I got an interesting question from one of my colleagues in the performance team last week about how to restrict a concurrent statistics gather to a small subset of tables from one schema, rather than the entire schema. I thought I would share the solution we came up with because it was rather elegant, and took advantage of concurrent statistics gathering, incremental statistics, and the not so well known “obj_filter_list” parameter in DBMS_STATS.GATHER_SCHEMA_STATS procedure. You should note that the solution outline below with “obj_filter_list” still applies, even when concurrent statistics gathering and/or incremental statistics gathering is disabled.
The reason my colleague had asked the question in the first place was because he wanted to enable incremental statistics for 5 large partitioned tables in one schema. The first time you gather statistics after you enable incremental statistics on a table, you have to gather statistics for all of the existing partitions so that a synopsis may be created for them. If the partitioned table in question is large and contains a lot of partition, this could take a considerable amount of time. Since my colleague only had the Exadata environment at his disposal overnight, he wanted to re-gather statistics on 5 partition tables as quickly as possible to ensure that it all finished before morning.
Prior to Oracle Database 11g Release 2, the only way to do this would have been to write a script with an individual DBMS_STATS.GATHER_TABLE_STATS command for each partition, in each of the 5 tables, as well as another one to gather global statistics on the table. Then, run each script in a separate session and manually manage how many of this session could run concurrently. Since each table has over one thousand partitions that would definitely be a daunting task and would most likely keep my colleague up all night!
Beginning with Oracle Database 11g Release 2 we can take advantage of concurrent statistics gathering, which enables us to gather statistics on multiple tables in a schema (or database), and multiple (sub)partitions within a table concurrently. By using concurrent statistics gathering we no longer have to run individual statistics gathering commands for each partition. Oracle will automatically create a statistics gathering job for each partition, and one for the global statistics on each partitioned table.
With the use of concurrent statistics, our script can now be simplified to just five DBMS_STATS.GATHER_TABLE_STATS commands, one for each table. This approach would work just fine but we really wanted to get this down to just one command. So how can we do that?
You may be wondering why we didn’t just use the DBMS_STATS.GATHER_SCHEMA_STATS procedure with the OPTION parameter set to ‘GATHER STALE’. Unfortunately the statistics on the 5 partitioned tables were not stale and enabling incremental statistics does not mark the existing statistics stale. Plus how would we limit the schema statistics gather to just the 5 partitioned tables?
So we went to ask one of the statistics developers if there was an alternative way. The developer told us the advantage of the “obj_filter_list” parameter in DBMS_STATS.GATHER_SCHEMA_STATS procedure. The “obj_filter_list” parameter allows you to specify a list of objects that you want to gather statistics on within a schema or database. The parameter takes a collection of type DBMS_STATS.OBJECTTAB. Each entry in the collection has 5 fields; the schema name or the object owner, the object type (i.e., ‘TABLE’ or ‘INDEX’), object name, partition name, and subpartition name. You don’t have to specify all five fields for each entry. Empty fields in an entry are treated as if it is a wildcard field (similar to ‘*’ character in LIKE predicates). Each entry corresponds to one set of filter conditions on the objects. If you have more than one entry, an object is qualified for statistics gathering as long as it satisfies the filter conditions in one entry.
You first must create the collection of objects, and then gather statistics for the specified collection. It’s probably easier to explain this with an example. I’m using the SH sample schema but needed a couple of additional partitioned table tables to get recreate my colleagues scenario of 5 partitioned tables. So I created SALES2, SALES3, and COSTS2 as copies of the SALES and COSTS table respectively (setup.sql). I also deleted statistics on all of the tables in the SH schema beforehand to more easily demonstrate our approach.
Step 0. Delete the statistics on the tables in the SH schema.

Step 1. Enable concurrent statistics gathering. Remember, this has to be done at the global level.

Step 2. Enable incremental statistics for the 5 partitioned tables.

Step 3. Create the DBMS_STATS.OBJECTTAB and pass it to the DBMS_STATS.GATHER_SCHEMA_STATS command.
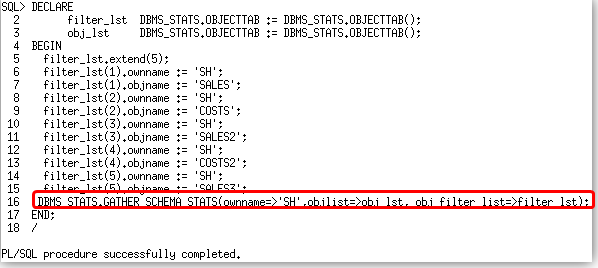
Here, you will notice that we defined two variables of DBMS_STATS.OBJECTTAB type. The first, filter_lst, will be used to pass the list of tables we want to gather statistics on, and will be the value passed to the obj_filter_list parameter. The second, obj_lst, will be used to capture the list of tables that have had statistics gathered on them by this command, and will be the value passed to the objlist parameter. In Oracle Database 11g Release 2, you need to specify the objlist parameter in order to get the obj_filter_list parameter to work correctly due to bug 14539274.
Will also needed to define the number of objects we would supply in the obj_filter_list. In our case we ere specifying 5 tables (filter_lst.extend(5)). Finally, we need to specify the owner name and object name for each of the objects in the list. Once the list definition is complete we can issue the DBMS_STATS.GATHER_SCHEMA_STATS command.
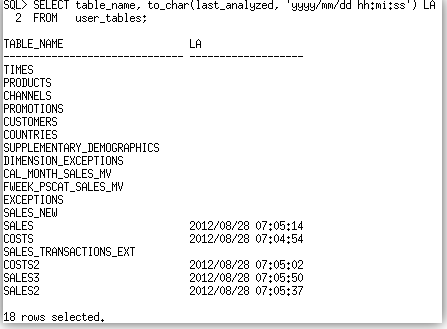
Step 4. Confirm statistics were gathered on the 5 partitioned tables.
Here are a couple of other things to keep in mind when specifying the entries for the obj_filter_list parameter.
- If a field in the entry is empty, i.e., null, it means there is no condition on this field. In the above example , suppose you remove the statement Obj_filter_lst(1).ownname := ‘SH’; You will get the same result since when you have specified gather_schema_stats so there is no need to further specify ownname in the obj_filter_lst.
- All of the names in the entry are normalized, i.e., uppercased if they are not double quoted. So in the above example, it is OK to use Obj_filter_lst(1).objname := ‘sales’;. However if you have a table called ‘MyTab’ instead of ‘MYTAB’, then you need to specify Obj_filter_lst(1).objname := ‘”MyTab”’;
As I said before, although we have illustrated the usage of the obj_filter_list parameter for partitioned tables, with concurrent and incremental statistics gathering turned on, the obj_filter_list parameter is generally applicable to any gather_database_stats, gather_dictionary_stats and gather_schema_stats command.
You can get a copy of the script I used to generate this post here.
