Introduction
This post covers how you can manage optimizer statistics efficiently when you use partition exchange load (PEL). This technique is used when large volumes of data must be loaded and maximum performance is paramount. It’s common to see it used in decision support systems and large operational data stores.
Make sure you’ve taken a look at Part 1, or you are at least familiar with the concept of incremental statistics so that you know what a synopsis is in the context of a partitioned table.
Partition Exchange Load
Most of you will be familiar with partition exchange load, but I’ll summarize it briefly to introduce you to the terminology I’ll be using here.
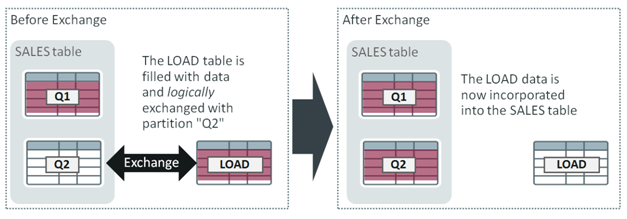
The graphic below represents the process. Firstly, the LOAD table is filled with new data and then exchanged with a partition in the “live” application table (SALES). SALES has partitions for quarter 1 and quarter 2 (Q1 and Q2) and LOAD is exchanged with the empty Q2 partition. The effect of the exchange is to incorporate all of the data in LOAD into SALES by swapping the “identity” of LOAD with Q2. The exchange is a logical operation: a change is made in the Oracle data dictionary and no data is moved. The data in LOAD is published to SALES “at the flick of a switch”.
Typically, the exchange step looks like this:
alter table SALES exchange partition Q2 with table LOAD including indexes without validation;
Operationally, this approach is more complex than inserting data directly into SALES but it offers some advantages. For example, new data can be inserted into LOAD before any indexes have been created on this table. If the volume of data is large, creating indexes at the end of the load is very efficient and avoids the need to bear the higher cost of index maintenance during the load. The performance benefit is especially impessive if data is loaded at very high rates in parallel.
The exact steps you need to execute for a partition exchange load will vary depending on the type of partitioning you use, whether there are local or global indexes on the table and what constraints are being used. For the purposes of this blog post I’m going to stick to how you manage statistics, but you can find details on how to deal with indexes and constraints in the Database VLDB and Partitioning Guide.
When new data is loaded into a table, optimizer statistics must be updated to take this new data into account. In the example above, the global-level statistics for SALES must be refreshed to reflect the data incorporated into the table when LOAD is exchanged with Q2. To make this step as efficient as possible SALES must use incremental statistics maintenance. I expect you’ll have guessed from the title of this post that I’m going to assume that from now on! I’m also going to assume that the statistics on SALES are up-to-date prior to the partition exchange load.
Oracle Database 11g
The moment after LOAD has been exchanged with Q2 there will be no synopsis on Q2; it won’t have been created yet. Incremental statistics requires synopses to update the global-level statistics for SALES efficiently so a synopsis for Q2 will be created automatically when statistics on SALES are gathered. For example:
EXEC dbms_stats.gather_table_stats(ownname=>null,tabname=>'SALES')
Statistics will be gathered on Q2 and the synopsis will be created so that the global-level statistics for SALES will be updated. Once the exchange has taken place, Q2 will need fresh statistics and a synopsis and it might also need extended statistics and histograms (if SALES has them). For example, if SALES has a column group, “(COL1, COL2)” then Q2 will need these statistics too. The database takes care of this automatically, so there’s no requirement to create histograms and extended column statistics on LOAD prior to the exchange because they are created for you when statistics are gathered on SALES.
There is nevertheless a scenario where you might want to gather statistics on LOAD prior to the exchange. For example, if it’s likely that Q2 will be queried before statistics have been gathered on SALES then you might want to be sure that statistics are available on Q2 as soon as the exchange completes. This is easy to do because any statistics gathered on LOAD will be associated with Q2 after the exchange. However, bear in mind that this will ultimately mean that statistics for the new data will be gathered twice: once before the exchange (on the LOAD table) and once again after the exchange (for the Q2 partition when SALES statistics are re-gathered). Oracle Database 12c gives you an alternative option, so I’ll cover that below.
If you want to know more about extended statistics and column usage then check out this post. It covers how you can seed column usage to identify where there’s a benefit in using extended statistics. Note that some column usage information is always captured to help identify columns that can benefit from histograms. This happens even if you don’t choose to seed column usage.
Oracle Database 12c
Oracle Database 12c includes an enhancement that allows you to create a synopsis on LOAD prior to the exchange. This means that a synopsis will be ready to be used as soon as the exchange has taken place without requiring statistics to be gathered on Q2 post-exchange. The result of this is that the global-level statistics for SALES can be refreshed faster in Oracle Database 12c than they can be in Oracle Database 11g. This is how to prepare the LOAD table before the exchange:
begin dbms_stats.set_table_prefs (null,'load','INCREMENTAL','TRUE'); dbms_stats.set_table_prefs (null,'load','INCREMENTAL_LEVEL','TABLE'); dbms_stats.gather_table_stats (null,'load'); end; /
Q2 will have fresh statistics and a synopsis as soon as the exchange completes. This isn’t quite the end of the story though. Statistics on Q2 will be gathered again after the exchange (when statistics are gathered on SALES) unless you have created appropriate histograms and extended statistics on LOAD before the exchange. The list_s.sql script in GitHub displays extended statistics and histograms for a particular table if you want to take a look at what you have. If you are using METHOD_OPT to specify exactly what histograms to create on SALES then you can use the same METHOD_OPT for gathering statisitcs on LOAD. For example:
Table preference…
dbms_stats.set_table_prefs(
ownname=>null,
tabname=>'SALES',
method_opt=>'for all columns size 1 for columns sales_area size 254');
Then…
dbms_stats.set_table_prefs (null,'load','INCREMENTAL','TRUE');
dbms_stats.set_table_prefs (null,'load','INCREMENTAL_LEVEL','TABLE');
select dbms_stats.create_extended_stats(null,'load','(col1,col2)') from dual;
dbms_stats.gather_table_stats(
ownname=>null,
tabname=>'LOAD',
method_opt=>'for all columns size 1 for columns sales_area size 254');
Alternatively, if you are using the default ‘FOR ALL COLUMNS SIZE AUTO’ to gather statistics on SALES, then it’s usually best to preserve automation and exchange without creating histograms on LOAD. This allows stats gathering on SALES to figure out what histograms are needed for Q2 post-exchange. Statistics on Q2 will be gathered post-exchange if SALES has column usage information indicating that there are columns in Q2 that don’t have a histogram but might benefit from having one. Also, as mentioned above, extended statistics will be maintained automatically too.
Summary of Steps
- Create the LOAD table and insert new data (or CREATE TABLE load AS SELECT…)
- Create a new (empty) partition for SALES (Q2)
- The new partition must have a synopsis before the exchange, so gather statistics for the new SALES table partition (use DBMS_STAS.GATHER_TABLE_STATS(username, table-name,partition-name, granularity=>’PARTITION’))
- Populate LOAD with data
- Optionally (Oracle Database 12c) – follow these steps if you want Q2 to have valid statistics immediately after the exchange:
o Set INCREMENTAL to ‘TRUE’ and INCREMENTAL_LEVEL to ‘TABLE’ for LOAD table
o Create extended statistics on LOAD to match SALES
o Gather statistics on LOAD using METHOD_OPT parameter to match histograms with SALES - Optionally (Oracle Database 11g) – follow these steps if you want Q2 to have valid statistics immediately after the exchange:
o Create extended statistics on LOAD to match SALES
o Gather statistics on LOAD using METHOD_OPT parameter to match histograms with SALES - Exchange LOAD with Q2 (this will exchange synopses in Oracle Database 12c, basic column statistics and histograms)
- Gather statistics for SALES to calculate global-level statistics. Oracle Database 12c will complete this step more quickly if you implemented “4”, above.
If, in the past, you have used partition exchange load and gathered statistics in an ad-hoc manner then you should probably check that the histograms you have match your expectations when comparing table-level histograms with histograms on partitions and sub-partitions. I’ve included a script in GitHub to help you do that.
Composite Partitioned Tables
If you are using a composite partitioned table, partition exchange load works in the same way as described above. If you would like to experiment with a complete example, I’ve created a script called example.sql here.
