In real-world data, there is often a relationship or correlation between the data stored in different columns of the same table. For example, consider a customers table where the values in a cust_state_province column are influenced by the values in a country_id column, because the state of California is only going to be found in the United States. If the Oracle Optimizer is not aware of these real-world relationships, it could potentially miscalculate the cardinality estimate if multiple columns from the same table are used in the where clause of a statement. With extended statistics you have an opportunity to tell the optimizer about these real-world relationships between the columns.
By creating extended statistics on a group of columns, the optimizer can determine a more accurate cardinality estimate when the columns are used together in a where clause of a SQL statement.You can use DBMS_STATS.CREATE_EXTENDED_STATS to define the column group you want to have statistics gathered on as a whole. Once the group has been established Oracle will automatically maintain the statistics on that column group when statistics are gathered on the table.
If we continue with the initial example of the customers table, When the value of cust_state_province is ‘CA’ we know the value of country_id will be 52790 or the USA. There is also a skew in the data in these two columns; because the company used in the SH is based in San Francisco so the majority of rows in the table have the values ‘CA’ and 52790. Both the relationship between the columns and the skew in the data can make it difficult for the optimizer to calculate the cardinality of these columns correctly when they are used together in a query.
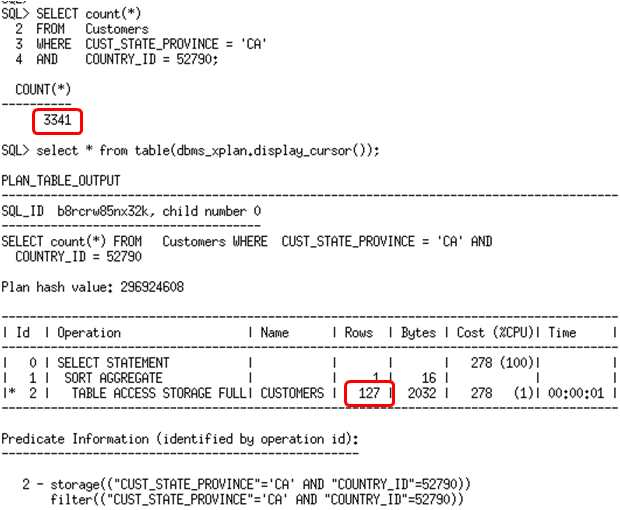
With just basic statistics we see the optimizer thinks there will only be 127 row returned because it assumes both columns will reduce the number of rows returned (# of rows in the table X 1/NDV of column1 X 1/NDV of column2). We know that this is not true in this case. We must provide better statistic to the optimizer so it can determine the correct cardinality estimate. Prior to Oracle Database 11g the only option open to us would be to make the optimizer aware of the data skew in both the country_id column (most rows have 52790 as the value) and the cust_state_province column (most rows have ‘CA’ as the value). We can do this by gathering histograms on the skewed columns.
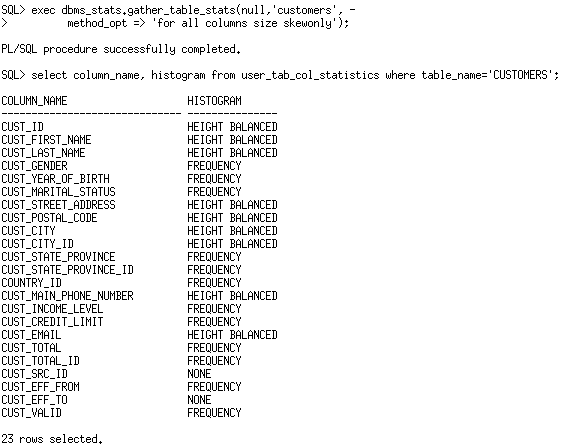
Now that we have histograms on both the country_id and the cust_state_province columns let’s see if the optimizers estimate is more accurate.
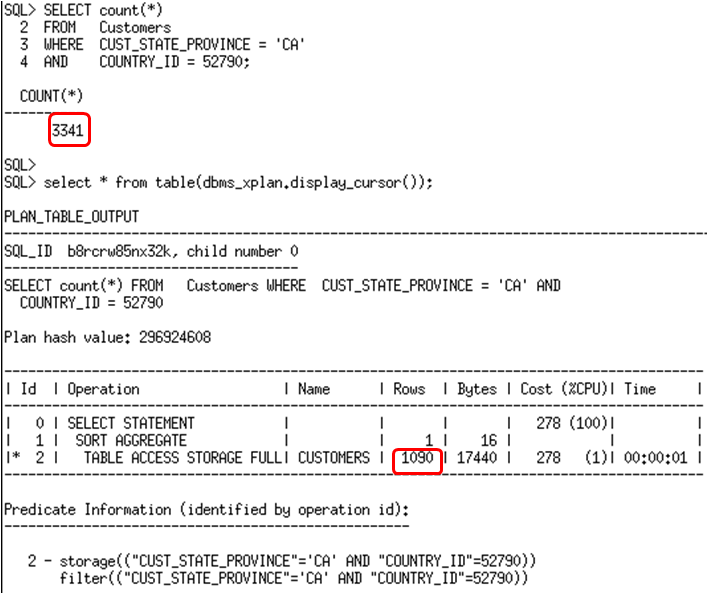
There is a slightly improvement in the estimate since we have histograms for the individual columns. However the optimizer is still not aware that there is a relationship or correlation between these two columns. We can tell the optimizer about this correlation by creating extended statistics on these two columns as a group. Once the extended statistics have been created the next time statistics are gathered on the customers table an extra set of statistics, for the combine group of country_id and cust_state_province, will be collected. The DBMS_STATS.CREATE_EXTENDED_STATS function can be used to create the extended statistics or a ‘column group’ for country_id and cust_state_province.

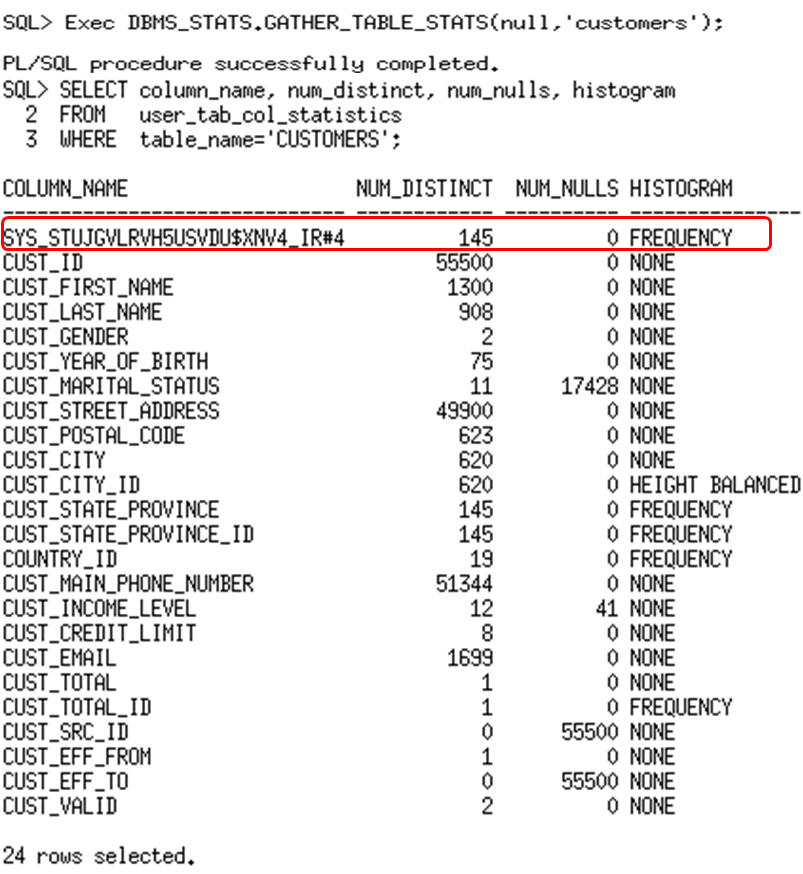
After creating the extended statistics and regather statistics, you will see a system generated column name in USER_TAB_COL_STATISTICS, which represents the new column group. A subset of statistics are maintained for column groups including;
- Number of distinct values
- Number of Nulls
- Histograms
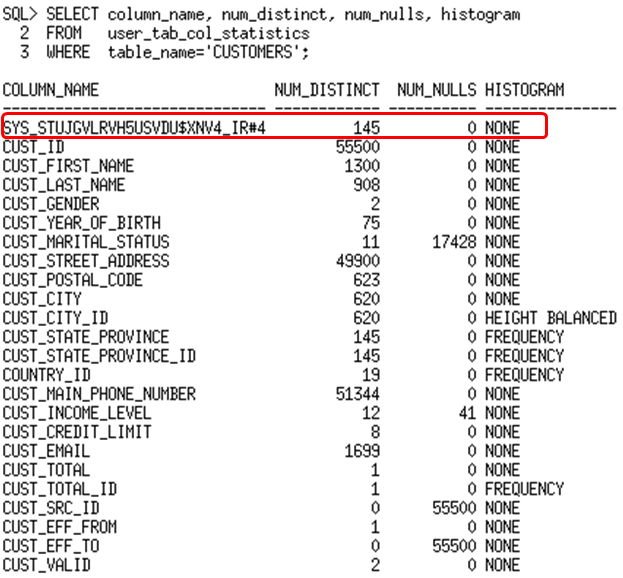
So now we have statistics on the column group lets confirm that is enough information for the optimizer to get the correct estimation.
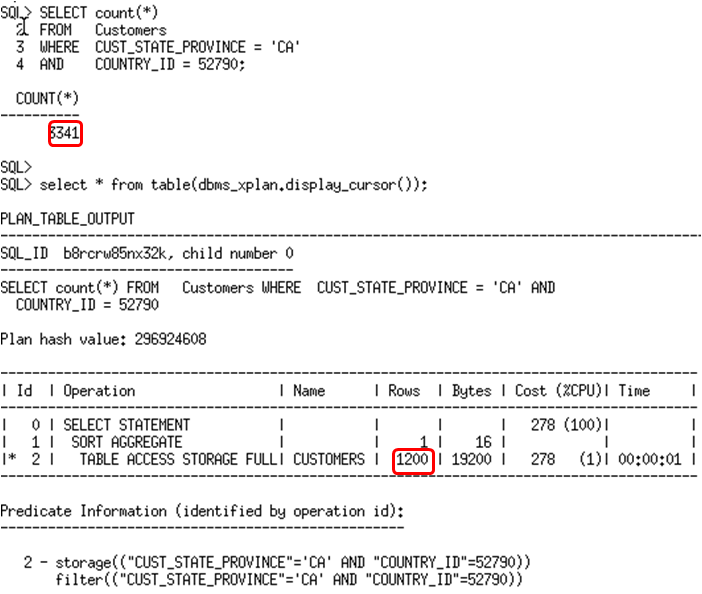
The cardinality estimate is still off. Why did the extended statistics not help in this case? The extended statistics were not actually used here. If you look back at the output from USER_TAB_COL_STATISTICS you can see there is a histogram created on the country_id and cust_state_province columns. However, there is no histogram created on the column group. Because a histogram provides the optimizer with more information than standard statistics the optimizer ignores the extended statistics and uses the individual column statistics instead.
Since we have executed the query again, the optimizer will have recorded that a histogram on the created extension is beneficial for the query. A histogram will be automatically created on the column group the next time statistics are gathered on the table
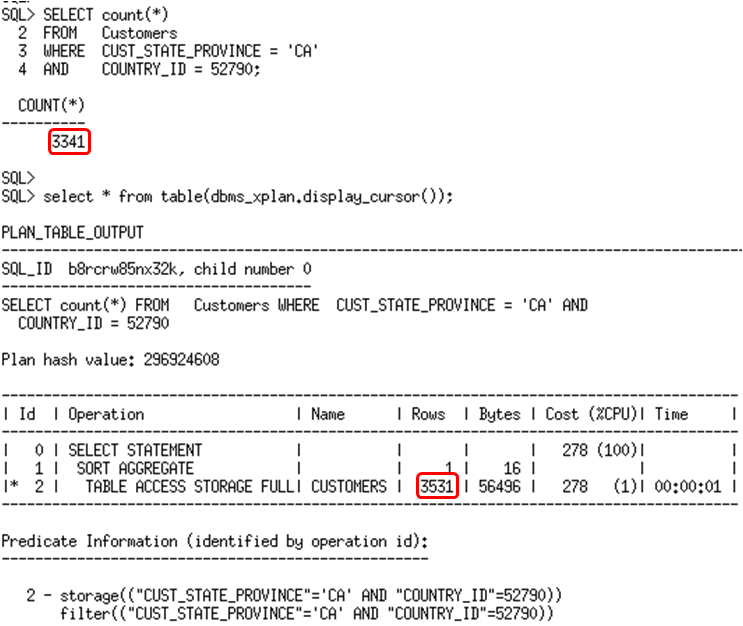
With the histogram in place on the column group, the optimizer will now use the extended statistics and the cardinality estimates is now accurate.
Extended statistics are used even if we have them for only a subset of predicates in the statement. Lets say there is a column group created on (c1, c2) and we have a SQL statement with a where clause that contains c1 = 1 and c2 =1 and c3 = 1. The optimizer will use the extended statistics on C1,C2 and multiply that by the selectivity of third predicate. It will use all the available statistics on column group, including histograms. The optimizer will also use the extended statistics (in a limited way) if a subset of the column group is present in the query.
