MySQL Query Optimization is usually simple engineering. But seeking information about how to tune queries is treated on many web reference sites like some Harry Potter-ish spell casting. There are simple tips you need to be aware of to get the best of your queries.
One – The MySQL Query Optimizer wants to optimize your query every time it is presented
Each time your query is seen by the server, the query optimizer treats it as if it is the first time it has ever seen this wonderful new query! And wants to optimize it even if ten dozen copies of the exact same query are running at the same time! Other databases like Oracle allow the query plan to be locked down but MySQL does the full service treatment each and every time.
There is really no way around this but you can use optimizer hints to force some reduction of this. For instance if you know from experience that joining table b to table a works better than the other way around, you can place a directive with an optimizer hint to skip that part of the optimization process. Optimizer hints work on a per query or per statement basis so you will not impact another query’s performance.
Two – Order Counts
The order of operations is something every beginning coder learns as it is important to understand how the computer evaluates operations. MySQL also has many order dependent issues to be aware of when improving queries.
Let us pretend you have a functional index on the cost of an item and the cost of shipping. Your customers are very sensitive to the costs of both the products you sell and the shipping on those products. In hopes of increasing performance, you have created a functional index on the total of the product cost and the shipping cost.
Checking on a sample query with EXPLAIN, the query plan shows that indeed the new index is used for searching for products of a cost of less than 5.
FROM PRODUCTS
WHERE cost + shipping < 5\G
*************************** 1. row ***************************
EXPLAIN: -> Filter: ((cost + shipping) < 5) (cost=1.16 rows=2)
-> Index range scan on PRODUCTS using cost_and_shipping (cost=1.16 rows=2)
1 row in set (0.0008 sec)
So the index appears to be working properly but when your coworkers try to use this new wonderful index, they report less than stellar performance. FInally they share their query and EXPLAIN reports that the new wonderful index is not being used! Their query has to perform a much slower table scan! What happened??
FROM PRODUCTS
WHERE shipping + cost < 5\G
*************************** 1. row ***************************
EXPLAIN: -> Filter: ((products.shipping + products.cost) < 5) (cost=0.65 rows=4)
-> Table scan on PRODUCTS (cost=0.65 rows=4)
1 row in set (0.0016 sec)
Did you catch the issue?
If not, this is a wee bit nuanced. The index was created as (cost + shipping), your query uses (cost + shipping), while their query uses (shipping + cost). In this case the optimizer does not recognize that (cost + shipping) and (shipping + cost) are mathematically the same amount. It would be very simple to flip the order of the two columns and unwittingly step into a performance quagmire. To get the performance desired from a functional index the proper order of the components must be used.
Three – New EXPLAIN formats
New variants on the EXPLAIN command provide amazing new details on queries. EXPLAIN is used to see the query plan, the actual query the system will run to get your data, and details on how the query will be run. The traditional output provides some very good details.
FROM PRODUCTS
WHERE cost + shipping < 5\G
*************************** 1. row ***************************
id: 1
select_type: SIMPLE
table: PRODUCTS
partitions: NULL
type: range
possible_keys: cost_and_shipping
key: cost_and_shipping
key_len: 9
ref: NULL
rows: 2
filtered: 100
Extra: Using where
1 row in set, 1 warning (0.0008 sec)
Note (code 1003): /* select#1 */ select `demo`.`products`.`id` AS `id`,`demo`.`products`.`name` AS `name`,`demo`.`products`.`cost` AS `cost`,`demo`.`products`.`shipping` AS `shipping`,(`demo`.`products`.`cost` + `demo`.`products`.`shipping`) AS `(cost + shipping)` from `demo`.`products` where ((`cost` + `shipping`) < 5)
Again the optimizer recognizes that the cost_and_shipping index can be utilized. The optimizer will return two rows of data after scanning that index. And there are other details that may not be of interest at this time.
TREE format provides a different look at the information.
FROM PRODUCTS
WHERE cost + shipping < 5\G
*************************** 1. row ***************************
EXPLAIN: -> Filter: ((cost + shipping) < 5) (cost=1.16 rows=2)
-> Index range scan on PRODUCTS using cost_and_shipping (cost=1.16 rows=2)
1 row in set (0.0008 sec)
What is added in TREE format is that we get an easier to read presentation and we can see the cost of the query. It also explicitly informs us of the filter from the WHERE clause of the query.
But what if you really crave details and want to get a more granular look at how the optimizer looks at your query? Well, for you there is JSON format!
WHERE cost + shipping < 5\G
*************************** 1. row ***************************
EXPLAIN: {
“query_block”: {
“select_id”: 1,
“cost_info”: {
“query_cost”: “1.16”
},
“table”: {
“table_name”: “PRODUCTS”,
“access_type”: “range”,
“possible_keys”: [
“cost_and_shipping”
],
“key”: “cost_and_shipping”,
“used_key_parts”: [
“(`cost` + `shipping`)”
],
“key_length”: “9”,
“rows_examined_per_scan”: 2,
“rows_produced_per_join”: 2,
“filtered”: “100.00”,
“cost_info”: {
“read_cost”: “0.96”,
“eval_cost”: “0.20”,
“prefix_cost”: “1.16”,
“data_read_per_join”: “208”
},
“used_columns”: [
“id”,
“cost”,
“shipping”,
“name”,
“(`cost` + `shipping`)”
],
“attached_condition”: “((`cost` + `shipping`) < 5)”
}
}
}
1 row in set, 1 warning (0.0023 sec)
Note (code 1003): /* select#1 */ select `demo`.`products`.`id` AS `id`,`demo`.`products`.`name` AS `name`,`demo`.`products`.`cost` AS `cost`,`demo`.`products`.`shipping` AS `shipping`,(`demo`.`products`.`cost` + `demo`.`products`.`shipping`) AS `(cost + shipping)` from `demo`.`products` where ((`cost` + `shipping`) < 5)
Now we have information on the costs of reading, evaluation, and much more.
Bonus – Use MySQL HeatWave on Oracle Cloud to Speed Your Queries
HeatWave is a massively parallel, high performance, in-memory query accelerator for MySQL Database Service that accelerates MySQL performance by orders of magnitude for analytics and mixed workloads. HeatWave is 6.8X faster than Amazon Redshift at half the cost, 6.8X faster than Snowflake at one-fifth the cost, and 1400X faster than Amazon Aurora at half the cost.
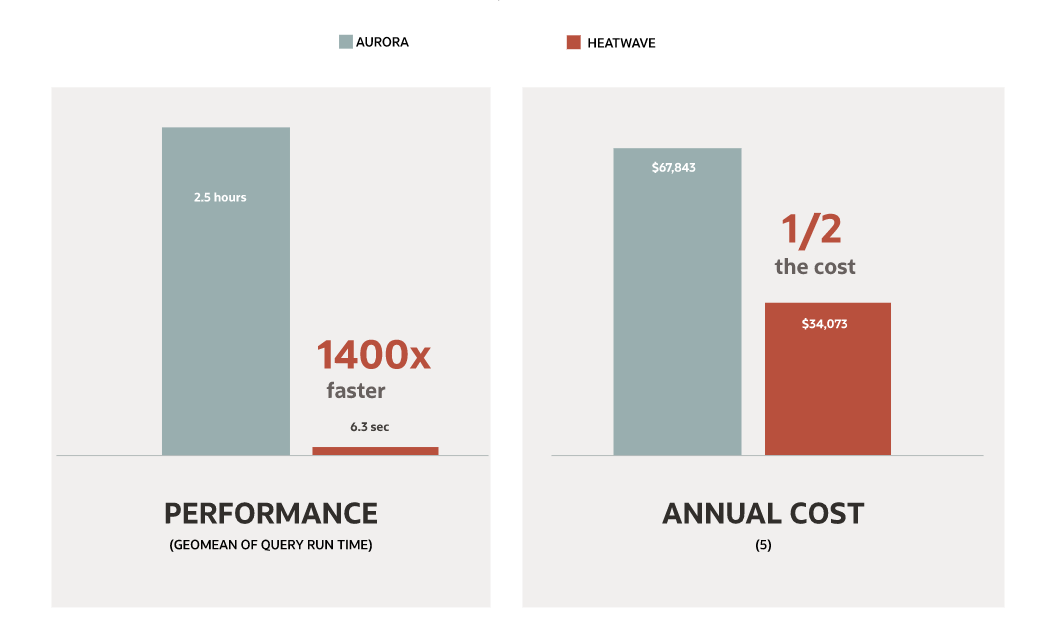
By enabling MySQL HeatWave in your MySQL Database Service environment you will get a massive performance improvement without changing a single query. Try it for FREE now!
Summary
If you really want to improve the speed of your queries, it pays to read through the MySQL manual’s section 8 which details the many optimizations available. It is also a great guide on the ‘whys’ behind the actions.
Do not miss the upcoming webinar about “Maximizing Query Performance for MySQL On-Premises and In the Cloud” on 26 January at 10 am CET. Register here now!

