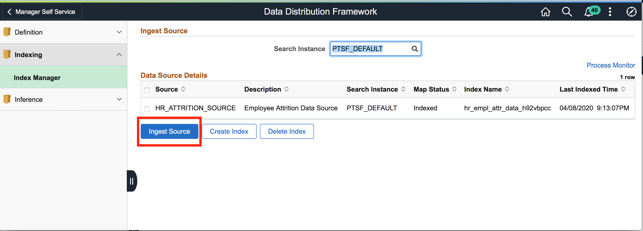
The completion of all the four steps flattens the data and publishes it to the data store (which in case of PeopleSoft is the Elasticsearch Index). The data is now available to be pulled for training for an ML platform like OCI Data Science service.
In the next post, I will talk about training and building an ML Model in the OCI Data Science service.
