PeopleSoft Cloud Manager has an exciting feature for horizontally scaling PeopleSoft environments in a completely automated way. This feature is based on machine learning algorithms that learn from past performance metrics and, based on that, detect anomalies in the current system load. This feature is integrated with the data science service in Oracle Cloud Infrastructure.
How will auto scaling help you?
Let us look at the following scenario. You have an FSM environment (with PeopleTools version 8.58 or above). It has 2 mid tier nodes, where each node has one application server domain, one web server domain, and one process scheduler domain each. On average, 20 users access the system and performance is good. Suppose, that on a particular day, the number of active users increases to 60, over a period of 2 or 3 hours. At this point, you might start observing performance issues. Response to requests might be delayed and some requests might time out. If you notice this issue, you might want to add a new middle tier node to this environment. Later when the load goes back to normal, the added node will be redundant. It will now add to compute cost, so you might want to remove it at that point.
Another approach, which is more typical, will be to provision redundant capacity with the maximum possible load in view. However, this can cause unnecessary compute costs because most of the time the VMs will be under-utilised.
In this scenario, using the auto scaling feature of Cloud Manager will be very convenient. You can provision the environment with average capacity to begin with. Using algorithms based on machine learning, Cloud Manager can detect anomalies in the usage and load on the environment. Once a very high load is detected, the auto scaling module will automatically add a new middle tier VM to the environment. Later when the load goes down to normal levels, Cloud Manager will automatically remove the extra node. Thus, the auto scaling module can automatically keep your system at good levels of performance at minimal compute cost, without manual intervention.
Set up data science resources
The auto scaling feature depends on the data science service provided by Oracle Cloud Infrastructure. Therefore, as the first step, resources and policies have to be set up for using the data science service. This can be done using an Oracle Resource Manager stack which can be downloaded from Github.
In a browser, go to page https://github.com/oracle-quickstart/oci-ods-orm. On this page, there is a “Code” menu under which you will find a “Download Zip” option. Click on “Download Zip”. Save the zip file to disk.
Now logon to OCI console. Please note that you have to be a member of the tenancy Administrator group before you can apply this configuration. Go to the Resource Manager Stacks screen by selecting the menu “Developer Services” -> “Resource manager” -> “Stacks”. Choose the option to create a new stack. Choose “My Configuration” and select the “.zip” file option. Upload the zip file that you downloaded from Github.


IAM Groups/Policies Configuration: This section in the Stack is mandatory. (You can edit the names of groups and policies if required.)
Vault Configuration: Not required for auto scaling feature. Please de-select this option.
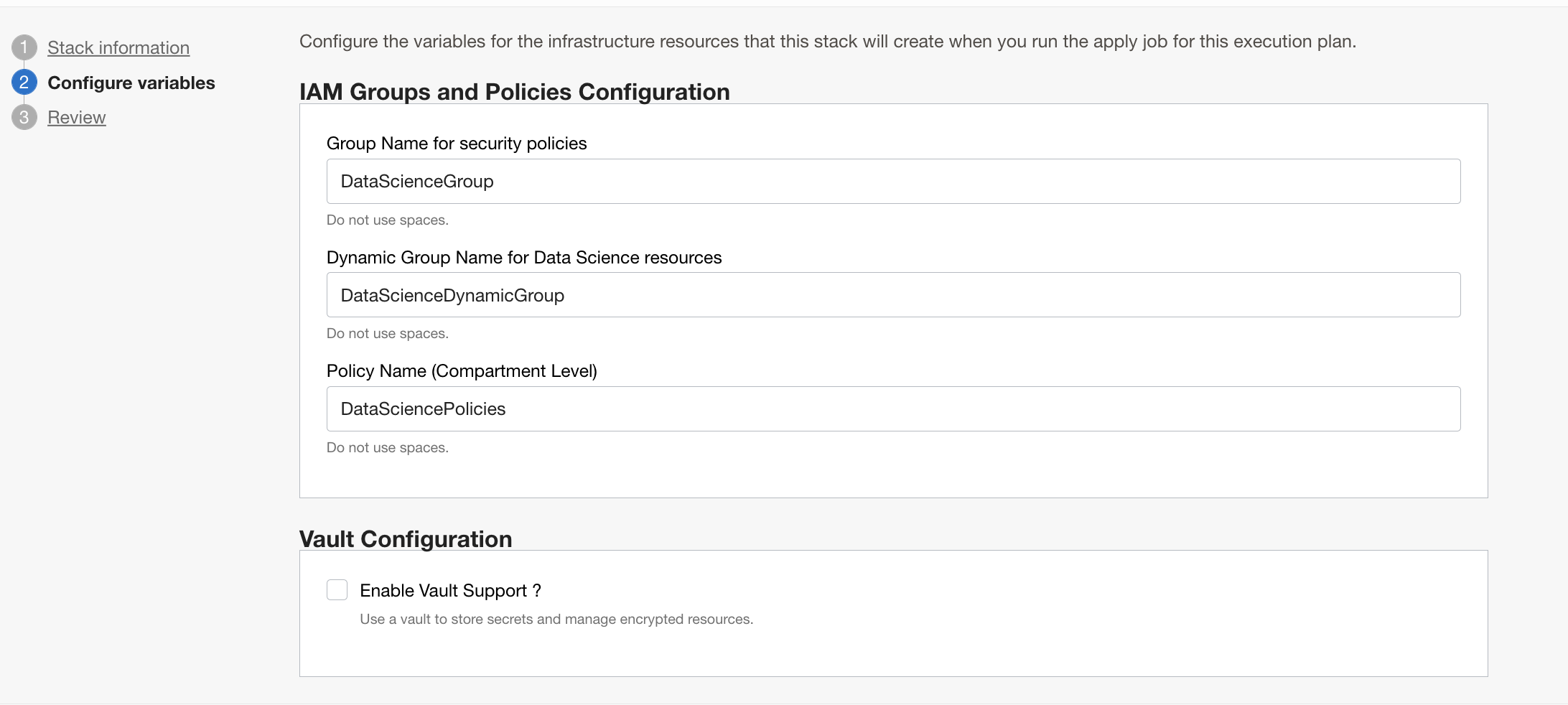

After saving the Stack, run Plan. When Plan runs, it will show all the resources that will be created by the stack when you later run apply. After Plan has ended successfully, run Apply on the stack. Now the groups, policies and other resources will be created by the RM stack.
After the Resource Manager stack is successfully “applied”, you need to manually add the Cloud Manager user OCID to the new group ( “DataScienceGroup” by default, or whatever other name you changed it to) which was created by the Resource Manager stack when you applied it.
(Cloud Manager requires the user to have a set of permissions which are documented in CM deployment document. Please ensure that the user id already has all those permissions, in addition to what is inherited from membership in the new datascience group.)
Network Configuration
When you choose a subnet for configuring Jobs in Cloud Manager, ensure that you select a private subnet. Public subnet will not work for this purpose. Ensure that the private subnet is configured with NAT gateway.
Set global options in Cloud Manager
Now you need to turn on the global flag “Enable monitoring services”. This will enable the following:
- Data upload for training
- Model training using the uploaded data
- Model prediction of the environment
The global monitoring option can be found by navigating to Cloud Manager Settings page as shown below:


Now you need to configure Data Science settings in Cloud Manager. Click the Cloud Manager Settings tile on the Cloud Manager home page. The Cloud Manager Settings page is displayed. On the page, click the Data Science Settings link displayed on the left panel.
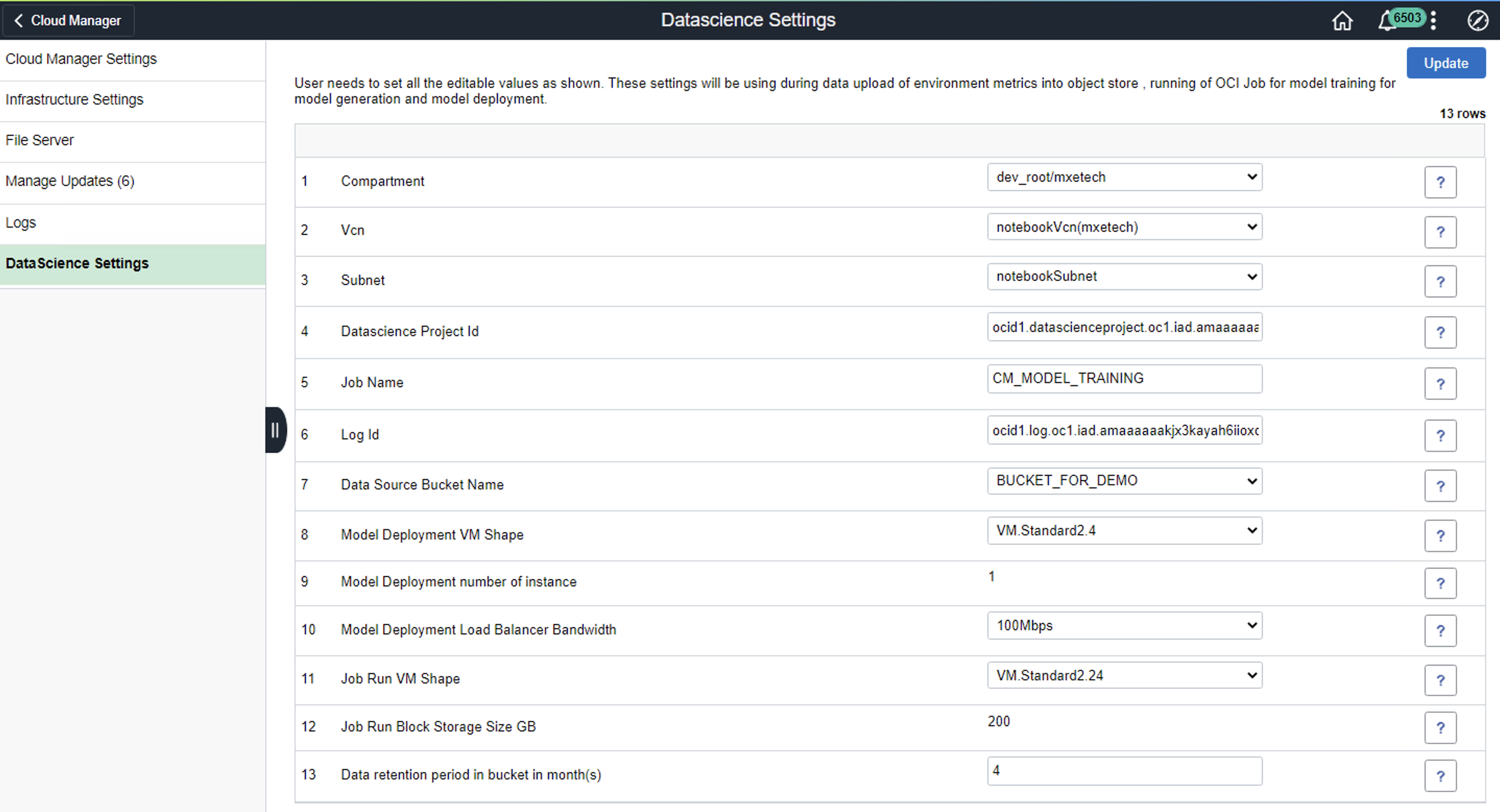

Please refer to the CM People-books for detailed explanation of each field in this page.
Check the environment for pre-requisites
Before proceeding further, it is a good idea to check and verify that certain pre-requisites are met by the environment which you want to bring under auto scaling.
Firewall requirements (ports for JMX): The data used by auto scaling feature for collecting the required run-time metrics requires JMX and RMI ports to be opened between Elastic Search node and middle tier nodes. The default port for JMX is 10100 and RMI port is 10101 for a single app server domain. For a Multi-app-server domain middle tier node, the next JMX and RMI port is the +2 increment of the default JMX and RMI ports. These ports should be opened to allow ingress from the Elastic Search server node into the middle tier nodes. You can do this by modifying the security lists attached to the subnet where the middle tier nodes are deployed.
ELK stack, Logstash : In Cloud Manager, from 8.58 PeopleTools version onwards, Logstash is automatically installed in the Elastic Search node when the latter is added to an environment. Network rules should be set for allowing the Cloud Manager instance to query the Elastic Search node of each environment.
Turn on auto scaling for the environment
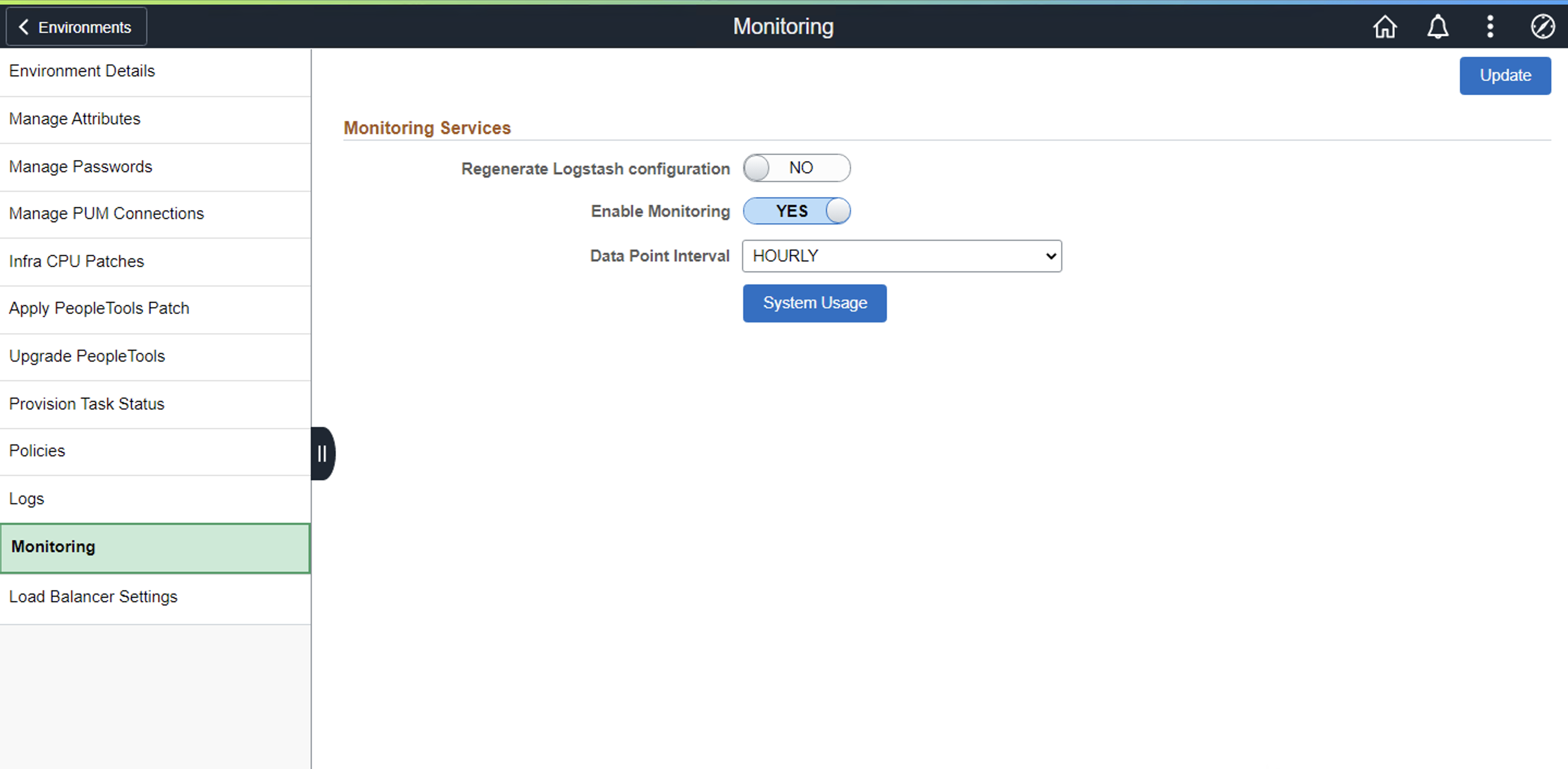
Now you need to verify that monitoring is enabled for the environment. To verify and turn on environment monitoring, please navigate to Environment Details → Monitoring. Please set Enable Monitoring to YES and click Update. This will start the Logstash process in the Elastic Search server node for metrics collection.

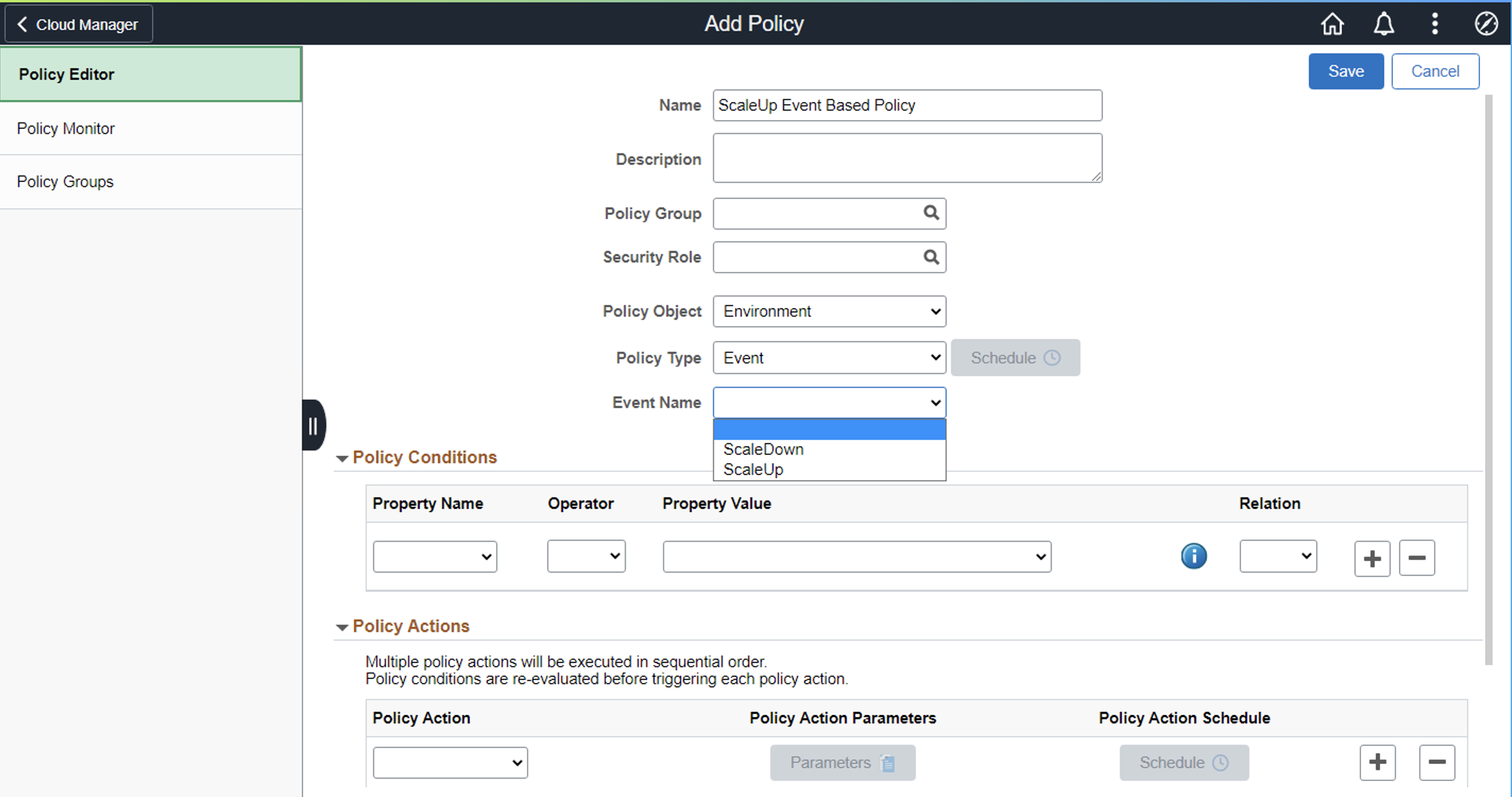
Now you need to set up an event-based policy for auto scaling, in the policy governance page in Cloud Manager. To do that, navigate to Governance→ Policy Editor
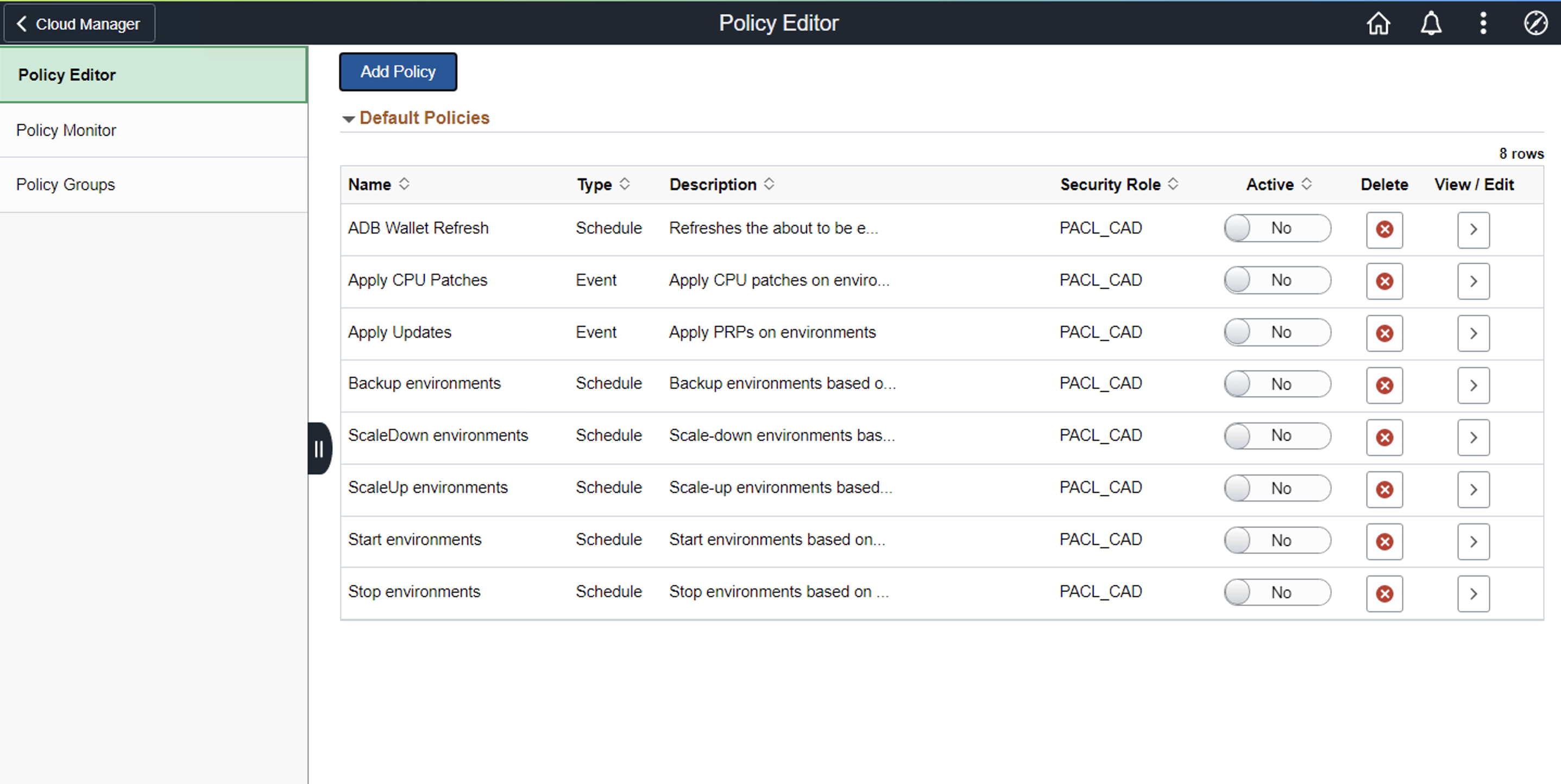

Click on Add Policy to add an event-type policy (both for Scale Up and Scale Down). Please refer to Cloud Manager documentation for the various fields/properties that need to be set here.
Verify that it is working
After you have completed the above steps, auto scaling will come into effect for the environment. If you want to verify that things are working as expected, you can do one or all of the following:
- psp.log: To verify that the auto scaling mechanism is active, you can grep for the pattern “mlearning” in the psp.log file located at
$PS_CFG_HOME/appserv/prcs/PRCSDOM/ as user psadm2
Ex: grep -li “mlearning” psp_2021-10-08*
- cron job output file: Logs for the anomaly detection API calls can be found at the below location:
<CM Python Log Root>/cmlogs/mlprediction/MODEL_PREDICTION_<YYYYMMDD>
One folder is created each day, so ensure that you are looking at the correct folder.
- Notification: When anomalies in the load are detected, the auto scaling module raises notifications. You can verify that notifications are raised by checking the bell icon in the upper right corner.
For further details about logs related to machine learning etc, please check the Cloud Manager documentation.
Note: This post was originally published on March 21, 2022, and subsequently updated on March 13, 2023, with screenshots and content relevant to the current release of Cloud Manager.

