We have gotten a lot of questions recently regarding how to gather and maintain optimizer statistics on large partitioned tables. The majority of these questions can be summarized into two topics:
- When queries access a single partition with stale or non-existent partition level statistics I get a sub optimal plan due to “Out of Range” values
- Global statistics collection is extremely expensive in terms of time and system resources
This article will describe both of these issues and explain how you can address them both.
This is big topic so I recommend that you also check out the three-part series of posts on maintaining incremental statistics in partitioned tables.
Out of Range
Large tables are often decomposed into smaller pieces called partitions in order to improve query performance and ease of data management. The Oracle query optimizer relies on both the statistics of the entire table (global statistics) and the statistics of the individual partitions (partition statistics) to select a good execution plan for a SQL statement. If the query needs to access only a single partition, the optimizer uses only the statistics of the accessed partition. If the query access more than one partition, it uses a combination of global and partition statistics.
“Out of Range” means that the value supplied in a where clause predicate is outside the domain of values represented by the [minimum, maximum] column statistics. The optimizer prorates the selectivity based on the distance between the predicate value and the maximum value (assuming the value is higher than the max), that is, the farther the value is from the maximum value, the lower the selectivity will be. This situation occurs most frequently in tables that are range partitioned by a date column, a new partition is added, and then queried while rows are still being loaded in the new partition. The partition statistics will be stale very quickly due to the continuous trickle feed load even if the statistics get refreshed periodically. The maximum value known to the optimizer is not correct leading to the “Out of Range” condition. The under-estimation of selectivity often leads the query optimizer to pick a sub optimal plan. For example, the query optimizer would pick an index access path while a full scan is a better choice.
The “Out of Range” condition can be prevented by using the new copy table statistics procedure available in Oracle Database10.2.0.4 and 11g. This procedure copies the statistics of the source [sub] partition to the destination [sub] partition. It also copies the statistics of the dependent objects: columns, local (partitioned) indexes etc. It adjusts the minimum and maximum values of the partitioning column as follows; it uses the high bound partitioning value as the maximum value of the first partitioning column (it is possible to have concatenated partition columns) and high bound partitioning value of the previous partition as the minimum value of the first partitioning column for range partitioned table. It can optionally scale some of the other statistics like the number of blocks, number of rows etc. of the destination partition.
Assume we have a table called SALES that is ranged partitioned by quarter on the SALES_DATE column. At the end of every day data is loaded into latest partition. However, statistics are only gathered at the end of every quarter when the partition is fully loaded. Assuming global and partition level statistics (for all fully loaded partitions) are up to date, use the following steps in order to prevent getting a sub-optimal plan due to “out of range”.
1. Lock the table statistics using LOCK_TABLE_STATS procedure in DBMS_STATS. This is to avoid interference from auto statistics job.EXEC DBMS_STATS.LOCK_TABLE_STATS('SH','SALES'); 2. Before beginning the initial load into each new partition (say SALES_Q4_2000) copy the statistics from the previous partition (say SALES_Q3_2000) using COPY_TABLE_STATS. You need to specify FORCE=>TRUE to override the statistics lock.
EXEC DBMS_STATS.COPY_TABLE_STATS ('SH', 'SALES', 'SALES_Q3_2000', 'SALES_Q4_2000', FORCE=>TRUE);
Expensive global statistics collection
In data warehouse environment it is very common to do a bulk load directly into one or more empty partitions. This will make the partition statistics stale and may also make the global statistics stale. Re-gathering statistics for the effected partitions and for the entire table can be very time consuming. Traditionally, statistics collection is done in a two-pass approach:
- In the first pass we will scan the table to gather the global statistics
- In the second pass we will scan the partitions that have been changed to gather their partition level statistics.
The full scan of the table for global statistics collection can be very expensive depending on the size of the table. Note that the scan of the entire table is done even if we change a small subset of partitions.
We avoid scanning the whole table when computing global statistics by deriving the global statistics from the partition statistics. Some of the statistics can be derived easily and accurately from partition statistics. For example, number of rows at global level is the sum of number of rows of partitions. Even global histogram can be derived from partition histograms. But the number of distinct values (NDV) of a column cannot be derived from partition level NDVs. So, Oracle maintains another structure called a synopsis for each column at the partition level. A synopsis can be considered as sample of distinct values. The NDV can be accurately derived from synopses. We can also merge multiple synopses into one. The global NDV is derived from the synopsis generated by merging all of the partition level synopses. To summarize:
- Gather statistics and create synopses for the changed partitions only
- Oracle automatically merges partition level synopses into a global synopsis
- The global statistics are automatically derived from the partition level statistics and global synopses
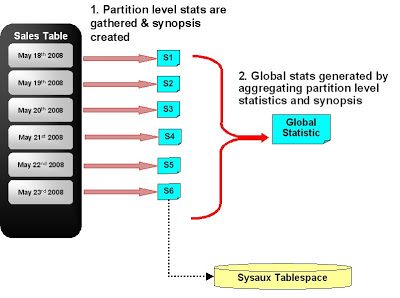
Incremental maintenance feature is disabled by default. It can be enabled by changing the INCREMENTAL table preference to true. It can also be enabled for a particular schema or at the database level.
Assume we have table called SALES that is range partitioned by day on the SALES_DATE column. At the end of every day data is loaded into latest partition and partition statistics are gathered. Global statistics are only gathered at the end of every month because gathering them is very time and resource intensive. Use the following steps in order to maintain global statistics after every load.
Turn on incremental feature for the table.
EXEC DBMS_STATS.SET_TABLE_PREFS('SH','SALES','INCREMENTAL','TRUE'); At the end of every load gather table statistics using GATHER_TABLE_STATS command. You don’t need to specify the partition name. Also, do not specify the granularity parameter. The command will collect statistics for partitions where data has change or statistics are missing and update the global statistics based on the partition level statistics and synopsis.
EXEC DBMS_STATS.GATHER_TABLE_STATS('SH','SALES');
Note: that the incremental maintenance feature was introduced in Oracle Database 11g Release 1. However, we also provide a solution in Oracle Database10g Release 2 (10.2.0.4) that simulates the same behavior. The 10g solution is a new value, ‘APPROX_GLOBAL AND PARTITION’ for the GRANULARITY parameter of the GATHER_TABLE_STATS procedures. It behaves the same as the incremental maintenance feature except that we don’t update the NDV for non-partitioning columns and number of distinct keys of the index at the global level. For partitioned column we update the NDV as the sum of NDV at the partition levels. Also we set the NDV of columns of unique indexes as the number of rows of the table. In general, non-partitioning column NDV at the global level becomes stale less often. It may be possible to collect global statistics less frequently then the default (when table changes 10%) since approx_global option maintains most of the global statistics accurately.