This question came up recently when I was helping a customer upgrade a large data warehouse. Prior to the upgrade, they were using an ESTIMATE_PERCENT of 0.000001, the smallest possible sample size allowed, when they gathering statistics on their larger tables. When I asked why they picked such a tiny sample size they said it was because they needed statistics to be gathered extremely quickly after their daily load both at the partition and at the global level.
Since these large tables were partitioned, I thought they would be an excellent candidate for incremental statistics. However, in order to use incremental statistics gathering you have to let the ESTIMATE_PERCENT parameter default to AUTO_SAMPLE_SIZE. Although the customer saw the benefit of using incremental statistics they were not keen on changing the value of ESTIMATE_PERCENT. So I argued that with AUTO_SAMPLE_SIZE they would get statistics that were equivalent to a 100% sample but with the speed of a 10% sample. Since we would be using incremental statistics we would only have to gather statistics on the freshly loaded partition and the global statistics (table level statistics) would be automatically aggregated correctly.
So with much skepticism, they tried incremental statistics in their test system and they were pleasantly surprised at the elapse time. However, they didn’t trust the statistics that were gathered and asked me, “how do I compare the statistics I got with AUTO_SAMPLE_SIZE to the statistics I normally get with an ESTIMATE_PERCENT of 0.000001?”
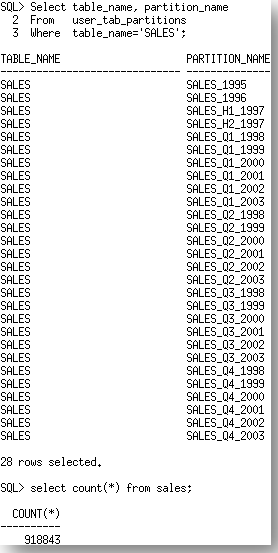
The answer to that was easy, ‘use DBMS_STAT.DIFF_TABLE_STATS’. Although the answer was easy, it wasn’t an easy process to help them to work out how to use the DBMS_STAT.DIFF_STATS functions correctly. In this post I hope to share some of the gotchas you many encounter using DIFF_STATS that are not so obvious. Let’s take the SALES table from the SH schema as an example. The SALES table has 28 partitions and 918843 rows.
First we will gather statistics on the SALES table with their original setting for ESTIMATE_PERCENT, 0.00001.
These statistics can now be backed up into a newly created stats table.
Now that we have an export of the statistics from the manually specified ESTIMATE_PERCENT run, let’s re-gather statistics on the SALES table using the default, AUTO_SAMPLE_SIZE.
So, we are now ready to compare the two sets of the statistics for the SALES table using the DBMS_STAT.DIFF_TABLE_STATS function. There are actually three version of this function depending on where the statistics being compared are located;
- DBMS_STAT.DIFF_TABLE_STATS_IN_HISTORY
- DBMS_STAT.DIFF_TABLE_STATS_IN_PENDING
- DBMS_STAT.DIFF_TABLE_STATS_IN_STATTAB
In this case we will be using the DBMS_STAT.DIFF_TABLE_STATS_IN_STATTAB function. The functions also compare the statistics of the dependent objects (indexes, columns, partitions) and will only displays statistics for the object(s) from both sources if the difference between the statistics exceeds a certain threshold (%). The threshold can be specified as an argument to the function; the default value is 10%. The statistics corresponding to the first source will be used as the basis for computing the differential percentage.
The DBMS_STAT.DIFF_TABLE_STATS functions are table functions so you must use the key word table when you are selecting from them, otherwise you will receive an error saying the object does not exist.

The table function returns a report (clob datatype) and maxdiffpct (number). In order to display the report correctly you must use the set long command to define the width of a long so the report can be displayed properly.

How that we know how to generate the report, let’s look at what it says,
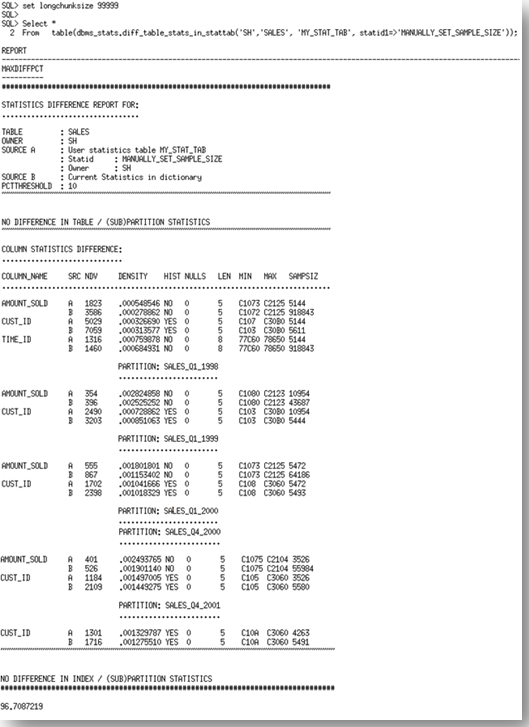
The report has three sections. It begins with a comparison of the basic table statistics. In this case the table statistics (number of rows, number of blocks etc) are the same. The results so far are to be expected since we can accurately extrapolate the table statistics from a very small sample. The second section of the report examines column statistics.
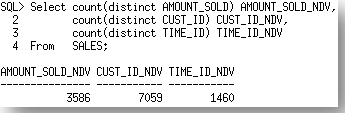
Each of the columns where the statistics vary is listed (AMOUNT_SOLD, CUST_ID, TIME_ID) along with a copy of the statistics values from each source. Source A is the STATTAB, which in our case is the ESTIMATE_PERCENT of 0.000001. Source B is the statistics currently in the dictionary, which in our case is the AUTO_SAMPLE_SIZE set. You will notice quite a significant difference in the statistics, especially in the NDV (number of distinct values) and the minimum and maximum values for each of the columns. If we compare these results with the actual number of distinct values for these (below), we see that the statistics reported by source B, the AUTO_SAMPLE_SIZE are the most accurate.
The report then goes on to list the column statistics differences for each of the partitions. In this section you will see that the problems occur only in the AMOUNT_SOLD, CUST_ID columns. The SALES table is range partitioned on TIME_ID, so there is a limited number of TIME_IDs in each partition, thus the percentage difference between the results on this level is not enough to meet the threshold of 10%.
Finally the report looks at the index statistics.In this case the index statistics were different but they were not greater than 10% different so the report doesn’t show them.
Along with the report the function returns the MAXDIFFPCT. This is the maximum percentage difference between the statistics. These differences can come from the table, column, or index statistics. In this case the MAXDIFFPCT was 96%!

So the statistics were significantly different with AUTO_SAMPLE_SIZE but the proof is in the pudding. We put the new statistics to the test and found that the Optimizer chose much better execution plan with the new statistics. So much so they were able to remove a ton of hints from their code that had been necessary previously due to poor statistics. You can’t ask for anything better than that!
You can get a copy of the script I used to generate this post here.
