このブログでは、SQL DeveloperのAmazon Redshift Migration Assistantを使用して、既存のAmazon RedshiftをOracle Autonomous Data Warehouse(ADW) に移行する方法を簡単に説明致します。
しかしまずは、なぜAutonomous Data Warehouseへの移行が必要なのかをお話ししましょう。
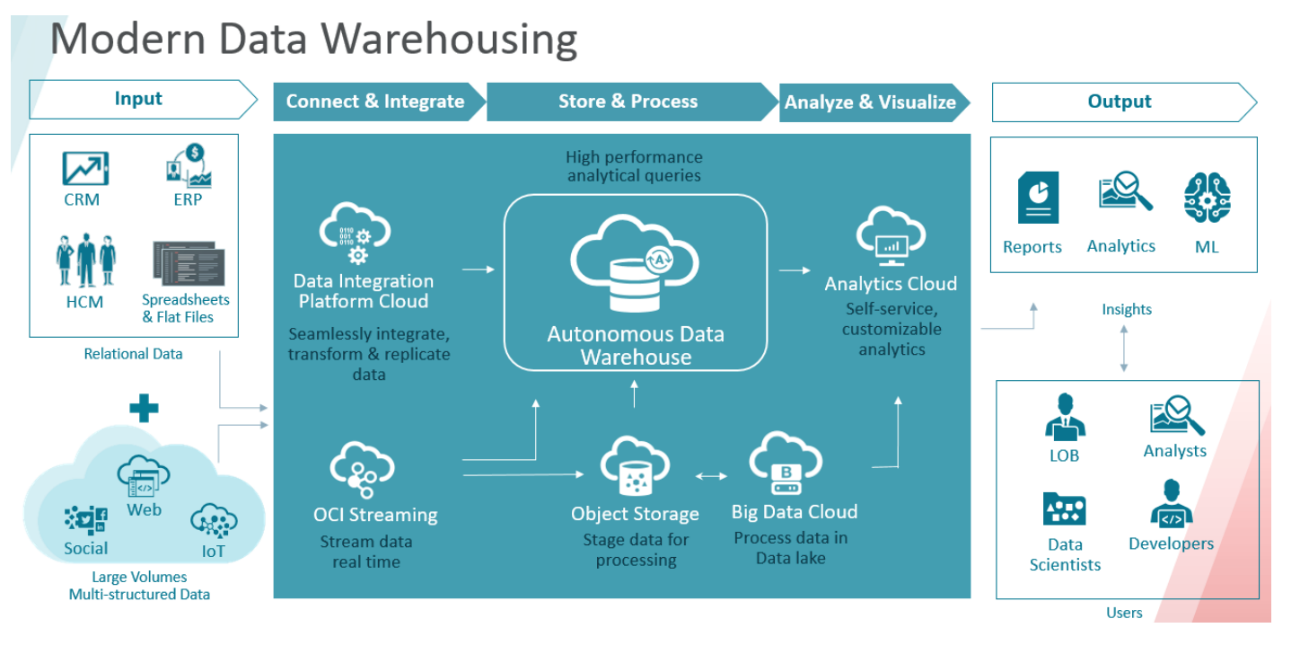
アナリティクスによって競争優位性を高めて自社を差別化するデータドリブンの企業では、自社のすべてのデータソースから価値を抽出しています。企業の物理的データウェアハウスは、全社からデータを収集して分析に活用する上でかつては優れた仕組みでしたが、途方もないスピードでデータが生成されている現在のデジタル・ワールドでは、そのスピードに追い付けず、そうしたデータに対応するために必要なストレージや計算リソースを提供できない状態になっています。さらに、環境やデータのパッチ、アップグレード、セキュリティのための複雑なタスクを手動で実施することには、多大なるリスクも伴います。
こうしたニッチな市場に対応できる数少ないクラウド・ベンダーの1つが、ParAccelからライセンス供与された技術を活用した、フル・マネージドなデータウェアハウス・クラウド・サービスであるAmazon Redshiftです。これは早くから市場に投入されたサービスではあるものの、そのクエリー処理アーキテクチャでは同時実行性のレベルが厳しく制限されるため、大規模なデータウェアハウスやWebスケールのデータ・アナリティクスには適していません。Redshiftはハードウェア構成の固定されたブロックでのみ利用可能であるため、ストレージと関係なくコンピュータを拡張することはできません。これでは予備のキャパシティが必要となるため、利用者は実際に使用する以上に利用コストをかける必要があります。さらに、リサイジングにおいては読取り専用状態になり、またダウンタイムが必要になることもあるため、データを再配分するのに数時間を要することもあります。
一方Oracle Autonomous Data Warehouseは、データウェアハウスのワークロードに合わせてチューニングおよび最適化される、フル・マネージドのデータベースで、構造化データと非構造化データの両方に対応しています。パッチやチューニング、バックアップ、アップグレードも実質的にダウンタイムなしで自動的かつ継続的に実施できます。総合的な機械学習アルゴリズムにより、自動キャッシング、適応的な索引付け、高度な圧縮が促進され、最適化されたクラウド・データローディングによりパフォーマンスが圧倒的に向上するため、データからインサイトを迅速に導き出し、リアルタイムで重要な意思決定を下すことができます。人間による介入がごくわずかであるため、ヒューマン・エラーをほぼ解消することができ、セキュリティ侵害や機能停止も、そしてコストも最小限に抑えられるという、素晴らしい可能性が示唆されています。Autonomous Data Warehouseは、既存のオンプレミスのマートやデータウェアハウス、アプリケーションを実行する、最新のOracle Databaseのソフトウェアおよびテクノロジーに合わせて構築されているため、既存のデータウェアハウスやデータ統合、BIツールとの互換性が確保されています。
データウェアハウスの移行を戦略的に計画
以下に、Amazon Redshiftのオンデマンドの移行にも、手動での移行を後日実行するようスケジュールするためのスクリプトの作成にも対応できるワークフローを紹介します。
SQL DeveloperのMigration Assistantを使用して、Amazon Redshift(移行元)とOracle Autonomous Data Warehouse(移行先)の両方への接続を確立します。
SQL Developer 18.3またはそれ以降のバージョンをダウンロードします。これはクライアント・アプリケーションで、WindowsかMac OSXかに関係なく、ワークステーションやノートパソコンにインストールできます。このブログではMicrosoft Windowsで実行します。Amazon Redshiftの環境にアクセスするため、Amazon Redshift JDBCドライバをダウンロードします。
SQL Developerアプリケーションを開き、サード・パーティのドライバとしてRedshift JDBCドライバを追加します(ツール → プリファレンス → データベース → サード・パーティJDBCドライバ)。
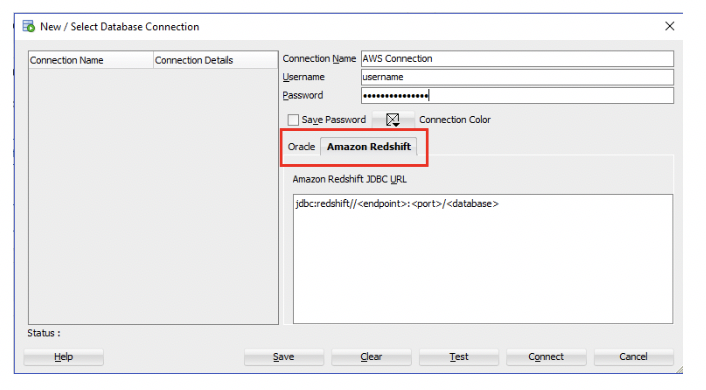
「接続」パネルにてAmazon Redshiftデータベースへの接続を追加して新しい接続を作成し、「Amazon Redshift」タブを選択して、Amazon Redshiftの接続情報を入力します。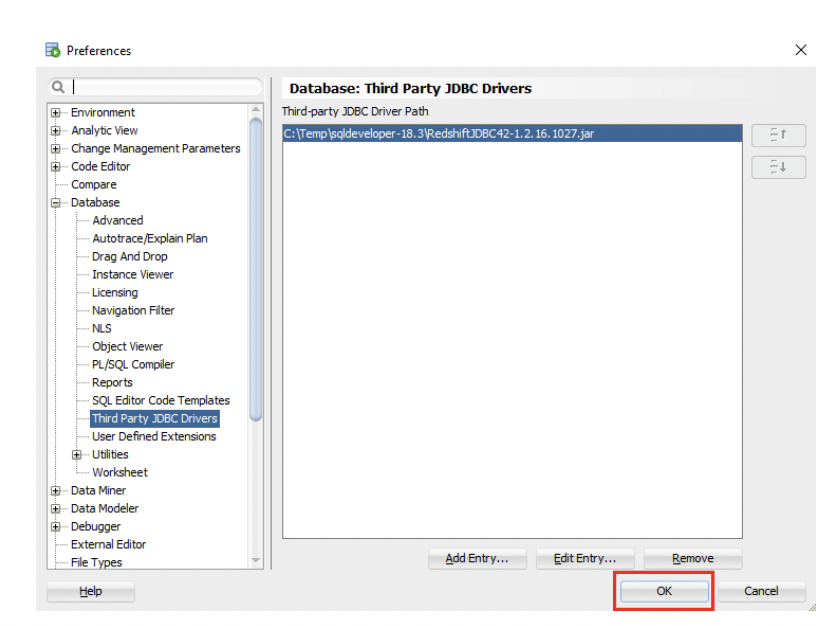
ヒント:
- 複数のスキーマを移行する場合は、マスター・ユーザー名にてAmazon Redshiftインスタンスに接続することをお薦めします。
- 仮想プライベート・クラウド(VPC)内にAmazon Redshift環境を適用している場合は、インターネットからクラスタにアクセスできることを確認する必要があります。公開インターネット・アクセスを可能にするための詳細については、こちらを参照してください。
- 長時間の問合せを実行中に、データベースへのAmazon Redshiftのクライアント接続がハングしたり、タイムアウトになったりしたように見える場合は、こちらに記載されているソリューション案を参照してください。
「接続」パネルにてOracle Autonomous Data Warehouseへの接続を追加して新しい接続を作成し、「Oracle」タブを選択して、接続情報とウォレット情報を入力します。Autonomous Data Warehouseをまだプロビジョニングしていない場合は、すぐにこれを実施してください。簡単にスタートするためのステップは、こちらを参照してください。無料トライアルのアカウントで始めることもできます。

これらを保存する前に、RedshiftとAutonomous Data Warehouseの両方の接続をテストします。
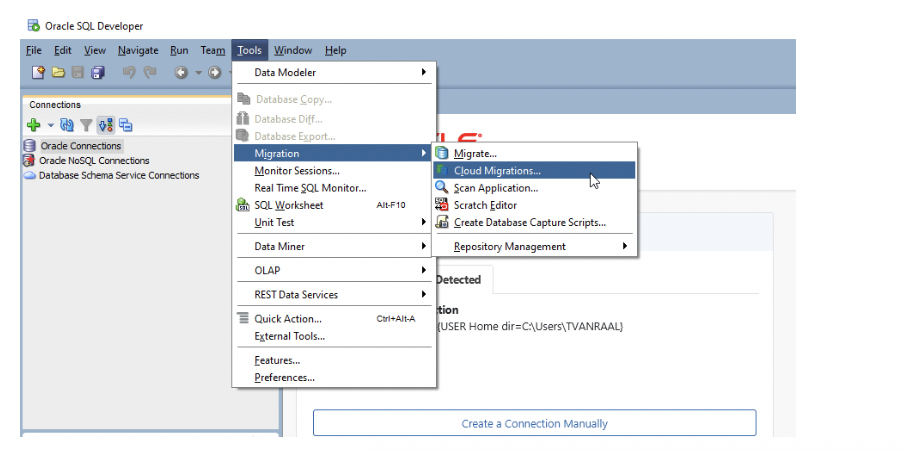
2.スキーマのキャプチャ/マップ:SQL Developerの「ツール」メニューからクラウド移行ウィザードを起動して、移行元データベース(Amazon Redshift)からメタデータのスキーマと表をキャプチャします。
まず、接続プロファイルからAWS Redshiftに接続し、移行する必要のあるスキーマを指定します。スキーマにあるすべてのオブジェクト(おもに表)が移行されます。データを移行するオプションもあります。Autonomous Data Warehouseへの移行は、スキーマ単位で行われます。スキーマ名を移行の一環として変更することはできません。
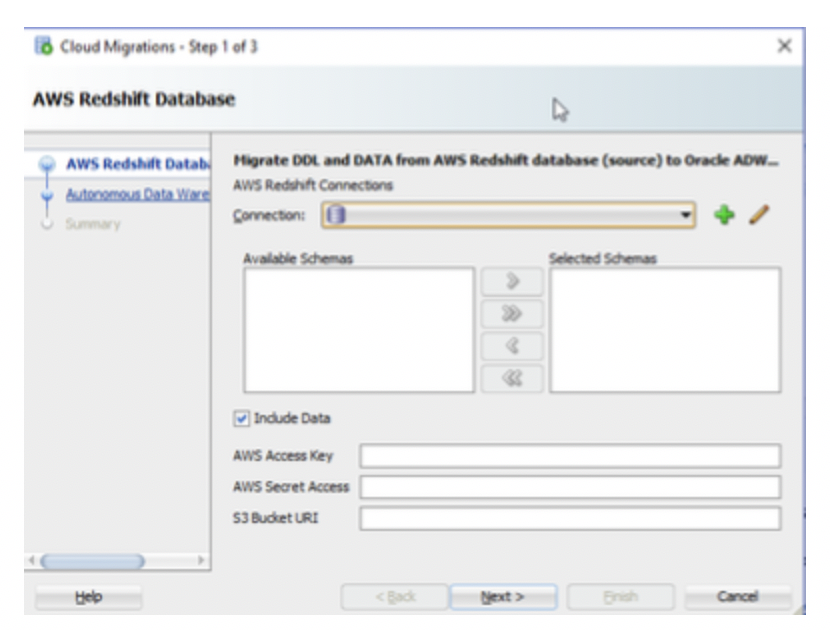
注:データを移行する際は、AWSアクセス・キー、AWS秘密アクセス・キー、Redshiftデータをアンロード[KI1] およびステージングする既存のS3バケットURIを指定する必要があります。セキュリティ資格証明には、S3にデータを格納するための権限が必要です。可能なら、移行用の個別のアクセス・キーを新しく作成することをお薦めします。後でセキュアなRESTリクエストにてAutonomous Data Warehouseにデータをロードする際に、同じアクセス・キーを使用します。
たとえばURIをhttps://s3-us-west-2.amazonaws.com/my_bucketのように指定すると、
移行アシスタントによって、バケット「my_bucket」に「oracle_schema_name/oracle_table_name」というフォルダが作成されます。
“https://s3-us-west 2.amazonaws.com/my_bucket/oracle_schema_name/oracle_table_name/*.gz”
RedshiftのデータタイプがOracleのデータタイプにマップされます。同様に、Redshiftのオブジェクト名がOracleネーミング規則に基づいてOracle名に変換されます。Redshift関数を使用する列のデフォルトは、Oracleの同等の機能に置き換えられます。
3.スキーマの生成:接続プロファイルからAutonomous Data Warehouseに接続します。なお、この接続はスキーマとオブジェクトを作成するために移行全体で使用されるため、ユーザーには管理者権限が必要です。Autonomous Data Warehouseで作成される移行レポジトリのパスワードを入力します。このレポジトリは、移行完了後に削除することができます。移行に必要な生成済スクリプトを格納するための、ローカル・システムのディレクトリを指定します。すぐに移行を開始する場合は、「今すぐ移行」を選択します。
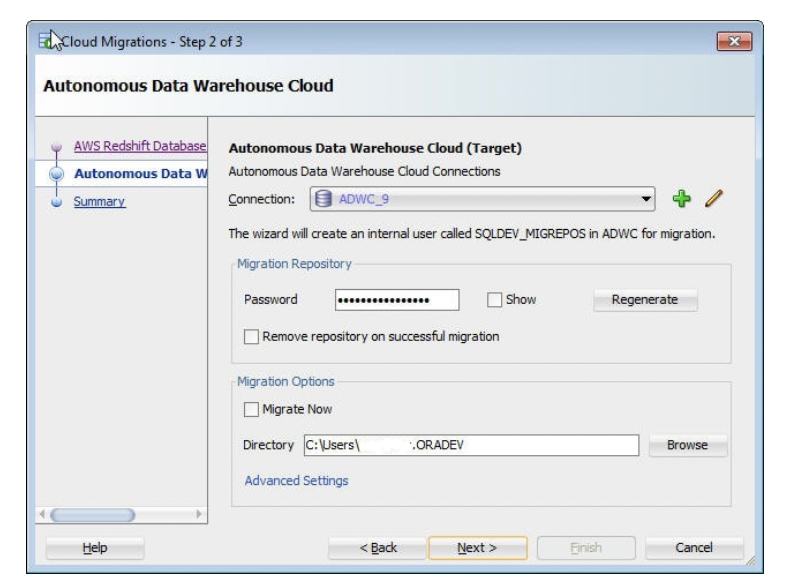
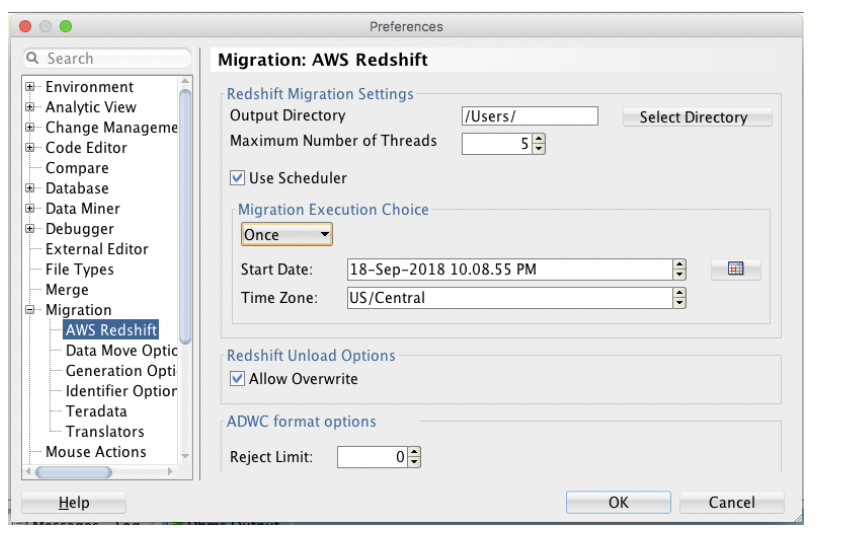
フォーマットのオプション、データをロードする際に有効化するパラレル・スレッド、移行時の拒否制限(拒否する行数のこと。この行数に達するとエラーが発生します)を制御するには、「拡張設定」を使用します。
サマリーを確認し、「終了」をクリックします。即時移行を選択した場合、移行が完了するまで移行ウィザードは開かれたままになります。即時移行を選択しなかった場合、必要なスクリプトが指定したローカル・ディレクトリに生成されるのみで、スクリプトは実行されません。
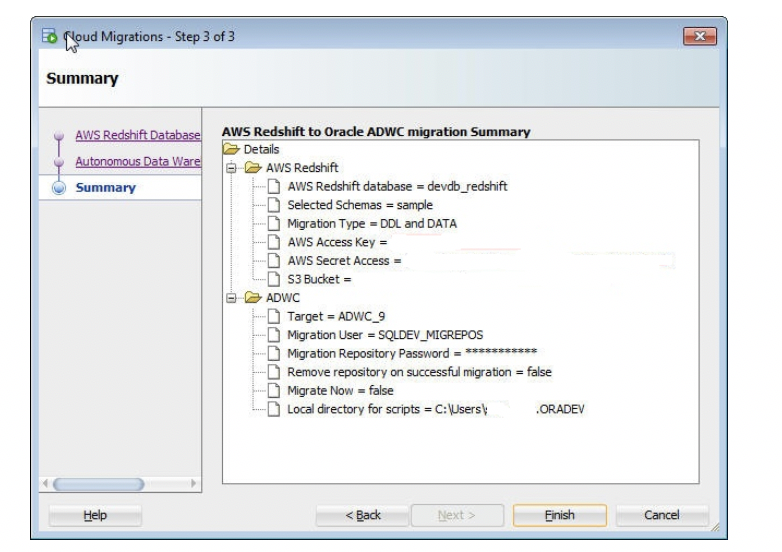
ローカル・ディレクトリに移行スクリプトを生成することを選択した場合は、次のステップに進みます。
- データのステージング:アクセス資格証明および移行ウィザードのワークフローで指定したS3バケットを使用して、Redshiftの表からデータをアンロードし、そのデータをAmazon Storage S3に格納する(ステージング)には、Amazon Redshift環境に接続して、redshift_s3unload.sqlを実行します。
- 移行先スキーマのデプロイ:生成したスキーマとAmazon Redshiftから変換したDDLをデプロイするには、権限を持つユーザー(ADMINなど)としてAutonomous Data Warehouseに接続し、adwc_ddl.sqlを実行します。
- データのコピー:Autonomous Data Warehouseに接続されている間に、adwc_dataload.sqlを実行します。このスクリプトには、S3からAutonomous Data Warehouseにデータをロードするために必要なすべてのロード・コマンドが含まれています。
- 移行結果の確認:移行タスクではローカル・ディレクトリに3つのファイル(MigrationResults.log、readme.txt、redshift_migration_reportxxx.txt)が作成されます。それぞれのファイルには、移行のステータスに関する情報が入っています。
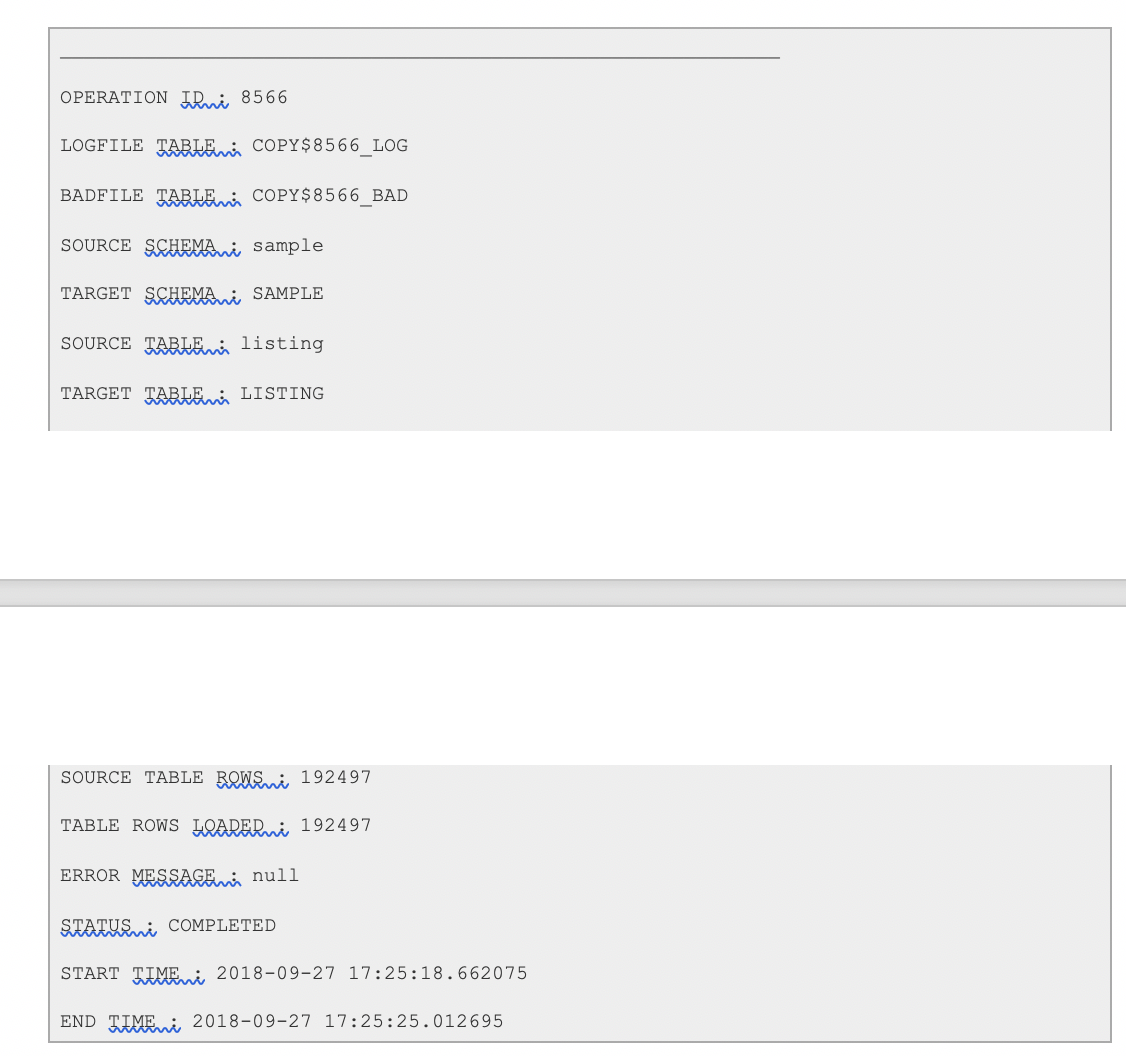
問合せをいくつかテストし、Amazon Redshiftからすべてのデータが移行されていることを確認します。Oracle Autonomous Data Warehouseでは、さまざまなクライアント・アプリケーションからの接続をサポートしています。接続して、それらをテストしてみましょう。
まとめ
優れた柔軟性、インフラストラクチャ・コストの削減、オペレーション・オーバーヘッドの縮小など、Oracle Autonomous Data Warehouseには数々の優れたメリットがあります。こうしたOracleならではの価値は、インフラストラクチャ・サービス、プラットフォーム・サービス、アプリケーションといった各レイヤーからもたらされるインテリジェンスを活用できる、オラクルの総合的なクラウド・ポートフォリオから創出されています。オラクルにとって、オートノマス(自律型)エンタープライズとは、自動化されたリアクションに基づいてマシンがアクションに反応するような単なる自動化の枠を超えたものであり、応用された機械学習に基づき、完全な自律を可能にし、ヒューマン・エラーを排除し、これまでにないパフォーマンス、高度なセキュリティ、信頼性をクラウドにて実現するものです。
AutonomousDatabaseを無期限 / 無料(Always Free)で使用可能になりました。
Cloudをまだお試しでない方は、無料トライアルをご利用下さい。

※本記事は、Kiran Makarla (Marketing Director, Autonomous Databases) による”Migrate from Amazon Redshift to Oracle Autonomous Data Warehouse in 7 easy steps “を翻訳したものです。