I recently spoke with a customer who has a development environment that is a tiny fraction of the size of their production environment. His team has been tasked with identifying problem SQL statements in this development environment before new code is released into production.
The problem is the objects in the development environment are so small, the execution plans selected in the development environment rarely reflects what actually happens in production.
To ensure the development environment accurately reflects production, in the eyes of the Optimizer, the statistics used in the development environment must be the same as the statistics used in production. This can be achieved by exporting the statistics from production and import them into the development environment. Even though the underlying objects are a fraction of the size of production, the Optimizer will see them as the same size and treat them the same way as it would in production.
Below are the necessary steps to achieve this in their environment. I am using the SH sample schema as the application schema who’s statistics we want to move from production to development.
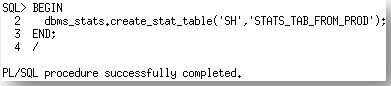
Step 1. Create a staging table, in the production environment, where the statistics can be stored
Step 2. Export the statistics for the application schema, from the data dictionary in production, into the staging table

Step 3. Create an Oracle directory on the production system where the export of the staging table will reside and grant the SH user the necessary privileges on it.

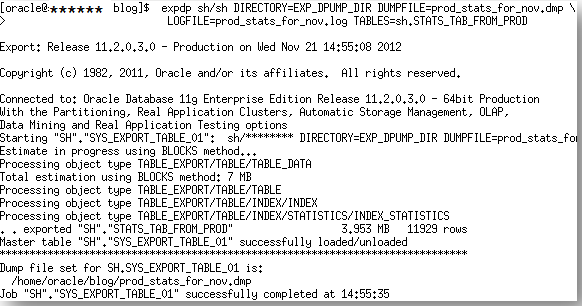
Step 4. Export the staging table from production using data pump export
Step 5. Copy the dump file containing the stating table from production to development
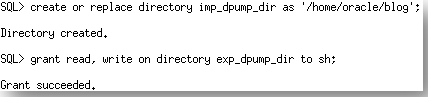
Step 6. Create an Oracle directory on the development system where the export of the staging table resides and grant the SH user the necessary privileges on it.
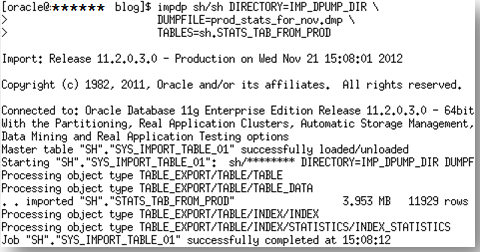
Step 7. Import the staging table into the development environment using data pump import
Step 8. Import the statistics from the staging table into the dictionary in the development environment.

You can get a copy of the script I used to generate this post here.
