Introduction
This is the fifth in a series of blogs that detail how to setup and use a LAMP Stack that makes use of MySQL HeatWave in the Oracle Cloud.
- Part 1 will set the scene by detailing what a LAMP stack is and what deployment options are available in the Oracle Cloud. It will also set out the architectural vision for the LAMP stack this series of blogs will build.
- Part 2 will build the infrastructure (network, application server, database server) in the Oracle Cloud.
- Part 3 will install and configure the remaining LAMP stack software.
- Part 4 will install additional software to assist in developing and deploying web applications. It will then securely deploy a demonstration PHP application.
- Part 5 (this part) will consider how to make the stack more scalable, available and secure.
Predicates for completing the tasks in this blog
None, but you will have a better context if you have read through the earlier parts.
Current Architecture
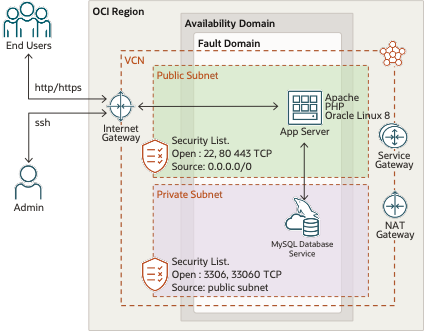
This architecture is fine for development, but is somewhat lacking for production:
- There is no way to scale out the application tier or database tier to meet increasing load. The application server and database can only be scaled up by adding resource.
- Both the application server and database are single points of failure (SPOF). Further, there is no way maintenance can be performed on either the application server or database without affecting availability.
- It’s probably not a good idea to use the app server in both its designated application server role and as a jumping off / staging / administrative server. The more roles a server has, the more likely it is to be compromised in terms of security, performance and availability.
Addressing Scalability Concerns
There are two ways to scale: up and out. Scaling up involves adding resource to an existing machine, whereas scaling out means adding machines that will work collectively to provide the service. Scaling up is sometimes referred to as vertical scaling, and correspondingly scaling out is referred to as horizontal scaling. Which method you choose (up or out) will depend upon the service you are implementing.
Databases are typically scaled-up. This is because there is usually great benefit in keeping as much of the data set as possible in memory as possible. Further, databases such as MySQL are designed to be able to handle many user connections. However, there are some use cases where it makes sense to scale a database out. An example use case would be that of an online hotel and flight booking application. Such an application will be heavily read biased because most customers will consider many options before making a booking. Therefore it makes sense to implement a database replication topology whereby there is a source database server that will handle all writes (i.e. the inserts and updates people make when performing a booking), and multiple replicas to handle the reads (queries).
Assuming application server code is stateless (which is considered a best practice) then the hosting application servers can easily be scaled out (i.e. multiple instances of servers all running the same code). Load balancers are put in front of these application servers and route incoming traffic to individual application servers according to their policy (e.g. round-robin, least connections, IP hash, etc.). Load balancers also monitor the health of the application servers such that traffic won’t be routed to a failed or withdrawn application server. The Oracle Cloud provides load balancers that are simple to instantiate and use, support the aforementioned policies as well as session persistence and TLS/SSL.
Addressing Availability Concerns
For this we need to consider how we can remove single points of failure (SPOFs), recovery from disaster and how uptime can be ensured through periods of essential maintenance. Again, we can discuss this in terms of tiers.
Given application servers are scaled-out, all that’s needed is to provide sufficient numbers of servers to handle the load and then deploy one or more extra servers for redundancy. This is referred to as an N+1 or N+2, etc., architecture where N is the minimum number of servers required to handle 100% of the load. This provides for an application server failure: in an N+1 architecture one server can fail and there is still sufficient resource available to handle 100% of the load. It also allows us to perform a rolling upgrade without affecting overall availability: one server at a time is taken out of the tier, upgraded and then returned to the tier.
N+1 may sound a little dated in the context of the more fashionable elastic-scale, but elastic scale effectively provides the same, it just does it on demand.
For the database tier, we typically use clustering to address availability concerns. Clustering provides automatic failover and should also provide zero data loss. An alternative to clustering is to use replication. The advantage of replication is that it needs fewer nodes than a cluster: a cluster typically requires a minimum of 3 nodes whereas replication needs only 2 making it a cheaper solution. However, in many cases the disadvantages outweigh this advantage:
- Traditional replication is asynchronous. A feature of asynchronous replication is that the replica database very often lags behind the source database by a number of transactions. If the source database fails then any lagging transactions will not be replicated and the data these transactions represent will be lost. This may be unacceptable especially in the case of financial transactions.
- Traditional replication cannot provide automatic failover because its architecture does not have a mechanism to agree which node or nodes have failed. Consequently, an administrator has to act as an arbiter to determine whether a failure has occurred and then manually failover the service as a whole. This involves:
- Ensuring the failed database is down and cannot inadvertently come up (which might cause split brain).
- Making the replica database the new source database.
- Making sure all application servers use the new source database.
- The above steps take time to implement and the service will be unavailable until these have been completed. This may take minutes or even hours. Compare this to a cluster solution that does it all automatically in a matter of seconds without incurring data loss.
Clustering and replication can be used together. A good use case would be a geographically distant DR site. In the primary site there is the cluster, and this replicates to either a single instance or another cluster in the remote site. If the primary site is lost (e.g. through natural disaster) the secondary site can be instantiated as the new primary.
The Oracle Cloud makes setting up a cluster as easy as creating a single instance: the only difference is you select High Availability instead of Standalone. The cluster uses a VIP – all you have to provide your application servers with the VIP address and you are good to go. Maintenance of the cluster and its nodes is done by the service; you do nothing. When upgrades are required these are done in a rolling fashion meaning the cluster stays up throughout.
An important part of a database availability strategy is to ensure that you have a good backup and restore strategy. Oracle Cloud makes backing up very simple: when you create a MySQL Database Service instance you will be prompted to provide a time for a daily full backup. After that all backups are done automatically, you don’t have to do anything.
Addressing Security Concerns
The existing architecture is almost certainly secure enough for demo applications, but as your application grows in importance it will increasingly become a target for malign forces. It is therefore prudent to be thinking of ways to reduce the surface area of any potential attack as well as using firewalls and intrusion detection systems. Oracle Cloud can again come to your aid. For example to reduce the attack surface area it is relatively simple to use subnets with appropriate security lists to hide resources such as databases. This can be taken further by using Network Security Groups that will only allow certain resources to communicate with peer resources which provides a far greater degree of granularity.
Security lists and network security groups address security at a networking level, they do not address security issues at an application level. For this Oracle Cloud provides the Web Application Firewall (WAF). WAF is a regional-based and edge enforcement service that is attached to an enforcement point, such as a load balancer or a web application domain name. WAF protects applications from malicious and unwanted internet traffic. WAF can protect any internet facing endpoint, providing consistent rule enforcement across your application(s). WAF provides you with the ability to create and manage rules for internet threats including Cross-Site Scripting (XSS), SQL Injection, and other OWASP-defined vulnerabilities. For more details refer to the Overview of Web Application Firewall.
Potential Architecture
Based on the scalability, availability and security concerns previously detailed we could envisage a future production architecture looking something similar to the diagram below.
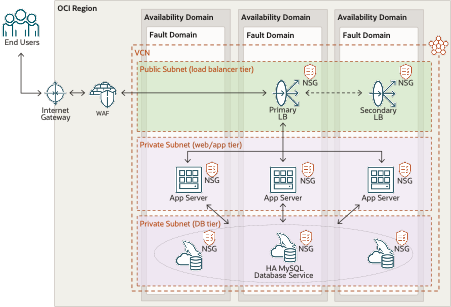
With respect to the diagram, the architecture provides for the scaling out of the application tier and scaling up of the database tier. Adding or indeed removing application servers can be done through the OCI console, as can the adding of resource (CPU, memory and storage) to the database tier.
The architecture provides availability in every tier using either N+1 or clustering techniques. A feature of the Oracle Cloud that further enhances availability is the ability to deploy resources across availability and fault domains. An availability domain is analogous to a data center, and a fault domain is analogous to a server rack. Larger Oracle Cloud regions such as London or Frankfurt will be comprised of three availability domains, with each domain being connected by very fast, wide and robust networking that ensures performance is the same as that which can be achieved in a single data center. By deploying across availability domains your architecture becomes resilient to data center failures.
Smaller regions are comprised of just one availability domain, and in such cases it is recommended to deploy resources across fault domains so that individual rack faults won’t affect overall availability.
By default the MySQL HA cluster will be deployed across all three availability domains in larger regions, and for smaller regions the cluster nodes will be deployed over three different fault domains. Please note the deployment of application servers with respect to availability and fault domains is your responsibility.
Security-wise the architecture makes use of sub-netting and network security groups to protect resources. Note that neither the application tier nor database cluster are directly accessible from the internet because they exist in private subnets. Further, the use of network security groups means that firewalling is done on a per server basis. This is more granular than using a security list which allows traffic from a whole block of IP addresses through a firewall. Network security groups have similarly been used to only allow application servers to communicate with the database cluster.
The architecture shown does not provide a way to deploy application code and the database schema. In the original development design the application server was accessible from the internet and doubled as a jump or staging server. This is not a good practice in production: firstly, it increases the attack surface area by exposing the tier to the internet, and secondly it promotes tinkering – making uncontrolled changes. All deployments and changes to a production environment should be done in a controlled manner; application code (including schemas) should be developed in a separate environment and be subject to source code control, for example, that provided by Github. However, even with proper source control the problem of deploying code to production servers still exists. If your organization has the resources to join its network with their Oracle Cloud tenancy (using either Site to Site VPN or FastConnect) then it may be as simple as opening up firewalls and extending network security groups / security lists. Site to Site VPN and FastConnect may be out or reach for individuals and smaller organizations. Therefore a bastion host may be required to serve as an intermediary/staging server. Oracle Cloud provides a free bastion service that can be used for this kind of purpose, however, its sessions are time-limited and so it can be difficult to use. Consequently many customers find it simpler to create their own bastion. All that’s needed is a compute instance (which could be from the always free tier) which should be located in its own public subnet. Use network security groups to allow the bastion to communicate with your app servers and the database tier. Setup the bastion’s public subnet security list to only allow certain servers (i.e. their IP addresses) from within your organisation’s network to communicate with the bastion. You can further improve security by using a product like Open VPN (for which there is an Oracle Cloud Marketplace image).
Summary
We have now reached the end of this series of blogs. Hopefully you have found it useful and have been encouraged to use what you have learned.
Below you also have a recording that might be of your interest.

