In our previous post we introduced extended statistics, which help the Optimizer improve the accuracy of cardinality estimates for SQL statements that contain predicates involving a function wrapped column (e.g. UPPER(LastName)) or multiple columns from the same table used in filter predicates, join conditions, or group-by keys. So extended statistics are extremely useful but how do you know which extended statistics should be created?
In Oracle Database 11.2.0.2 we introduced Auto Column Group Creation, which automatically determines which column groups are required for a table based on a given workload. Please note this functionality does not create extended statistics for function wrapped columns it is only for column groups. Auto Column Group Creation is a simple three step process:
1. Seed column usage
Oracle must observe a representative workload, in order to determine the appropriate column groups. Using the new procedure DBMS_STATS.SEED_COL_USAGE, you tell Oracle how long it should observe the workload. The following example turns on monitoring for 5 minutes or 300 seconds. This monitoring procedure records different information from the traditional column usage information you see in sys.col_usage$ and it is stored in sys.col_group_usage$.
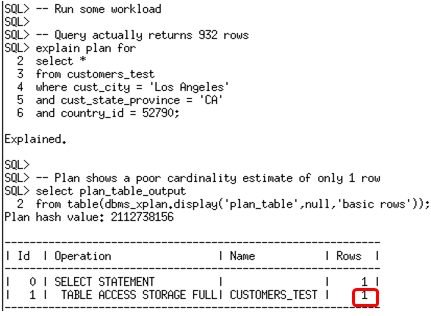
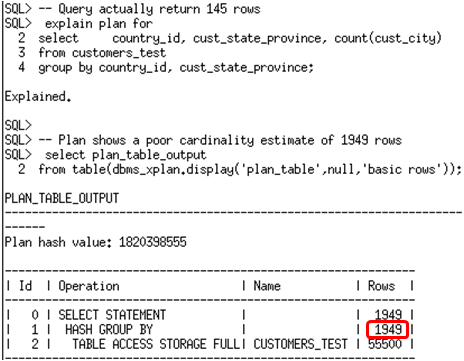
You don’t need to execute all of the queries in your work during this window. You can simply run explain plan for some of your longer running queries to ensure column group information is recorded for these queries. The example below uses two queries that run against the customers_test table (which is a copy of the customers table in the SH schema).

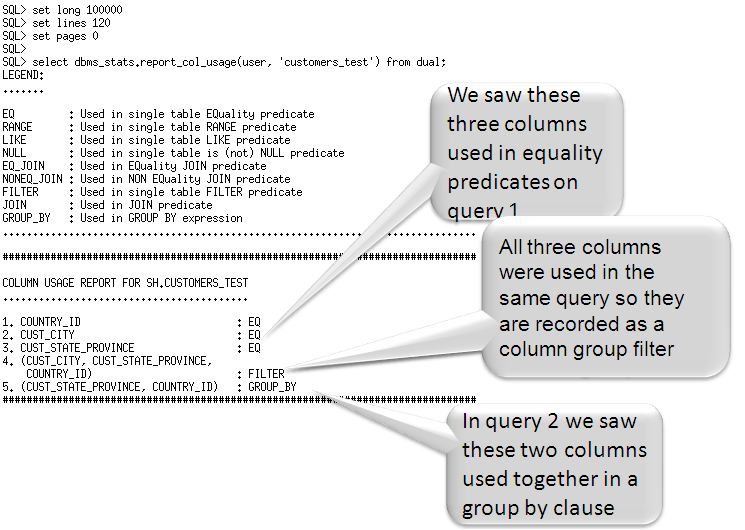
Once the monitoring window has finished, it is possible to review the column usage information recorded for a specific table using the new function DBMS_STATS.REPORT_COL_USAGE. This function generates a report, which lists what columns from the table were seen in filter predicates, join predicates and group by clauses in the workload.
It is also possible to view a report for all the tables in a specific schema by running DBMS_STATS.REPORT_COL_USAGE and providing just the schema name and NULL for the table name.
2. Create the column groups
At this point you can get Oracle to automatically create the column groups for each of the tables based on the usage information captured during the monitoring window. You simply have to call the DBMS_STATS.CREATE_EXTENDED_STATS function for each table.This function requires just two arguments, the schema name and the table name. From then on, statistics will be maintained for each column group whenever statistics are gathered on the table. In this example you will see two column groups were created based on the information captured from the two queries in this workload.

It is also possible to create all of the proposed column groups for a particular schema in one shot by running the DBMS_STATS.CREATE_EXTENDED_STATS function and passing NULL for the table name.
3. Regather statistics
The final step is to regather statistics on the affected tables so that the newly created column groups will have statistics created for them.

Once the statistics have been gathered you should check out the USER_TAB_COL_STATISTICS view to see what additional statistics were created. In this example you will see two new columns listed for the customers_test table. Both columns have system generated names, the same names that were returned from the DBMS_STATS.CREATE_EXTENDED_STATS function.

You will also notice that one of the column groups has a height-based histogram created on it. This column group was created on CUST_CITY, CUST_STATE_PROVINCE, and COUNTRY_ID. While monitoring column groups we also monitor the fact that histogram may be potentially useful for the column groups and subsequent statistics collection create a histogram for the group. So now that the column groups are in place, let’s see if they improved the cardinality estimates for the two queries we used in the monitoring window.
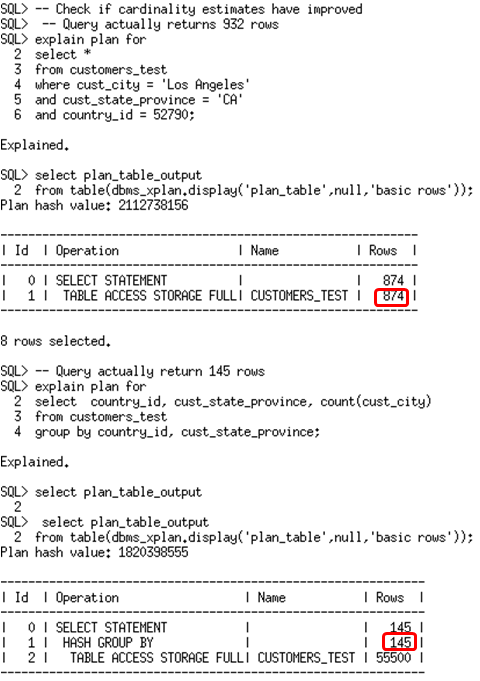
In both cases the cardinality estimate is far more accurate than without extended statistics.
Maria Colgan+