※本記事は、Dmitry Aleksandrovによる”Programming the GPU in Java”を翻訳したものです。
JavaからGPUにアクセスすることで発揮される圧倒的な能力:GPUの動作の仕組みとJavaからのアクセス方法を解説
著者:Dmitry Aleksandrov
2020年1月10日
GPU(グラフィックス・プロセッシング・ユニット)プログラミングと聞くと、Javaプログラミングとはかけ離れた世界のことのように感じる方もいるでしょう。その気持ちもわかります。Javaのユースケースのほとんどは、GPUを適用できるものではないからです。しかしながら、GPUではテラフロップ級のパフォーマンスが実現します。ここでは、GPUの可能性を探究してみます。
このトピックの理解を助けるため、まずはGPUのアーキテクチャや簡単な歴史について説明します。この説明を読めば、GPUプログラミングに手を付けやすくなるでしょう。そしてGPUでの計算がCPUとどのように違うかについて説明し、その後はいよいよ、Javaの世界でGPUを使う方法に入ります。最後に、Javaコードを書く際やそのコードをGPUで実行する際に役立つ、代表的なフレームワークやライブラリについて触れます。また、いくつかのコード・サンプルも提示したいと思います。
簡単な背景
GPUを最初に普及させたのはNVIDIAで、1999年のことでした。GPUは、ディスプレイに転送する前のグラフィック・データを処理するために設計された特別なプロセッサです。ほとんどの場合、GPUを使用して、一部の計算をCPUからオフロードすることができます。これにより、CPUリソースが解放される一方で、GPUにオフロードされた計算は高速になります。その結果、処理できる入力データが増加し、出力解像度もはるかに大きくなることで、視覚表現の魅力は増し、フレーム・レートもより滑らかになります。
2D/3D処理の本質はほとんどが行列演算であるため、大規模な並列化アプローチによって処理できます。それでは、どうすれば効率的に画像を処理できるでしょうか。この質問に答えるため、標準的なCPUのアーキテクチャ(図1参照)とGPUのアーキテクチャを比較してみます。
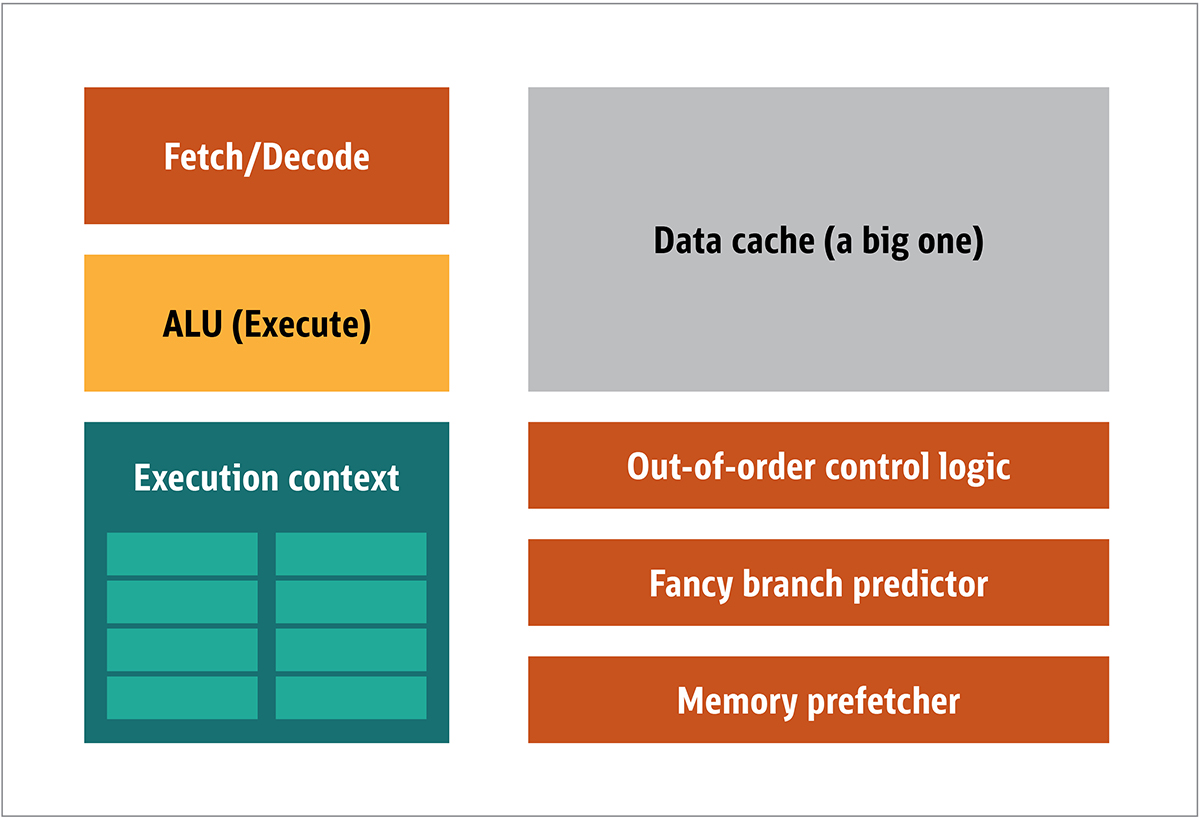
図1:CPUのブロック・アーキテクチャ
CPUでは、フェッチャ、算術論理演算装置(ALU)、実行コンテキストといった実際の処理の要素は、システム全体の一部でしかありません。予測できない順番でやってくる不規則な計算を高速化するため、CPUには高速で高価な大容量キャッシュ、さまざまな種類のプリフェッチャ、分岐予測器が搭載されています。
GPUには、これらすべてが必要になるわけではありません。受信するデータは予測可能であるうえ、極めて限られた種類のデータ演算だけを行うからです。そのため、非常に小さく安価なプロセッサを作ることができます。ブロック・アーキテクチャは図2のようなものになります。
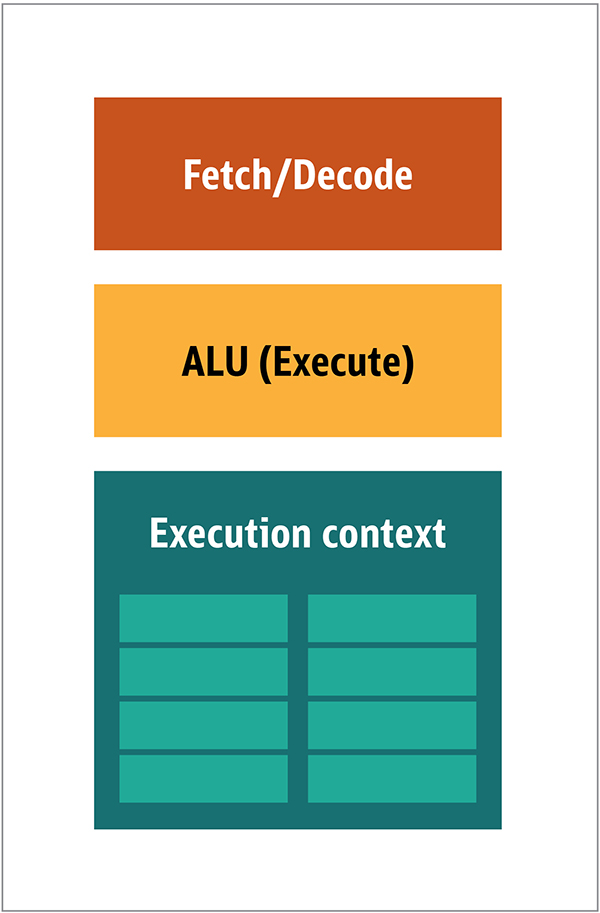
図2:シンプルなGPUコアのブロック・アーキテクチャ
こういったタイプのプロセッサは安価なうえ、データがまとめて並列処理されるため、多数のプロセッサを並列に動作させることも容易です。この設計は、複数命令/複数データ(MIMD。英語では「ミムディ」と発音します)と呼ばれます。
2つ目のアプローチは、1つの命令が複数のデータ項目に適用されることが多い点に着目したもので、単一命令/複数データ(SIMD。「シムディ」と発音します)と呼ばれています。この設計では、1つのGPUに複数のALUと実行コンテキストを含めたうえで、共有コンテキスト・データ専用の小さな領域も持たせます。図3をご覧ください。
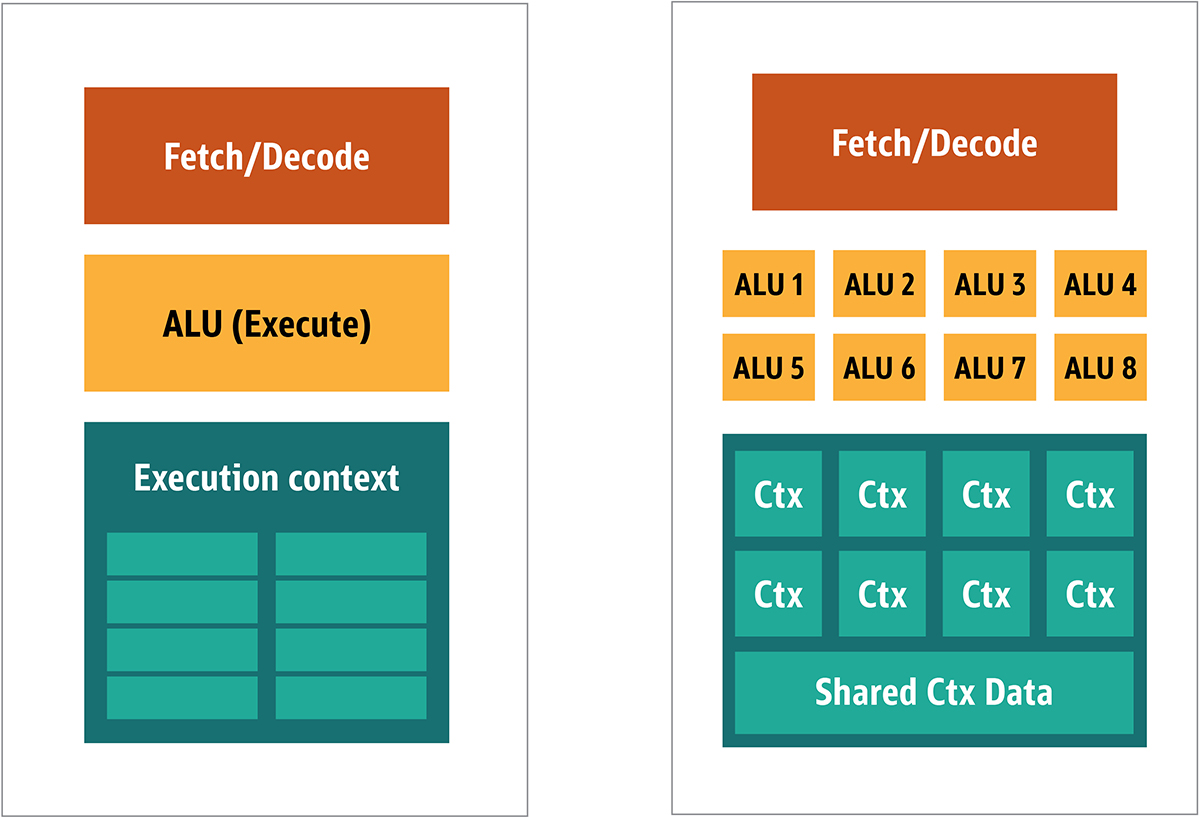
図3:MIMDスタイルのGPUブロック・アーキテクチャ(左)とSIMDの設計(右)との比較
SIMDとMIMD処理とを組み合わせることで、処理スループットが最大になります。この点については、後ほど触れたいと思います。この設計では、図4に示すように複数のSIMDプロセッサを並列に実行します。

図4:複数のSIMDプロセッサの並列実行。この例では16個のコア、合計128個のALUを使用
シンプルで小さいプロセッサが大量にあるため、プロセッサのプログラミングにより、出力に特別な効果を加えることができます。
GPUでプログラムを実行する
ゲームにおける初期の視覚効果のほとんどは実際のところ、GPUで動作する小さなプログラムをハードコードし、CPUから提供されるデータ・ストリームに適用して実現していました。
しかしその当時でも、視覚表現がまさに主なセールス・ポイントの1つであるゲームの設計においては特に、ハードコードされたアルゴリズムでは不十分なことは明らかでした。そこで、大規模ベンダーはGPUにアクセスする方法を公開し、GPUを使うコードをサードパーティの開発者が書けるようにしました。
その典型的な方法は、特別な言語(通常はCのサブセット)を使ってシェーダと呼ばれる小さなプログラムを書き、アーキテクチャに対応した特別なコンパイラでコンパイルするというものでした。シェーダという用語が選ばれたのは、シェーダが照明(ライティング)や陰影(シェーディング)の効果を制御するために使われることが多かったからです。しかし、その他の特殊効果を行えない理由はありません。
それぞれのGPUベンダーでは、自社のハードウェアに対応したシェーダを作成するための、特別なプログラミング言語およびインフラストラクチャを独自に持っていました。そのような流れの中で、さまざまなプラットフォームが生まれてきました。主なものを紹介します。
- DirectCompute:Microsoft独自のシェーダ言語/API。Direct3Dの一部で、DirectX 10以降に対応
- AMD FireStream:ATI/Radeonの独自テクノロジー。AMDは開発を終了
- OpenACC:複数ベンダーのコンソーシアムによる並列コンピューティング・ソリューション
- C++ AMP:C++でのデータ並列化に用いられるMicrosoft独自のライブラリ
- CUDA:NVIDIAの独自プラットフォーム。C言語のサブセットを使用
- OpenCL:共通標準。もともとはAppleが設計したものであるが、現在はKhronos Groupというコンソーシアムが管理
GPUを使う場合、ほとんどの状況で低レベル・プログラミングとなります。開発者がコーディングする際に少しでもわかりやすくするため、いくつかの抽象化も行われています。もっとも有名なものは、MicrosoftのDirectXと、Khronos GroupのOpenGLです。これらのAPIは、高レベルなコードを書くためのものです。開発者は、書いたコードをほぼシームレスにGPUへとオフロードすることができます。
筆者の知る限り、DirectXをサポートするJavaインフラストラクチャはありません。しかし、OpenGLにはすばらしいバインディングが存在します。GPUプログラミングへの対応を行うJSR 231は、2002年に開始されましたが、2008年に中断され、OpenGL 2.0のみのサポートにとどまりました。OpenGLのサポートは、JOCLと呼ばれる独立したプロジェクト(OpenCLのサポートも行われています)で継続されており、一般にも公開されています。ちなみに、有名なゲームであるMinecraftの内部処理は、JOCLで書かれています。
GPGPUの登場
それでも、JavaとGPUはシームレスに結合されているわけではありません(そうなっているべきなのですが)。Javaは、企業やデータ・サイエンス、金融部門で多用されています。こういった用途では、多くの計算や大きな処理能力が必要とされます。そこから登場したのが、GPGPU(汎用GPU)という考え方です。
画像データの処理以外にGPUを使おうという考え方が出現したのは、ビデオ・アダプタのベンダーがフレーム・バッファのプログラミングを開放し、開発者がフレーム・バッファの内容を読み取れるようになり始めたときでした。一部のマニアが、GPUを汎用計算にフル活用できることに気づきました。その方法は簡単でした。
- データをエンコードしてビットマップ配列にする
- ビットマップ配列を処理するシェーダを書く
- ビットマップ配列とシェーダをビデオ・カードに送信する
- フレームバッファから結果を取得する
- ビットマップ配列をデコードしてデータを取り出す
この説明は非常に簡略化したものです。この処理が実際の環境で多用されたことがあったかどうかはわかりませんが、動作したことは確かです。
続いて、スタンフォード大学の研究者たちが、GPGPUを使いやすくする方法を探し始めました。2005年、その研究者たちがBrookGPUをリリースしました。これは、言語とコンパイラ、そしてランタイムを含んだ小さなエコシステムでした。
BrookGPUは、Brookというストリーム・プログラミング言語で書かれたプログラムをコンパイルするものでした。この言語はANSI Cを拡張したもので、計算バックエンドとしてOpenGL v1.3以降、DirectX v9以降、AMDのClose to Metalをターゲットにすることができ、Microsoft WindowsとLinuxの両方で動作しました。また、BrookGPUではデバッグ用にCPUで仮想グラフィックス・カードをシミュレートすることもできました。
しかし、BrookGPUは成功しませんでした。その理由は、当時のハードウェアにあります。GPGPUの世界では、データをデバイス(ここでのデバイスは、GPUと、GPUが搭載されたボードを指しています)にコピーし、GPUがデータを処理するのを待ち、その処理が終わってからデータをメイン・ランタイムにコピーする必要があります。この処理には、長い待機時間が伴います。このプロジェクトでの開発が活発だった2000年代中盤当時は、この待機時間が障害となり、GPUを広く汎用計算に使うことはほぼ不可能でした。
それでも、多くの企業がこのテクノロジーに将来を見ました。ビデオ・アダプタのベンダーからは、独自テクノロジーとともにGPGPUを提供し始めるところも出てきました。また、アライアンスを組んだベンダーが、いっそう幅広いハードウェア・デバイスで動作する、汎用性を高めた柔軟なプログラミング・モデルを提供したこともありました。
背景の説明は以上です。次は、GPUコンピューティングで特に成功を収めたと言える2つのテクノロジーである、OpenCLとCUDAに迫り、Javaでこの2つを使う方法について確認します。
OpenCLとJava
その他多くのインフラストラクチャ・パッケージと同様に、OpenCLのベース実装はCで提供されています。そのため、Javaネイティブ・インタフェース(JNI)やJavaネイティブ・アクセス(JNA)を使ってアクセスすることも技術的には可能ですが、ほとんどの開発者にとってこのようなアクセス方法はやや過度な負担となるでしょう。ありがたいことに、JOCL、JogAmp、JavaCLというライブラリでこの作業がすでに行われています。JavaCLはすでに終了したプロジェクトですが、JOCLプロジェクトはかなり活発に活動しています。次のサンプルでは、JOCLを使用します。
本題に入る前に、OpenCLとは何かについて説明しておきます。先ほども触れたように、OpenCLでは非常に汎用的なモデルを提供しています。このモデルは、GPUやCPUだけでなく、デジタルシグナルプロセッサ(DSP)やField-Programmable Gate Array(FPGA)にまでわたる、あらゆる種類のデバイスのプログラミングに適しています。
それでは、一番簡単な例であり、おそらくもっとも代表的で単純な例である、ベクトルの加算から考えてみます。加算する2つの整数配列と、結果を格納する1つの配列があります。図5に示すように、1つ目の配列と2つ目の配列から要素を1つずつ取得し、その合計を結果の配列に格納します。
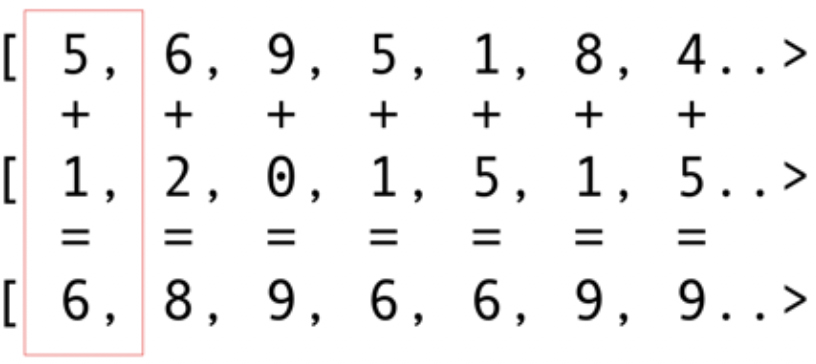
図5:2つの配列の内容を加算し、合計を結果の配列に格納
おわかりのように、この演算はすべて同時に進めることができます。つまり、非常に並列度が高いということです。それぞれの加算演算は、別々のGPUコアにプッシュすることができます。すなわち、コアが2,048個(NVIDIA 1080グラフィックス・カードのコア数です)あれば、2,048個の加算演算を同時に実行できます。つまり、テラフロップ級の計算能力が皆さんを待っているということです。次に示すのは、1000万個の整数の配列を処理するコードです。このコードは、JOCLのサイトに掲載されているサンプルです。[訳注:実際のコメントは英語です。]
public class ArrayGPU {
/**
* OpenCLプログラムのソース・コード
*/
private static String programSource =
"__kernel void "+
"sampleKernel(__global const float *a,"+
" __global const float *b,"+
" __global float *c)"+
"{"+
" int gid = get_global_id(0);"+
" c[gid] = a[gid] + b[gid];"+
"}";
public static void main(String args[])
{
int n = 10_000_000;
float srcArrayA[] = new float[n];
float srcArrayB[] = new float[n];
float dstArray[] = new float[n];
for (int i=0; i<n; i++)
{
srcArrayA[i] = i;
srcArrayB[i] = i;
}
Pointer srcA = Pointer.to(srcArrayA);
Pointer srcB = Pointer.to(srcArrayB);
Pointer dst = Pointer.to(dstArray);
// 使用するプラットフォーム、デバイス・タイプ、
// デバイス番号
final int platformIndex = 0;
final long deviceType = CL.CL_DEVICE_TYPE_ALL;
final int deviceIndex = 0;
// このサンプルのこれ以降でのエラー・チェックを省くため、例外を有効化する
CL.setExceptionsEnabled(true);
// プラットフォームの数を取得する
int numPlatformsArray[] = new int[1];
CL.clGetPlatformIDs(0, null, numPlatformsArray);
int numPlatforms = numPlatformsArray[0];
// プラットフォームIDを取得する
cl_platform_id platforms[] = new cl_platform_id[numPlatforms];
CL.clGetPlatformIDs(platforms.length, platforms, null);
cl_platform_id platform = platforms[platformIndex];
// コンテキスト・プロパティを初期化する
cl_context_properties contextProperties = new cl_context_properties();
contextProperties.addProperty(CL.CL_CONTEXT_PLATFORM, platform);
// プラットフォームのデバイス数を取得する
int numDevicesArray[] = new int[1];
CL.clGetDeviceIDs(platform, deviceType, 0, null, numDevicesArray);
int numDevices = numDevicesArray[0];
// デバイスIDを取得する
cl_device_id devices[] = new cl_device_id[numDevices];
CL.clGetDeviceIDs(platform, deviceType, numDevices, devices, null);
cl_device_id device = devices[deviceIndex];
// 選択したデバイスのコンテキストを作成する
cl_context context = CL.clCreateContext(
contextProperties, 1, new cl_device_id[]{device},
null, null, null);
// 選択したデバイスのコマンド・キューを作成する
cl_command_queue commandQueue =
CL.clCreateCommandQueue(context, device, 0, null);
// 入出力データ用のメモリ・オブジェクトを割り当てる
cl_mem memObjects[] = new cl_mem[3];
memObjects[0] = CL.clCreateBuffer(context,
CL.CL_MEM_READ_ONLY | CL.CL_MEM_COPY_HOST_PTR,
Sizeof.cl_float * n, srcA, null);
memObjects[1] = CL.clCreateBuffer(context,
CL.CL_MEM_READ_ONLY | CL.CL_MEM_COPY_HOST_PTR,
Sizeof.cl_float * n, srcB, null);
memObjects[2] = CL.clCreateBuffer(context,
CL.CL_MEM_READ_WRITE,
Sizeof.cl_float * n, null, null);
// ソース・コードからプログラムを作成する
cl_program program = CL.clCreateProgramWithSource(context,
1, new String[]{ programSource }, null, null);
// プログラムをビルドする
CL.clBuildProgram(program, 0, null, null, null, null);
// カーネルを作成する
cl_kernel kernel = CL.clCreateKernel(program, "sampleKernel", null);
// カーネルに渡す引数を設定する
CL.clSetKernelArg(kernel, 0,
Sizeof.cl_mem, Pointer.to(memObjects[0]));
CL.clSetKernelArg(kernel, 1,
Sizeof.cl_mem, Pointer.to(memObjects[1]));
CL.clSetKernelArg(kernel, 2,
Sizeof.cl_mem, Pointer.to(memObjects[2]));
// ワーク・アイテムの次元を設定する
long global_work_size[] = new long[]{n};
long local_work_size[] = new long[]{1};
// カーネルを実行する
CL.clEnqueueNDRangeKernel(commandQueue, kernel, 1, null,
global_work_size, local_work_size, 0, null, null);
// 出力データを読み取る
CL.clEnqueueReadBuffer(commandQueue, memObjects[2], CL.CL_TRUE, 0,
n * Sizeof.cl_float, dst, 0, null, null);
// カーネル、プログラム、メモリ・オブジェクトを解放する
CL.clReleaseMemObject(memObjects[0]);
CL.clReleaseMemObject(memObjects[1]);
CL.clReleaseMemObject(memObjects[2]);
CL.clReleaseKernel(kernel);
CL.clReleaseProgram(program);
CL.clReleaseCommandQueue(commandQueue);
CL.clReleaseContext(context);
}
private static String getString(cl_device_id device, int paramName) {
// 照会する文字列の長さを取得する
long size[] = new long[1];
CL.clGetDeviceInfo(device, paramName, 0, null, size);
// 適切なサイズのバッファを作成し、情報を格納する
byte buffer[] = new byte[(int)size[0]];
CL.clGetDeviceInfo(device, paramName, buffer.length, Pointer.to(buffer), null);
// バッファ(末尾にある\0のバイトは除く)から文字列を作成する
return new String(buffer, 0, buffer.length-1);
}
}
Javaらしくありませんが、確かにJavaのコードです。以降でこのコードを解説しますが、あまり時間をかけないでください。後ほどもう少し簡単なソリューションを紹介するからです。
コードには細かいコメントが付いていますが、順を追って見ていきます。ご覧のとおり、コードは非常にCに近い形になっています。それもそのはずです。というのも、JOCLはOpenCLのバインディングにすぎないからです。冒頭では、コードが文字列に格納されています。実は、このコードこそがもっとも重要な部分です。このコードはOpenCLでコンパイルされ、ビデオ・カードに送信されて実行されます。このコードをカーネルと呼びます。この用語をOSのカーネルと混同しないでください。ここでのカーネルは、デバイス・コードのことです。このカーネル・コードはCのサブセットで書かれています。
カーネルの後には、Javaバインディングのコードがあります。このコードで行っているのは、デバイスの設定およびオーケストレーション、データ・チャンクの作成、デバイスでの適切なメモリ・バッファ(入力データ用および結果データ用)の作成です。
つまり、コードには、「ホスト・コード」(通常は言語バインディングであり、今回の場合はJava)と、「デバイス・コード」があります。ホストで実行されるものとデバイスで実行されるべきものは必ず区別します。ホストがデバイスを制御するからです。
先ほどのコードは、GPU版の「Hello World!」であると考えてください。ご覧のとおり、「おまじない」はかなりの量になっています。
忘れてはいけないのが、SIMDの機能です。お使いのハードウェアがSIMD拡張をサポートしている場合、算術演算コードの実行を大幅に高速化することができます。例として、行列の乗算を行うカーネル・コードを見てみます。次に示すのは、Javaアプリケーションに文字列として書かれるコードです。
__kernel void MatrixMul_kernel_basic(int dim,
__global float *A,
__global float *B,
__global float *C){
int iCol = get_global_id(0);
int iRow = get_global_id(1);
float result = 0.0;
for(int i=0; i< dim; ++i)
{
result +=
A[iRow*dim + i]*B[i*dim + iCol];
}
C[iRow*dim + iCol] = result;
}
技術的に言えば、このコードでは、OpenCLフレームワークで設定されたデータ・チャンクに対して、「おまじない」の中で指定した命令を実行します。
お使いのビデオ・カードがSIMD命令をサポートしており、4次元浮動小数点数ベクトルを処理できる場合、先ほどのコードを少しばかり最適化して次のようにすることができます。
#define VECTOR_SIZE 4
__kernel void MatrixMul_kernel_basic_vector4(
size_t dim, // 次元は単精度浮動小数点数
const float4 *A,
const float4 *B,
float4 *C)
{
size_t globalIdx = get_global_id(0);
size_t globalIdy = get_global_id(1);
float4 resultVec = (float4){ 0, 0, 0, 0 };
size_t dimVec = dim / 4;
for(size_t i = 0; i < dimVec; ++i) {
float4 Avector = A[dimVec * globalIdy + i];
float4 Bvector[4];
Bvector[0] = B[dimVec * (i * 4 + 0) + globalIdx];
Bvector[1] = B[dimVec * (i * 4 + 1) + globalIdx];
Bvector[2] = B[dimVec * (i * 4 + 2) + globalIdx];
Bvector[3] = B[dimVec * (i * 4 + 3) + globalIdx];
resultVec += Avector[0] * Bvector[0];
resultVec += Avector[1] * Bvector[1];
resultVec += Avector[2] * Bvector[2];
resultVec += Avector[3] * Bvector[3];
}
C[dimVec * globalIdy + globalIdx] = resultVec;
}
このコードを使うことで、パフォーマンスを2倍にすることができます。
すばらしいですね。Javaの世界でGPUのパワーを解き放ちました。しかし、Java開発者である皆さんは、このようなバインディングを実行してCコードを記述し、低レベルの詳細を扱う作業を実際に行いたいと思うでしょうか。当然ながら、私は遠慮したいと思います。ここまででGPUアーキテクチャの使い方に関するある程度の知識は得られたため、先ほどのJOCLコード以外のソリューションも見てみることにします。
CUDAとJava
CUDAはNVIDIAのソリューションであり、先に述べたコーディングの問題に対処するものです。CUDAでは、標準的なGPU演算のためにすぐに使用できる、数多くのライブラリが提供されます。たとえば、行列、ヒストグラム、さらにはディープ・ニューラル・ネットワークなどの演算に対応しています。比較的新しいライブラリ・リストには、多くの便利なバインディングがすでに含まれています。以下に挙げるのは、JCudaプロジェクトによるものです。
- JCublas:行列全般
- JCufft:高速フーリエ変換
- JCurand:乱数全般
- JCusparse:疎行列
- JCusolver:因数分解
- JNvgraph:グラフ全般
- JCudpp:CUDA Data Parallel Primitives Libraryといくつかのソート・アルゴリズム
- JNpp:GPUによる画像処理
- JCudnn:ディープ・ニューラル・ネットワーク・ライブラリ
ここでは、乱数を生成するJCurandの使用について説明します。他の特別なカーネル言語は不要で、直接Javaコードから使用できます。次に例を示します。
...
int n = 100;
curandGenerator generator = new curandGenerator();
float hostData[] = new float[n];
Pointer deviceData = new Pointer();
cudaMalloc(deviceData, n * Sizeof.FLOAT);
curandCreateGenerator(generator, CURAND_RNG_PSEUDO_DEFAULT);
curandSetPseudoRandomGeneratorSeed(generator, 1234);
curandGenerateUniform(generator, deviceData, n);
cudaMemcpy(Pointer.to(hostData), deviceData,
n * Sizeof.FLOAT, cudaMemcpyDeviceToHost);
System.out.println(Arrays.toString(hostData));
curandDestroyGenerator(generator);
cudaFree(deviceData);
...
ここでは、数学的に非常に強固な理論に基づき、高品質な乱数をより多く作成するためにGPUを使用しています。
いくつかのJARファイルをクラスパスに追加しておけば、JCudaを使って書いた汎用的なCUDAコードをJavaから呼び出すこともできます。その他の例については、JCudaのドキュメントをご覧ください。
低レベルなコードを回避する
前述の方法はいずれもすばらしいものに見えますが、実行するための「おまじない」、設定、そして言語数が多すぎます。一部だけでもGPUを使う方法はないのでしょうか。
こういったOpenCLやCUDAなどの内部処理の隅々まで考えなくてもよい方法はないのでしょうか。内部処理について考えずに、Javaのコードを書くだけの方法はないでしょうか。そういったニーズに役立つかもしれないのが、Aparapiプロジェクトです。Aparapiは、「a parallel API」(並列API)を表しています。筆者は、内部的にOpenCLを使うGPUプログラミング向けのHibernateのようなものだと考えています。ベクトル加算の例を見てみます。
public static void main(String[] _args) {
final int size = 512;
final float[] a = new float[size];
final float[] b = new float[size];
/* 配列に乱数を設定する */
for (int i = 0; i < size; i++){
a[i] = (float) (Math.random() * 100);
b[i] = (float) (Math.random() * 100);
}
final float[] sum = new float[size];
Kernel kernel = new Kernel(){
@Override public void run() {
I int gid = getGlobalId();
sum[gid] = a[gid] + b[gid];
}
};
kernel.execute(Range.create(size));
for(int i = 0; i < size; i++) {
System.out.printf("%6.2f + %6.2f = %8.2f\n", a[i], b[i], sum[i])
}
kernel.dispose();
}
これは純粋なJavaコード(Aparapiのドキュメントから引用しています[訳注:実際のコメントは英語です])ですが、KernelやgetGlobalIdといったGPU分野特有の用語があちこちに散りばめられています。GPUプログラミングの仕組みを理解しておく必要がある点は変わりませんが、これまで紹介した方法よりはJavaフレンドリな形でGPGPUを取り扱うことができます。さらに、AparapiではOpenGLコンテキストを下層にあたるOpenCLレイヤーに簡単にバインドする方法を提供しています。これにより、データを完全にビデオ・カード上で保持できるようになるため、メモリの待機時間の問題も解消されます。
独立した計算を大量に行う必要がある場合は、Aparapiを検討してください。多数の例の中から、大規模並列計算にぴったりなユースケースが見つかります。
また、適切な計算をCPUからGPUに自動オフロードしてくれるプロジェクト(TornadoVMなど)も複数存在します。こういったものにより、大規模な最適化をすぐに行うことができます。
まとめ
GPUがゲーム・チェンジャーの役割を果たすようなメリットを発揮できる用途は数多くありますが、まだ障害がいくつかあると感じる方もいらっしゃるでしょう。しかし、JavaとGPUを組み合わせれば、すばらしい可能性を開くことができます。本記事は、この広大なトピックの表面をなぞっただけにすぎません。本記事の目的は、JavaからGPUにアクセスするための、さまざまな高レベルおよび低レベルな選択肢を紹介することでした。この領域を突き詰めていけば、パフォーマンス上の大きなメリットが得られることでしょう。並列に実行できる大量の計算が必要になる複雑な問題の場合、そのメリットは特に大きくなります。
 |
ドミトリー・アレクサンドロフDmitry Aleksandrov(@bercut2000):T-Systemsのチーフ・アーキテクト、Java Champion、Oracle Groundbreaker。ブロガーとしても活躍。主に銀行/電気通信分野のJava Enterpriseで10年超の経験を持ち、JVM動的言語やGPUによる大規模並列計算などの機能にも関心を持つ。Bulgarian Java User Groupの共同リーダーの1人で、jPrime Confの共同主催者でもある。地元のイベントや、JavaOne/Code One、Devoxx、JavaZone、Joker/JPointなどのカンファレンスで、頻繁に講演を行っている。 |
