Most of you will be familiar with the concept of direct path load and how it’s an efficient way to load large volumes of data into an Oracle database as well as being a great technique to use when moving and transforming data inside the database. It’s easy to use in conjunction with parallel execution too, so you can scale out and use multiple CPUs and database servers if you need to process more data in less time.
Probably less well known is how the Oracle database manages space during direct path load operations. This is understandable because the Oracle database uses a variety of approaches and it has not always been very obvious which one it has chosen. The good news is that Oracle Database 12c from version 12.1.0.2 onwards makes this information visible in the SQL execution plan and it is also possible to understand what’s happening inside earlier releases with a bit of help from this post and some scripts I’ve linked to at the end.
Why isn’t there a one-size-fits-all approach for space management? Simply put, direct path load has to work well in a wide variety of different circumstances. It is used to fill non-partitioned and partitioned tables, which means that it must work well with a small or large number of database segments. It must operate serially or in parallel, be confined to a single database instance or distributed across an entire RAC database.There are some subtle complexities to take into account too, such as data skew. For example, some table partitions might contain much more data than others. Successful parallel execution depends on the even distribution of workloads across a number of parallel execution servers. If this isn’t the case then some of the servers will finish early, leaving them with no useful work to do. This results in a low effective degree of parallelism, poor machine resource utilization and an extended elapsed time. Avoiding issues associated with data skew increases the complexity of space management because it’s usually not appropriate to simply map each parallel execution server to an individual database segment.
The strategies Oracle uses are designed to achieve excellent scalability in a wide variety of circumstances, avoiding the extended run times associated with skewed datasets. In this post I will focus on how the strategies work without delving too deeply into how the database makes its choice. I will explain space management using Oracle Database 11g Release 2 as the baseline and then I will introduce the changes we’ve made in Oracle Database 12c. To put things in perspective, a full rack Oracle Exadata Database Machine is capable of loading data at over 20 terabytes an hour, so you can be sure that space management has received some attention! Even if you don’t have a system like that at your disposal, you will still benefit from the improvements and optimizations Oracle makes to keep your database operating at its full potential.
High Water Mark (HWM) Loading
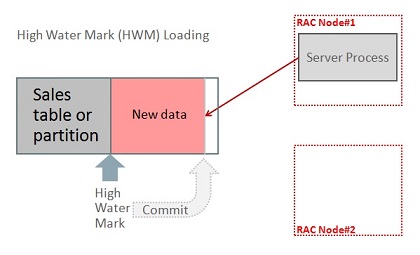
High water mark (HWM) loading is perhaps the simplest and most intuitive data load mechanism. For example, it is the default approach if you load data serially into a table like this:
ALTER SESSION DISABLE PARALLEL DML; INSERT /*+ APPEND */ INTO sales_copy t1 SELECT ...;
The new data is inserted into extents allocated above the table (or partition) high water mark. Rows above the high water mark will not be scanned by queries, so the new data remains invisible until the transaction is committed, whereupon the high water mark is moved to incorporate the extents containing the new data.
High water mark loading can be used whenever an Oracle process has exclusive access to the segment. This happens for serial load, parallel loads which distribute by the partition key (PKEY distribution) and “equi-partition” loads. For example, an equi-partition load will map parallel execution servers to particular partitions in the target table, where it will be responsible for loading all of the data from the corresponding partition in the source table. Equi-partition loading will be chosen automatically if you copy data in parallel between two equi-partitioned tables, but only if the tables have a relatively large number of partitions. There’s more on the producer/consumer model for parallel execution and the meaning of all of the terminology used here in the Oracle documentation and the parallel execution fundamentals white paper.
The following diagram represents a serial high water mark load on a 2-node RAC cluster. Rows are shown filling from left-to-right and on commit, the high water mark is moved up to the right to incorporate the new data:
Temp Segment Merge (TSM) Loading
Temp segment merge (TSM) loading was the first mechanism used to achieve parallel data loading in Oracle and is the default mechanism for parallel loads into single segments in Oracle Database 11g Release 2 (although AutoDOP uses something different, see later).
For example, the following parallel load statements in Oracle Database 11g will result in a temp segment merge load:
Parallel Create Table As Select (PCTAS) for a non-partitioned table:
CREATE TABLE sales_copy PARALLEL 8 AS SELECT * FROM sales;
Parallel Insert Direct Load (PIDL) into a non-partitioned table or a single partition:
INSERT /*+ APPEND PARALLEL(t1,8) */ INTO sales_copy_nonpart t1 SELECT ...; INSERT /*+ APPEND PARALLEL(t1,8) */ INTO sales_copy partition (part_p1) t1 SELECT ...;
When a parallel data load begins, each parallel execution server producer is allocated to a single temporary segment to populate. The temporary segments will reside in the same tablespace as the table or partition being loaded, and at commit time the temporary segments will be merged with the base segment by manipulating the extent map. In other words, the temporary segments will be incorporated into the table or partition without moving the data a second time.
The following diagram represents a parallel degree 4, temp segment merge load on a 2-node RAC cluster:

Temp segment merge loading scales very well with degree of parallelism (DOP) because each parallel execution server (PX server) is dedicated to its own temporary segment, so there is a good deal of isolation between each of the processes that are loading data. You can expect that a higher DOP will give you more performance until (usually) CPU or storage becomes the limiting factor. However, there is a potential downside; each temporary segment will become at least one table extent when it is made part of the table or partition. For example, if we load at DOP 16 then we’ll usually add at least 16 new extents to the table even if the number of rows is relatively small. It is important to be aware of this for the following reasons:
- Segment extent maps are read by query coordinators when parallel execution is initiated, so tables or partitions that have an extremely large number of extents can take longer to query and update in parallel than an identical table or partition with fewer extents.
- Extent trimming can sometimes leave gaps between extents that may be too small for new extents to be created and used. This is commonly referred to as external fragmentation.
- If you are using UNIFORM extent allocation then extents will not be trimmed. In this case, the final extent created for each temporary segment will be partially empty (unless the new rows just happen to fit exactly into the allocated extent). Statistically, 50% of the space for the last extent in each temporary segment will be empty when the load completes. For example, a temp segment merge load of DOP 8 into 1MB uniform extents will, on average, under populate the final extents in each of the 8 temporary segments by 0.5MB (1MB*50%) – or 4MB in total (0.5MB * 8). If data is only loaded into a table using direct path load, then this space will remain unused. This is commonly referred to as internal fragmentation and in this example, 4MB of space per load is effectively wasted unless rows are also loaded into the segment using conventional path INSERT.
These downsides can be mitigated if you load large volumes of data relatively infrequently rather than small amounts of data frequently.
High Water Mark Brokering (HWMB)
High water mark brokering (HWMB) may be used if multiple PX servers can potentially fill the same table or partition segment. It is often used when executing direct path loads into multiple partitions for both Oracle Database 11g and 12c, like this:
INSERT /*+ APPEND PARALLEL(t1,8) */ INTO sales_copy_partitioned t1 SELECT ...;
It is also the default for single-segment loads in Oracle Database 11g if Auto DOP is used (i.e. a load into a non-partitioned table or a specific table partition).
In common with high water mark loading, new row data is added directly to base segments above the high water mark. Depending on the DOP and the type of parallel execution plan chosen by the Oracle Optimizer, multiple PX servers may need to insert row data into the same database segment. In this situation, it becomes necessary for the new position of the high water mark to be coordinated or “brokered” between multiple processes and even multiple database servers. Brokering is implemented using database HV enqueues. Each segment has its own HV enqueue, which is used to record the position that the high water mark must be moved to once the transaction is committed. The enqueue ensures that multiple processes can’t update the high water mark position value at the same time.
The following diagram represents a DOP 4 high water mark brokered load on a single instance. Rows are shown filling from left-to-right, and on commit the high water mark is moved up to the right to incorporate the new data:

In general, HWMB results in fewer extents being added to the table (or partition) segment than temp segment merging. This advantage is especially significant in systems that load data frequently and those that leverage high DOP to reduce data load elapsed times.
Oracle Database 12c: Hybrid TSM/HWMB
The changes we have made in Oracle Database 12c release 12.1.0.1 improve the scalability of parallel direct path load, particularly when it’s used to populate single database segments such as non-partitioned tables or individual table partitions. This change is particularly important in high performance environments which move and transform data between non-partitioned tables and individual table partitions. It is also beneficial in environments that make use of partition exchange loading, where non-partitioned tables are populated before being incorporated into a partitioned table using a partition exchange operation.
Before we look at how the new approach works, here’s an Oracle Database 12c example that demonstrates the new behavior:
INSERT /*+ APPEND PARALLEL(t1,8) */ INTO sales_copy t1 /* sales_copy is not partitioned */ SELECT /*+ PARALLEL(t2,8) */ * FROM sales t2;
The execution plan in 12.1.0.2 will look something like this:
---------------------------------------------------------------------------------------------------------------------------- | Id | Operation | Name | Rows | Bytes | Cost (%CPU)| Time | TQ |IN-OUT| PQ Distrib | ---------------------------------------------------------------------------------------------------------------------------- | 0 | INSERT STATEMENT | | | | 74 (100)| | | | | | 1 | PX COORDINATOR | | | | | | | | | | 2 | PX SEND QC (RANDOM) | :TQ10000 | 999K| 8789K| 74 (2)| 00:00:01 | Q1,00 | P->S | QC (RAND) | | 3 | LOAD AS SELECT (HYBRID TSM/HWMB)| | | | | | Q1,00 | PCWP | | | 4 | OPTIMIZER STATISTICS GATHERING | | 999K| 8789K| 74 (2)| 00:00:01 | Q1,00 | PCWP | | | 5 | PX BLOCK ITERATOR | | 999K| 8789K| 74 (2)| 00:00:01 | Q1,00 | PCWC | | |* 6 | TABLE ACCESS FULL | SALES | 999K| 8789K| 74 (2)| 00:00:01 | Q1,00 | PCWP | | ----------------------------------------------------------------------------------------------------------------------------
There is a decoration in the SQL execution plan that you won’t have seen prior to Oracle Database 12c: HYBRID TSM/HWMB. As the name suggests, this is a hybrid solution that combines the beneficial characteristics of temp segment merge and high water mark brokering. Note that Oracle database release 12.1.0.1 will use the same execution plan but it won’t show the new decoration.
The primary motivation for this new approach is that high water mark brokering has a disadvantage if a large DOP is used to insert data into a single database segment. The single HV enqueue will need to be updated frequently, introducing a potential point of contention which will become more significant if PX servers are distributed across a Real Application Clusters (RAC) environment. Serializing access to a “busy” HV enqueue over an entire cluster can be time consuming, so in Oracle Database 12c we combine high water mark brokering with temp segment merge to eliminate cross-instance contention for HV enqueues while keeping down the number of new extents that need to be created per load operation.
I will illustrate how Hybrid TSM/HWMB works when parallel loading data into a non-partitioned table or single partition, since this is where you are most likely to encounter the optimization. When the parallel load operation is initiated, a temporary segment is created for each instance involved in the load (there will be two segments for a 2-node RAC cluster if the parallel insert operation is distributed across the cluster). Each temporary segment can be loaded by multiple PX servers, but the database will ensure that each temporary segment will be loaded by PX servers from a single instance. In this way, the HV enqueue associated with each temporary segment is brokered locally for each database instance and does not need to be brokered across the entire cluster.
The following diagram represents a DOP 4 Hybrid TSM/HWMB load on a 2-node RAC cluster:

To summarize, the benefits of Oracle Database 12c Hybrid TSM/HWMB are:
- Improved scalability; especially significant in high DOP and RAC deployments.
- Fewer table extents; especially significant if frequent, high DOP data loads are used.
- Reduced risk of “bloating” table extent maps and suffering from an associated degradation in PX performance.
In Oracle Database 12c:
- Parallel create table as select, INSERT and MERGE operations use Hybrid TSM/HWMB instead of temp segment merge for single segment loads. It is used in both Auto DOP and manual DOP environments.
- Temp segment merge continues to be available for some partitioned table parallel create table as select operations because this approach is highly scalable and (since it is a one-time operation) it avoids the potential downsides related to space fragmentation and extent bloat.
- Hybrid TSM/HWMB is used instead of temp segment merge for some partitioned table parallel create table as select operations.
- Space management decorations are clearly shown in execution plans for parallel load operations from database version 12.1.0.2. LOAD AS SELECT is decorated with “TEMP SEGMENT MERGE”, “HIGH WATER MARK BROKERED”, “HIGH WATER MARK”, “HYBRID TSM/HWMB” or “EQUI-PARTITION”.
Examples and Proof Points
If you’d like to see some examples, or would like to try this out for yourself, I’ve uploaded some scripts to GitHub. In particular you will see a comparison between Oracle Database 11g and 12c, showing the reduced number of extents created per load in 12c.
If you have any questions or problems with the scripts, or if you think they can be improved then let me know in the comments and I will update them.
Final Word
This post is in memory of my colleague Allen Brumm.
