Hi visitor. This blog post was originally written in 2012. I still serves as a good introduction to incremental statistics. Once you’ve read it, there’s now more on this topic here (part one of a three-part series).
Incremental statistics maintenance was introduced in Oracle Database 11g to improve the performance of gathering statistics on large partitioned table. When incremental statistics maintenance is enabled for a partitioned table, Oracle accurately generated global level statistics by aggregating partition level statistics. As more people begin to adopt this functionality we have gotten more questions around how they expected incremental statistics to behave in a given scenario. For example, last week we got a question around what partitions should have statistics gathered on them after DML has occurred on the table?
The person who asked the question assumed that statistics would only be gathered on partitions that had stale statistics (10% of the rows in the partition had changed). However, what they actually saw when they did a DBMS_STATS.GATHER_TABLE_STATS was all of the partitions that had been affected by the DML had statistics re-gathered on them. This is the expected behavior, incremental statistics maintenance is suppose to yield the same statistics as gathering table statistics from scratch, just faster. This means incremental statistics maintenance needs to gather statistics on any partition that will change the global or table level statistics. For instance, the min or max value for a column could change after just one row is inserted or updated in the table. It might easier to demonstrate this using an example.
Let’s take the ORDERS2 table, which is partitioned by month on ORDER_DATE. We will begin by enabling incremental statistics for the table and gathering statistics on the table.
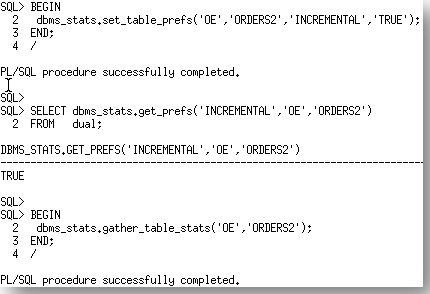
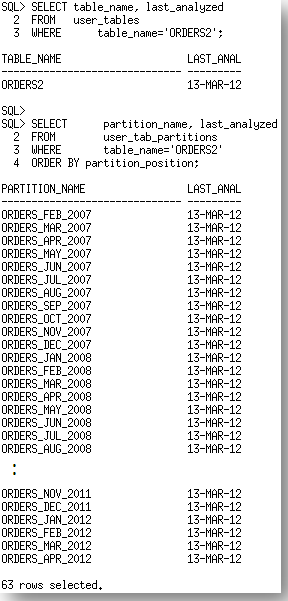
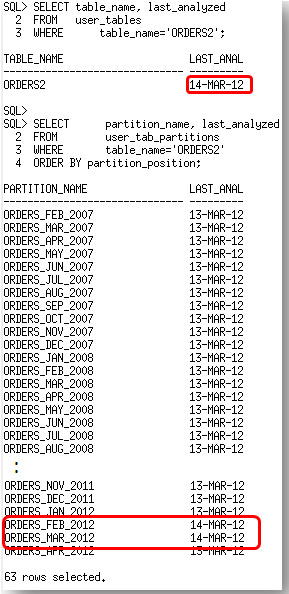
After the statistics gather the last_analyzed date for the table and all of the partitions now show 13-Mar-12.
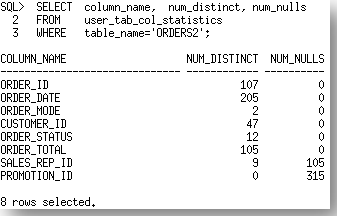
And we now have the following column statistics for the ORDERS2 table.
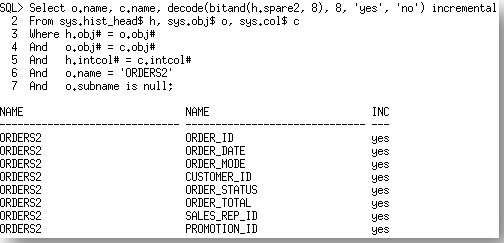
We can also confirm that we really did use incremental statistics by querying the dictionary table SYS.HIST_HEAD$, which should have an entry for each column in the ORDERS2 table.
So, now that we have established a good baseline, let’s move on to the DML. Information is loaded into the latest partition of the ORDERS2 table once a month. Existing orders maybe also be update to reflect changes in their status. Let’s assume that a large number of update transactions take place on the ORDERS2 table this month. After these transactions have occurred we need to re-gather statistic since the partition ORDERS_MAR_2012 now has rows in it and the number of distinct values and the maximum value for the STATUS column have also changed.
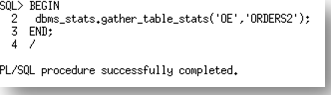
Now if we look at the last_analyzed date for the table and the partitions, we will see that the global statistics and the statistics on the partitions where rows have changed due to the update (ORDERS_FEB_2012) and the data load (ORDERS_MAR_2012) have been updated.
The column statistics also reflect the changes with the number of distinct values in the status column increase to reflect the update.
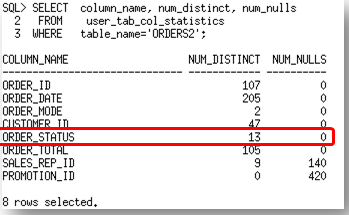
So, incremental statistics maintenance will gather statistics on any partition, whose data has changed and that change will impact the global level statistics.
You can get a copy of the script I used to generate this post here.
As I mentioned at the beginning, there more on this topic here (this is part one of a three-part series).
