There are a number of ways to speed up the process of gathering optimizer statistics, but I’m not sure that it’s common knowledge just how much of an effect some simple changes can make. If you have been asking yourself, “why is stats gathering taking so long and what can I do about it?”, then this post is for you.
If you are already familiar with the different methods of gathering optimizer statistics, you might want to jump to the end of this post where I compare them and make some recommendations.
Overview
The perception that it’s difficult to speed up statistics gathering has sometimes motivated DBAs to manipulate the number of rows sampled on a table-by-table basis using the ESTIMATE_PERCENT parameter (or DBMS_STATS preference). For example, large tables may have estimate percent set to 1% and small tables, 100%. Legacy scripts play their part too: some systems are still using procedures established before the performance enhancements available with auto sample size. One of the reasons we recommend ESTIMATE_PERCENT=>AUTO_SAMPLE_SIZE is that it includes number of distinct value (NDV) optimizations that yield high performance and accurate statistics. Gathering statistics using a 1% sample of rows might complete very quickly, but inaccurate statistics are the likely result, along with sub-optimal SQL execution plans.
Instead of manipulating ESTIMATE_PERCENT, the time taken to gather statistics can be reduced by using more machine resources. This post compares some before-and-after scenarios to demonstrate how you can do this. Fully worked examples are available in GitHub.
I will concentrate on using automatic optimizer statistics gathering, but the lessons are broadly applicable to manual statistics gathering too (there’s an example at the end of the post). The examples are intended for use on Oracle Database 12c and Oracle Database 18c. The same techniques are applicable to Oracle Database 11g, but note that the resource consumer groups have different names in that release.
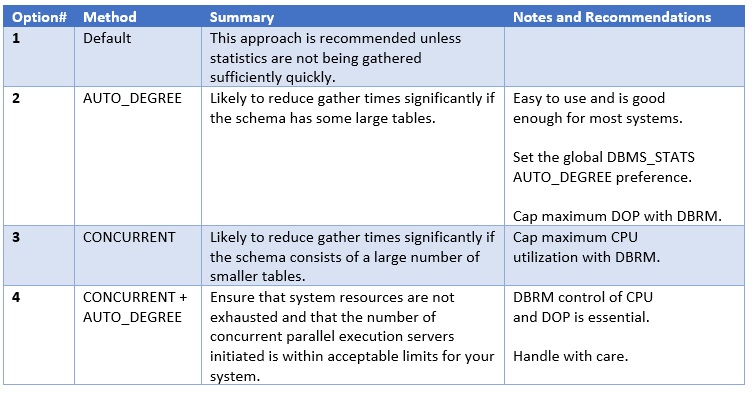
Option #1 – Default Statistics Gathering
Consider the following trace of CPU consumption over time:
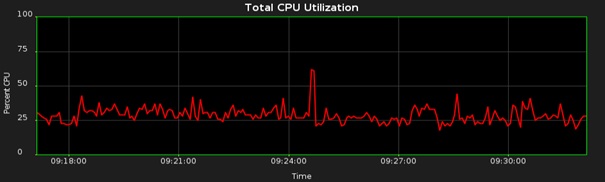
It shows my CPU utilization while the automatic statistics gathering job is running and there’s not much else happening on the system. Notice that about 75% of the CPU is not utilized. This fact is easy to understand once you know that the environment has a 4-core CPU with one thread per core. By default, statistics gathering uses a single process (with a single worker-thread) and this will utilize the processing power of a single CPU core. In my case, this equates to a utilization of 25% (one quarter of the 4-core chip). For systems with a higher core count, the single process will utilize an even smaller proportion of the available CPU.
Gathering statistics like this is not necessarily a problem. If stats gathering runs to completion most nights and there’s no urgent need to have fresh statistics by a certain time, then there’s no need to do anything more. Always keep things as simple as possible and only make changes if you need to. If your environment is large and/or volatile, the auto statistics job might regularly fail to run to completion in the batch window. In other words, the window might close before all tables considered stale have fresh statistics. If this is the case, then some tables might remain stale for a long time.
Fortunately, this situation is easy to see. If you view the statistics advisor report available in Oracle Database 12c Release 2, then it will tell you. The data dictionary stored this information too. In the example below, my batch window is 20 minutes long and the auto stats job has sometimes failed to complete (status STOPPED). The JOB_INFO column reveals the reason: auto statistics collection is occasionally taking longer than 20 minutes and terminates when the batch window closes.
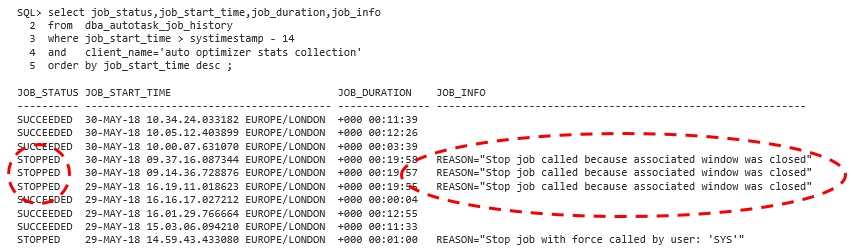
How can we fix this? We could (a) make the batch window longer and/or (b) speed up statistics gathering. I am going to consider option b (because option a is less interesting).
How do you speed up statistics gathering? If you have resources on your database server, then you could dedicate more of it to gather statistics. You can reduce the elapsed time of gathering statistics at the cost of a more fully utilized database server. It is of course necessary to identify a window of time where there’s spare system resource, so this solution requires that the system is not running at 100% all of the time.
It is worth noting that other techniques are available to reduce the time required to maintain statistics (such as incremental statistics maintenance), but this is out of scope for the purposes of this blog post.
Option #2 – Gathering Statistics in Parallel – AUTO_DEGREE
Gathering statistics with auto sample size initiates full table scans to inspect table data. We can leverage parallel execution to make these scans complete in less time. To do this you can, for example, identify large tables and define a specific degree of parallelism (DOP):
exec dbms_stats.set_table_prefs(user, 'BIG_TABLE', 'DEGREE', 16)
There is an easier, set-and-forget approach where you can let Oracle to decide on the DOP for you:
exec dbms_stats.set_table_prefs(user, 'BIG_TABLE', 'DEGREE', DBMS_STATS.AUTO_DEGREE)
A clean and simple approach is to set the property at the global level:
exec dbms_stats.set_global_prefs('DEGREE', DBMS_STATS.AUTO_DEGREE)
With parallel execution in play, statistics gathering has the potential to consume lots of system resource, so you need to consider how to control this. When the auto stats gathering job executes it (by default) uses the resource management plan DEFAULT_MAINTENANCE_PLAN and a consumer group called ORA$AUTOTASK. This makes it very easy to make some adjustments and control just how much resource you want to dedicate to gathering statistics.
You first need to decide what priority to attribute to auto stats gathering depending on what other processes are likely to be running at the same time. In the following example, the auto stats job has a minimum of 5% CPU if other tasks running in the database are competing for CPU. However, if the system is not busy, we will allow the job to consume up to 80% of the CPU (this will protect processes that must run outside the control of the database). The maximum degree of parallelism an individual session can use is four in this case. It is useful to control the maximum DOP because you will want to make sure that you do not reach the maximum number of parallel server processes allowed for the system (this will become more relevant later in this post).

For completeness, the example above includes all plan directives for the DEFAULT_MAINTENANCE_PLAN, but it is only necessary to specify the plan directives you want to modify. By default, when the maintenance windows opens, it will activate the DEFAULT_MAINTENANCE_PLAN. If you prefer, you can create your own resource management plan and associate it with any maintenance windows of your choosing. If you also set the resource_management_plan initialization parameter, then you can use the same resource management plan when the batch windows are both open and closed. Here’s an example:

When AUTO_DEGREE is used the resource utilization can look very different . In this example, the tables are all identical so there’s a very regular pattern:
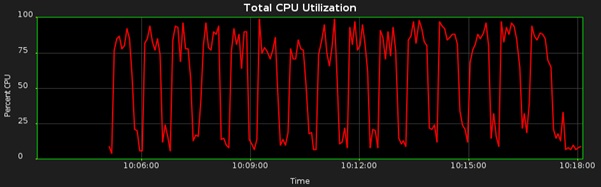
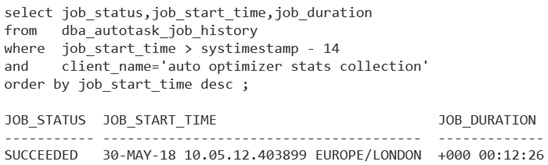
We are now using much more CPU, and consequently the job completes in only 12 minutes and 26 seconds (where, previously, it failed to complete within the 20-minute window):
Remember that database resource management (DBRM) is in force during the batch window, so it is very easy to adjust CPU utilization even while the job is running. For example – consider what happens when I adjust the utilization limit down from 80% to 40% and then back again:
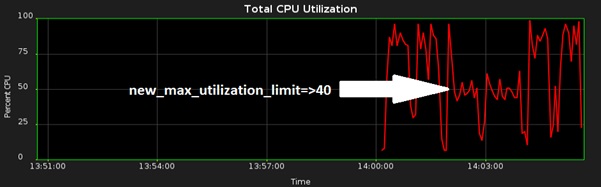
Let’s look at a more realistic AUTO_DEGREE scenario. In the following example we have a schema containing tables that have a wide variation in size. The CPU profile is now less consistent:
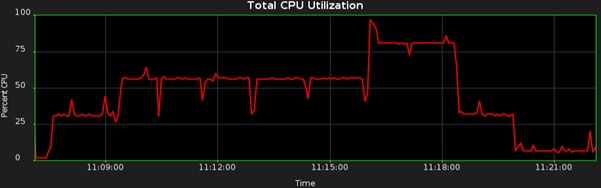
The DOP is changing in response to the size of each individual table. The job runs serially at first (about 25% CPU), then DOP 2 for a while, then DOP 3 and then back to serial. We could micro-manage DOP on a table-by-table basis, but it is much better to avoid approaches like this because we should always aim to avoid too much manual intervention. The global AUTO_DEGREE solution will be good enough in many cases, so there will be no need for any further manual intervention.
Option #3 – Gathering Statistics Concurrently – CONCURRENT
Parallel statistics gathering has enabled us to increase CPU utilization significantly, but what if we have spare machine resources and want to go even faster? In the previous example, the CPU could be more fully utilized. If you want to achieve that, then how do you go about it?
Firstly, disable parallel execution (we will come back to that later):
exec dbms_stats.set_global_prefs('DEGREE', 1)
The CONCURRENT preference allows DBMS_SCHEDULER to initiate multiple statistics gathering jobs at once, so that the database will gather statistics on multiple tables and partitions concurrently. We can choose to enable this behavior for auto stats gathering only:
exec dbms_stats.set_global_prefs('CONCURRENT','AUTOMATIC')
If you enable a database resource management plan, you can use concurrent for manual stats or for manual and auto:
exec dbms_stats.set_global_prefs('CONCURRENT','MANUAL')
exec dbms_stats.set_global_prefs('CONCURRENT','ALL')
The database will now gather statistics using multiple scheduler jobs. In my case, auto stats initiated 16 job processes and the CPU profile looked like this:
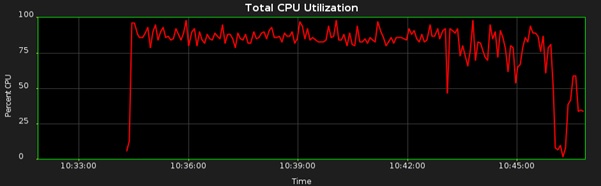
I am using max_utilization_limit set to 80%, and the job completes in 11 minutes and 39 seconds:

Concurrent statistics gathering works very well if tables are of a similar size, but without parallel execution, serial jobs running on very large tables can take a long time and the might not complete before the batch window closes. If this is a problem for you, you can use a combination of concurrent processing and parallel execution.
Option #4 – Gathering Statistics Concurrently and in Parallel – CONCURRENT and AUTO_DEGREE
Care is required when implementing concurrency and parallel execution because there’s scope to execute a very large number of concurrent parallel execution servers and generate a very high system load. Multiple jobs will start and each has the potential to initiate a number of parallel query servers. As a very general rule of thumb, you want to have no more than about 2*CPUCoreCount to 4*CPUCoreCount parallel servers executing at any one time.
You can mitigate the risk of initiating too many parallel execution servers as follows:
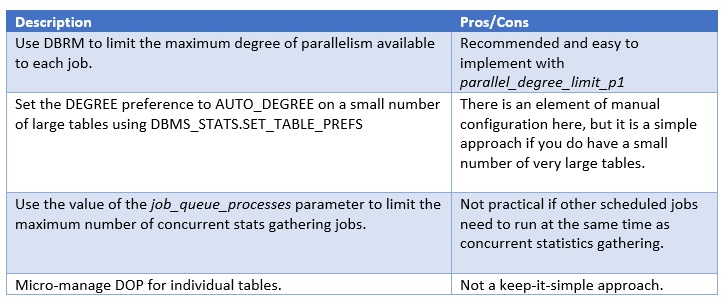
There is currently no way to cap the number of job queue processes allocated to concurrent stats gathering, so ‘turning down’ the job_queue_processes setting is the only way to do this. I have created an enhancement request with respect to this limitation.
Enable concurrent stats gathering for the automatic statistics gathering job:
exec dbms_stats.set_global_prefs('CONCURRENT','AUTOMATIC')
Set AUTO_DEGREE globally:
exec dbms_stats.set_global_prefs('DEGREE', DBMS_STATS.AUTO_DEGREE)
Or, for individual large tables:
exec dbms_stats.set_table_prefs(user, 'BIG_TABLE', 'DEGREE', DBMS_STATS.AUTO_DEGREE)
On my system, the auto stats initiated 16 job processes and the resource management plan I used limited DOP to four. This resulted in 64 parallel execution servers executing concurrently, so a DOP limited to two might have been a better choice in my case. Here is the new CPU profile:
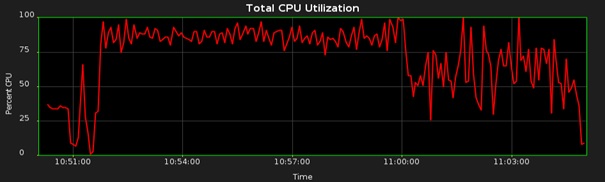
The job completed in 13 minutes 16 seconds:

In this case, why was there no benefit in run time using CONCURRENT and AUTO_DEGREE? It is because CONCURRENT without AUTO_DEGREE consumed CPU up to the 80% limit imposed by DBRM. In the more general case where there is a good mix of table sizes, some very large tables and a faster IO subsystem, then AUTO_DEGREE used in combination with CONCURRENT has the potential to yield the shortest gather stats times.
If you are in a position to be able to decrease job_queue_processes to limit the number of jobs that execute concurrently, then you will be able to increase the DOP limit to a higher values:

The same is true if there are only a small number of tables where parallelism is used.
Oracle Multitenant
At the time of writing, there was a bug with parallel statistics gathering in a multitenant database when used with CONCURRENT (bug# 27249531). Parallel execution servers initiated by gather stats are not constrained by max_utilization_limit. This can result in high CPU consumption. Using DEGREE above 1 or AUTO_DEGREE is OK if CONCURRENT is not used.
The bug is now marked fixed in 19.1. If your version or platform does not have this patch, the best solution is to use DEGREE=>1 if you want to use CONCURRENT in multitenant environments.
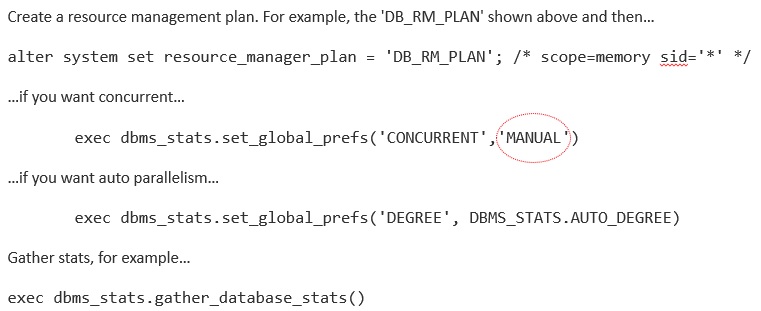
Manual Statistics Gathering
If you want to initiate stats gathering manually, and still make full use of parallel and concurrent settings, then you can use the following approach:
Performance Comparisons
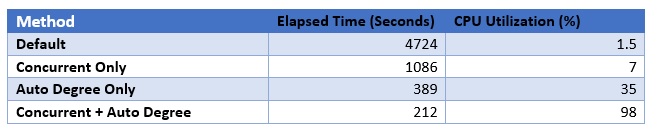
A small test system was used for the examples above, so it will be useful to see what an enterprise-class system looks like (let’s say 72 cores with HT). The Oracle Real World Performance Group ran some tests to check out the different techniques.
The relative performance of the stats gathering methods will be different on every system you try, so treat this as entertainment rather than science. For example, the test tables were all large and all the same size, so this will work in favor of AUTO_DEGREE (used without CONCURRENT) because a high degree of parallism was used for every table.
A large number of CPU cores will make the default method look exceptionally underpowered. In this case the CPU is only 1.5% utilized; a single core in an enterprise-class system:
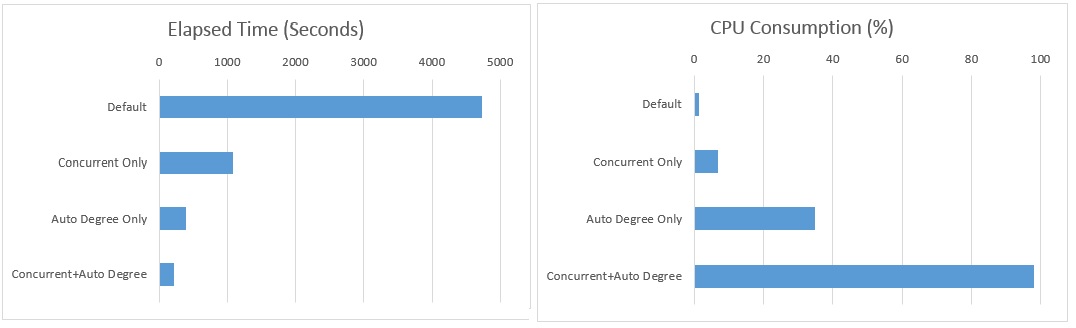
Here are the results plotted:
Summary
Remember that you will need spare machine capacity to gain benefit from the techniques outlined in this blog post.
Generally speaking, option #2 is most likely to give you a quick and easy win if there are a number of very large tables. Option #3 is great if you have plenty of spare machine resource and a large number of smaller tables.
Option #4 requires more care to avoid initiating too many parallel execution servers.
Options #3 and #4 are particularly useful if you need to get a one-off stats gathering task done very quickly: perhaps when you are commissioning a new deployment or gathering statistics after an upgrade.
Here’s a high-level summary:
I’ve uploaded self-contained test scripts to GitHub.
Comments welcome!
