Time series forecasting is a technique for predicting future values of key metrics based on past events. It involves using time ordered events from past as well as other variables to predict future values. Multivariate time series forecasting can predict multiple time ordered variables, where each variable is dependent on its past value as well as the past values of other dependent variables.
For instance, demand for electrical energy depends on the demand for other sources of energy such as wind and solar. The future monthly consumption of electricity, wind, and solar energy of a region is contingent on the prior year’s consumption in each of these categories, and there is an interdependency amongst them. Demand for each of these energy sources also depends on the severity of winter which is independent of demand for various categories of energy sources.
Similarly, the seasonal demand for corn is dependent on its past demand and the seasonal demand for other grains. Thus, the demand for various grains is interdependent. It also depends on independent variables such as the amount of rainfall. These kind of forecasting problems can be addressed using multivariate time series forecasting.
While analyzing time series, it becomes important to exploit temporal dependency and internal structure comprising of elements such as seasonality, trend, and residual. There are number of time series forecasting algorithms each best suited to a varying degree of strength of basic time-series characteristics. The choice of the optimal algorithm requires a statistician trained in time-series analysis for effective forecasting. Given the complexity involved, an automated approach for time series forecasting is highly desirable.
Machine learning in MySQL HeartWave (aka HeatWave AutoML) offers a fully automated forecasting pipeline that can automatically preprocess, select the best algorithm, and tune its hyperparameters for a given time-series dataset resulting is unmatched model training performance and high forecasting accuracy. There is no additional cost for using machine learning in MySQL HeatWave.
Other vendors such as Redshift ML and Snowflake do not provide support for time series forecasting. Google Big Query does not provide support for an automated machine learning pipeline for time series forecasting.
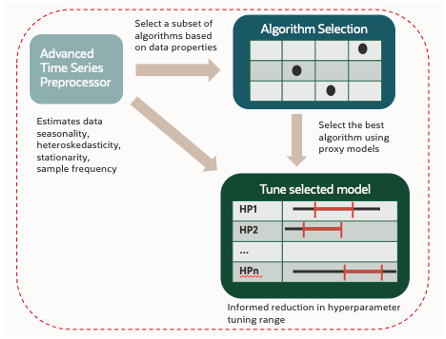
The HeatWave AutoML automated forecasting pipeline uses a patented technique that consists of stages such as advanced time-series preprocessing, algorithm selection and hyper parameter tuning. The advanced time-series stage prunes the search space and estimates basic time-series characteristics (seasonality, trend etc.) and these estimates are used later by the algorithm selection and hyperparameter tuning stages. The algorithm selection stage estimates the best algorithm for a given time-series dataset from the set of supported algorithms. The hyperparameter tuning stage tunes the hyperparameters for the algorithm in a range suggested by the preprocessor. This results in significant speedup by reducing the number of trials and improves generalization of tuned models.
HeatWave AutoML Examples
HeatWave AutoML routines referred in the code segment are described below. Please refer to MySQL HeatWave AutoML documentation for the details.
CALL sys.ML_TRAIN (‘table_name‘, ‘target_column_name‘, [options], model_handle);
options: {
JSON_OBJECT(‘key’,’value'[,’key’,’value’] …)
‘key’,’value’:
|’task’, {‘classification’|’regression’|’forecasting’} |NULL
|’datetime_index’, ‘column‘
|’endogenous_variables’, JSON_ARRAY(‘column‘[,’column‘] …)
|’exogenous_variables’, JSON_ARRAY(‘column‘[,’column‘] …)
|’model_list’, JSON_ARRAY(‘model‘[,’model‘] …)
|’exclude_model_list’, JSON_ARRAY(‘model‘[,’model‘] …)
|’optimization_metric’, ‘metric‘
|’include_column_list’, JSON_ARRAY(‘column‘[,’column‘] …)
|’exclude_column_list’, JSON_ARRAY(‘column‘[,’column‘] …)
}
Running the ML_TRAIN routine on a labeled training dataset produces a trained machine learning model. The values specified in options parameter provides the type of model to use and the details that the selected model type requires.
CALL sys.ML_MODEL_LOAD(model_handle, user);
The ML_MODEL_LOAD routine loads a model from the model catalog. A model remains loaded until the model is unloaded using the ML_MODEL_UNLOAD routine or until HeatWave ML is restarted by a HeatWave Cluster restart.
CALL sys.ML_PREDICT_TABLE (table_name, model_handle, output_table_name, options);
ML_PREDICT_TABLE generates predictions for an entire table of unlabeled data and saves the results to an output table.
CALL sys.ML_SCORE (table_name, target_column_name, model_handle, metric, score);
ML_SCORE scores a model by generating predictions using the feature columns in a labeled dataset as input and comparing the predictions to ground truth values in the target column of the labeled dataset.
Dataset
The examples of HeatWave AutoML Time Series Forecasting provided in this document are based on a sample data set to predict electricity consumption. Prediction task is to determine electricity consumption based on the time series data as well as other variables.
Code Segment
In the code segment provided below, training data is provided in the table ‘mlcorpus.daily_train’, prediction variable is ‘consumption’, machine learning task is ‘forecasting’, dependent variables (aka endogenic variables) are ‘consumption’ and‘wind’ will be predicted together, the independent variable (aka exogeneous variable) ‘solar’ is provided as exogenous variable.
mysql> CALL sys.ML_TRAIN (‘mlcorpus.daily_train’,’consumption’, JSON_OBJECT(‘task’, ‘forecasting’, ‘datetime_index’, ‘ddate’, ‘endogenous_variables’, JSON_ARRAY(‘consumption’, ‘wind’), ‘exogenous_variables’, JSON_ARRAY(‘solar’)), @model);
Query OK, 0 rows affected (27.84 sec)
mysql> CALL sys.ML_MODEL_LOAD(@model, NULL);
Query OK, 0 rows affected (0.92 sec)
The table ‘`’mlcorpus.daily_test`’ contains time series data with ground truth values of ‘consumption’ and ‘wind’. The predicted vales will be created in the table ‘mlcorpus.predictions2’
mysql> CALL sys.ML_PREDICT_TABLE(‘`’mlcorpus.daily_test`’, @model, ‘mlcorpus.predictions2’, NULL);
Query OK, 0 rows affected (2.79 sec)
The variables ‘consumption’ and ‘wind’ are predicted and stored in the table ‘mlcorpus.predictions2’. The column ‘ml_results’ provides predicted values of ‘consumption’ and ‘wind’
mysql> SELECT * FROM predictions2 LIMIT 5.
+————+——————–+——————–+
| ddate| consumption| wind| solar| wind_solar| ml_results|
+————+——————–+——————–+
| 2015-12-30 | 1496.93| 578.69| 33.54| 612.24|{‘predictions’: {‘consumption’: 1274.51,’wind’: 272.63}}|
| 2015-12-31 | 1533.09| 586.76| 33.65| 620.42|{‘predictions’: {‘consumption’: 1369.09,’wind’: 245.13}}|
| 2016-01-01 | 1521.93| 385.01| 44.77| 429.78| {‘predictions’: {‘consumption’: 1398.47,’wind’: 191.42}}|
| 2016-01-02 | 1518.60| 283.66| 47.09| 330.75| {‘predictions’: {‘consumption’: 1419.44,’wind’: 110.31}}|
+————+——————–+——————–+
4 rows in set (0.00 sec)
Model score is computed by comparing model outcome with the ground truth value of ‘consumption’ and ‘wind’ stored in the table ‘`’mlcorpus_daily_test`’
mysql> CALL sys.ML_SCORE(‘`mlcorpus`.`’mlcorpus.daily_test`’, ‘consumption’, @model, ‘neg_sym_mean_abs_percent_error’, @score);
Query OK, 0 rows affected (2.62 sec)
mysql> select @score;
+———————-+
| @score |
+———————-+
| -0.43969136476516724 |
+———————-+
1 row in set (0.00 sec)
In summary, time series forecasting is an effective technique to forecast time order events. Multivariate forecasting can take into account interdependency between multiple dependent events to predict their future values based on their historical values. HeatWave AutoML supports multivariate forecasting in a fully automated machine learning pipeline which provides runtime efficiency, high forecasting accuracy and makes time series forecasting effortless for the user. It is being used to effectively address the forecasting problems in various fields such as supply chain, energy management, gaming, digital marketing, finance and many more.
