During the first execution of a SQL statement, an execution plan is generated as usual. During optimization, certain types of estimates that are known to be of low quality (for example, estimates for tables which lack statistics or tables with complex predicates) are noted, and monitoring is enabled for the cursor that is produced. If statistics feedback monitoring is enabled for a cursor, then at the end of execution, some of the statistics estimates in the plan are compared to the actual statistics seen during execution. If some of these estimates are found to differ significantly from the actual statistics, the correct estimates are stored for later use. The next time the query is executed, it will be optimized again, and this time the optimizer uses the corrected estimates in place of its usual estimates.
Consider the following query:
select product_name from order_items o, product_information p where o.unit_price = 15 and quantity > 1 and p.product_id = o.product_id;
The combination of an equality filter predicate and an inequality filter predicate causes a misestimation in the cardinality of the ORDER_ITEMS table after these filters are applied. The optimizer chooses the following plan:
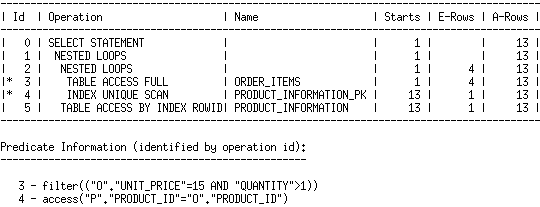
We can see from the execution statistics (A-Rows column in the plan) that the cardinality of order_items is underestimated. On the next execution, the actual cardinality is fed back to the optimizer, and this time the optimizer gets the cardinality estimate right, and chooses a different plan:
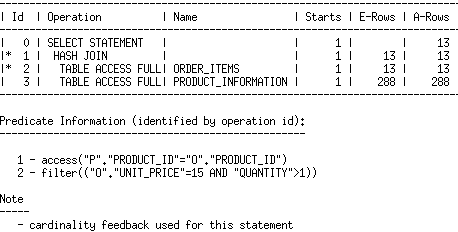
We can tell that statistics feedback was used because it appears in the note section of the plan. Note that you can also determine this by checking the USE_FEEDBACK_STATS column in V$SQL_SHARED_CURSOR.
Statistics feedback monitoring may be enabled in the following cases: tables with no statistics, multiple conjunctive or disjunctive filter predicates on a table, and predicates containing complex operators that the optimizer cannot accurately compute selectivity estimates for. In some cases, there are other techniques available to improve estimation; for instance, dynamic sampling or multi-column statistics allow the optimizer to more accurately estimate selectivity of conjunctive predicates. In cases where these techniques apply, statistics feedback is not enabled. However, if multi-column statistics are not present for the relevant combination of columns, the optimizer can fall back on statistics feedback.
Statistics feedback is useful for queries where the data volume being processed is stable over time. For a query on volatile tables, the first execution statistics are not necessarily reliable. This feature is not meant to evolve plans over time as the data in the table changes; it is meant to address queries where the plan is not correct to begin with. For similar reasons, execution statistics for queries containing bind variables can be problematic. In statistics feedback, we limit the feedback to portions of the plan whose estimates are not affected by bind variables. For instance, if a table has a filter comparing a column to a bind value, the cardinality of that table will not be used. However, statistics feedback can still be used for cardinalities elsewhere in the plan.
Statistics feedback monitors and feeds back the following kinds of cardinalities:
- Single table cardinality (after filter predicates are applied)
- Index cardinality (after index filters are applied)
- Cardinality produced by a group by or distinct operator
- Cardinality produced by joins (in Oracle Database 12c when optimizer adaptive features/statistics = TRUE)
The cardinalities that can be observed during an execution depend on the shape of a plan. So it is possible that on the second execution of a query, after generating a new plan using statistics feedback, there are still more cardinality estimates that are found to deviate significantly from the actual cardinalities. In this case, we can reoptimize yet again on the next execution. However, we have safeguards in place to guarantee that this will stabilize after a small number of executions. So you may see your plan changing in the first few executions, but then we eventually pick one and stick with it on all subsequent executions.
The improved estimates used by cardinality feedback are not persisted. For this reason, it’s always preferable to use other techniques to get cardinality estimates right the first time every time, e.g. extended statistics, dynamic sampling, or SQL profiles. But for cases where these techniques do not apply, cardinality feedback can provide some relief.
