- Index-based plans can improve performance dramatically. If you don’t already believe that, check out our post on star transformation for one example.
- Index maintenance causes overhead to DML, which causes some customers to avoid indexes.
- In many systems, only a small portion of the data is actively updated via DMLs.
Table expansion allows the optimizer to generate a plan that uses indexes on the read-mostly portion of the data, but not on the active portion of the data. Hence, DBAs can configure a table so that an index is only created on the read-mostly portion of the data, and will not suffer the overhead burden of index maintenance on the active portions of the data.
This is the high-level idea of what table expansion does. In practice, the way we can delineate active and inactive portions of the data is using partitioning. A local index can be defined on a table, and marked unusable for certain partitions. The partitions for which the index is unusable are in effect not indexed.
Partition Pruning and Index Access
In order to understand the kinds of plans generated by table expansion, it helps to know a bit about partition pruning, and how the optimizer decides what partitions to access and how. The optimizer keeps track of what partitions need to be accessed from each table, based on predicates that appear in the query. Let’s look at a simple example, using the SALES table from the Oracle sample schema SH. This table is range partitioned on TIME_ID. Consider query Q1, which has a filter on that column.
Q1
SELECT *
FROM sales
WHERE time_id >= TO_DATE(‘2000-01-01 00:00:00’, ‘SYYYY-MM-DD HH24:MI:SS’)
AND prod_id = 38;
The optimizer can determine from that filter that only 16 of the 28 partitions in the table need to be accessed. We see this in the “Pstart” and “Pstop” columns of the plan:
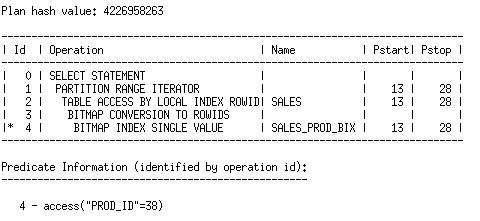
Once the optimizer has determined which partitions will be accessed, it will consider any index that is usable on all of those partitions. In the plan above, the optimizer chose to use an index, SALES_PROD_BIX. Let’s see what happens to the plan for Q1 if we disable the index on a partition of the SALES table.
alter index SALES_PROD_BIX modify partition SALES_1995 unusable;
This disables the index on the first partition (partition 1), which contains all sales from before 1996. Note that you can find this information in USER_IND_PARTITIONS.
If we generate the plan for Q1 again, we see that we get the same plan.
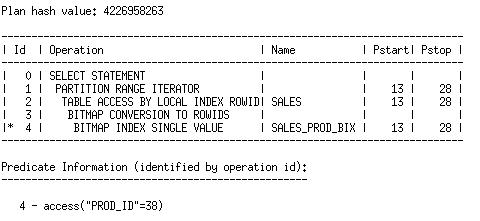
This is because the index partition that we removed is not relevant to our query. As long as all of the partitions we access are indexed, we can answer the query with the index. Since we only access partitions 16 through 28, disabling the index on partition 1 does not affect the plan.
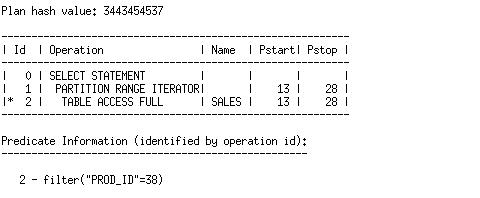
If we disable the index on a partition that we do need to access, we can no longer use that index (absent table expansion). For instance, let’s look at the plan after we disable the index for partition 28 (SALES_Q4_2003). Recall from the above plans that this is one of the partitions that we do access in the query.
alter index SALES_PROD_BIX modify partition SALES_Q4_2003 unusable;
How Table Expansion Can Help
In the above example, our query accesses 16 partitions. On 15 of those partitions, there is an index available, but there is no index available for the final partition. Since the optimizer has to choose one access path or the other, we cannot make use of the index on any of the partitions. This is what table expansion is meant to solve. Table expansion allows the optimizer to optimize the partitions that are indexed separately from those which are not, by accessing each in a separate query block. The above query can be rewritten as follows:
Q2
SELECT *
FROM sales
WHERE time_id >= TO_DATE(‘2000-01-01 00:00:00’, ‘SYYYY-MM-DD HH24:MI:SS’)
AND time_id < TO_DATE(‘ 2003-10-01 00:00:00’, ‘SYYYY-MM-DD HH24:MI:SS’)
AND prod_id = 38
UNION ALL
SELECT *
FROM sales
WHERE time_id >= TO_DATE(‘2000-01-01 00:00:00’, ‘SYYYY-MM-DD HH24:MI:SS’)
AND time_id >= TO_DATE(‘ 2003-10-01 00:00:00’, ‘SYYYY-MM-DD HH24:MI:SS’)
AND prod_id = 38;
The first query block in the union all accesses the partitions that are indexed, while the second query block accesses the partition which is not. This allows the optimizer to choose to use the index in the first query block, if that is more optimal than using a table scan of all of the partitions that are accessed. Here is the plan with table expansion enabled:
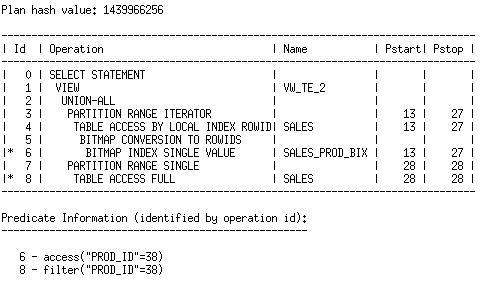
With table expansion, the optimizer can choose the most efficient access method available for a partition, whether it exists for all of the partitions accessed in the query or not. The optimizer may also choose different join methods, join orders, etc. across the branches of the union-all query block.
A More Interesting Example
In a recent post, we discussed the virtues of star transformation. Star transformation can be a huge win for certain kinds of queries, since it allows us to avoid accessing large portions of big fact tables. The only downside is that it requires defining several indexes. In an actively updated table, this can have some overhead. In the past, this has scared some users away from creating the indexes necessary to trigger star transformation. With table expansion, you have the option of defining these indexes on just the inactive partitions, and the optimizer can consider star transformation on the indexed portions of the table.
Consider a slightly modified version of the query from the star transformation post:
Q3
SELECT t.calendar_quarter_desc, SUM(s.amount_sold) sales_amount
FROM sales s, times t, customers c, channels ch
WHERE s.time_id = t.time_id
AND s.cust_id = c.cust_id
AND s.channel_id = ch.channel_id
AND c.cust_state_province = ‘CA’
AND ch.channel_desc = ‘Internet’
AND t.calendar_quarter_desc IN (‘1999-01′,’1999-02’)
GROUP BY t.calendar_quarter_desc;
Suppose the last partition of SALES is actively being updated (as is often the case with time-partitioned tables). So we disable the indexes on the last partition:
alter index SALES_CHANNEL_BIX modify partition SALES_Q4_2003 unusable;
alter index SALES_CUST_BIX modify partition SALES_Q4_2003 unusable;
The optimizer chooses table expansion, and the union-all branch accessing all but the last partition uses star transformation. The final partition is accessed via a table scan.
When Table Expansion Is Not Chosen
We will not always choose table expansion when a table and its indexes are setup this way. First, table expansion is cost-based, since it is not always optimal. While the partitions of the expanded table are each accessed only once (across all branches of the union-all), any tables that are joined to it will be accessed in each branch. We discussed this concern in our recent post on OR-expansion, which is quite similar to table expansion in terms of the query shape that is generated, and the restrictions on its usefulness.
For example, the star transformation example above was slightly modified from the query in the original post, because for the original query it is not cost-effective to use table expansion. The join back to customers (required due to a column from that table appearing in the SELECT and GROUP BY clauses) is so expensive that repeating the join to that table in both branches is more expensive than using the non-star transformation plan for the entire table. Join factorization may improve the table expansion plan in this case. We’ll discuss this interaction between transformations in a post in the next few months.
There are also several semantic reasons that it may not be valid to expand a table in this manner. For instance, a table appearing on the right side of an outer join is not valid to expand.
The transformation can be controlled with the hint EXPAND_TABLE(<table alias>), e.g. EXPAND_TABLE(s) for Q3. The hint will override the cost-based decision, but not the semantic checks.
Summary
Table expansion allows users to take advantage of index-based plans for tables that may have high update volume. Users can define an index scheme where only older, read-mostly data are indexed, and the optimizer will consider using the index even when some of the data accessed are not indexed.
