As we promised in our previous post, we are starting a blog series describing all of new Optimizer and statistics related functionality on Oracle Database 12c. We begin the series with an in-depth look at adaptive plans, one of the key features in the new adaptive query optimization framework. I want to thank Allison Lee for all her help with this post.
The goal of adaptive plans is to avoid catastrophic behavior of bad plans on the first execution. If we detect during execution that the optimizer’s cardinality estimates were wrong, then some plan choices can be changed “on the fly” to better options. While we can’t completely change the plan during execution, there are certain local decisions that can be changed, like join method. In this post, we’ll introduce the concepts and terminology related to adaptive plans, and then goes through an example in detail.
Concepts and Terminology
An adaptive plan allows certain decisions in a plan to be postponed until runtime, in case runtime conditions different from optimizer assumptions. For the purposes of explaining concepts, we will consider a plan for a simple two table join, where the join method is adapted. The diagram below shows the two options for this plan.
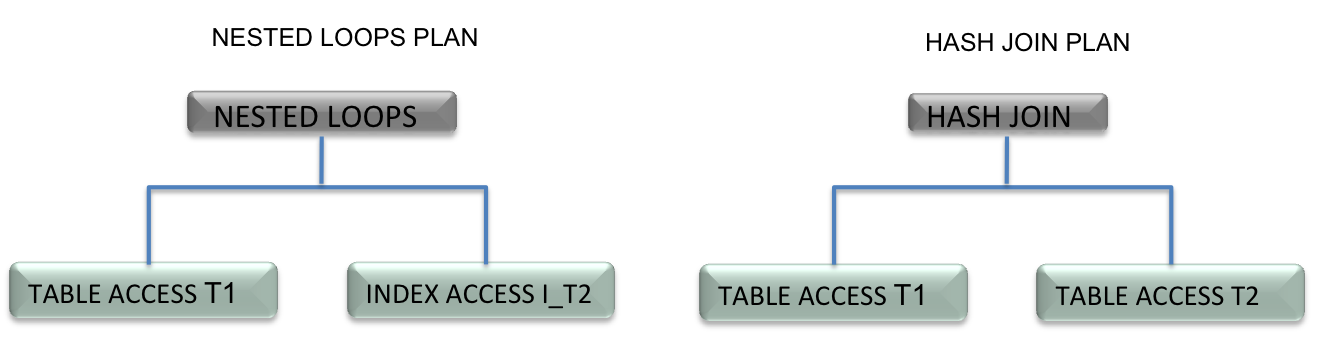
An adaptive plan consists of a default plan, which is the plan that the optimizer picks based on the current statistics, as well as alternatives to various portions of the plan. In our example join, let’s assume the default is the nested loops plan, and the alternative is the hash join. Each alternative portion of a plan is referred to as a “subplan”. A subplan is a set of related operations in a plan. For instance, the nested loops operation and the index scan consist of one subplan; the alternative subplan consists of the hash join node and the table scan on the right of it.For each decision that can be adapted, the plan contains two or more alternative subplans. During execution, one of those alternatives is chosen to be used, in a process called “adaptive plan resolution”. Adaptive plan resolution occurs on the first execution of a plan; once the plan is resolved, future executions of the same child cursor will use the same plan.
In order to resolve the plan, statistics are collected at various points during execution. The statistics collected during one part of execution are used to resolves parts of the plan that run later. For instance, statistics can be collected during the scan of table T1, and based on those statistics, we can choose the right join method for the join between T1 and T2. The statistics are collected using a “statistics collector”. Since the join of T1 to T2, and the scan of T1 would typically be pipelined, buffering is required in order to collect the statistics, resolve the choice of join method, and then perform the join. Some plan decisions can be adapted without buffering rows, but for adaptive joins, we require a “buffering statistics collector”.
The optimizer determines what statistics are to be collected, and how the plan should be resolved for different values of the statistics. The optimizer computes an “inflection point” which is the value of the statistic where the two plan choices are equally good. For instance, if the nested loops join is optimal when the scan of T1 produces fewer than 10 rows, and the hash join is optimal when the scan of T1 produces more than 10 rows, then the inflection point for these two plans is 10. The optimizer computes this value, and configures a buffering statistics collector to buffer and count up to 10 rows. If at least 10 rows are produced by the scan, then the join method is resolved to hash join; otherwise it is resolved to nested loops join.
We refer to the plan that is chosen by resolution as the “final plan”. The plan that the optimizer expects to be chosen (based on its estimates) is the “default plan”. The physical plan actually contains all of the operations from all of the subplan options; we refer to this as the “full plan”. As the plan is resolved, the plan hash value changes to indicate the new choice of plan. The plan that is displayed by our plan display APIs (in DBMS_XPLAN) changes as the plan is resolved. At any given point, some plan decisions may have been resolved, while others have not. For the unresolved plan choices, the plan display APIs show the plan that is expected by the optimizer (based on its estimates).
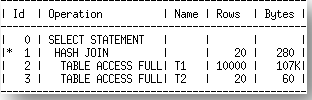
When EXPLAIN PLAN generates a query plan, none of the adaptive subplans have been resolved, so we see the default plan when displaying the plan through DBMS_XPLAN.DISPLAY. For example, if the optimizer thinks that nested loops join plan is best, then EXPLAIN PLAN and DBMS_XPLAN.DISPLAY would display the nested loops join plan as shown below.

During execution, suppose that the plan resolves to a hash join instead. Then the plan displayed by DBMS_XPLAN.DISPLAY_CURSOR would show the final plan, containing the hash join with full table scan on the right.