Introduction
MySQL is the world most popular open source database because of its reliability, high-performance, and ease of use. MySQL has been designed and optimized for transaction processing and enterprises around the world rely on it. With the introduction of HeatWave in MySQL Database Service, customers now have a single database which is efficient for both transaction processing and analytics. It eliminates the need for ETL to a specialized analytic database and provides support for real-time analytics. HeatWave is built on an innovative, in-memory query engine which is architected for scalability and performance and is optimized for the cloud. MySQL HeatWave service is faster than other database services – Snowflake, Redshift, Aurora, Synapse, Big Query – at a fraction of the cost.
MySQL Autopilot (Watch the webinar)
We recently introduced MySQL Autopilot for MySQL HeatWave. MySQL Autopilot automates many important and challenging aspects of achieving high query performance at scale – including provisioning, data loading, query execution and failure handling. It uses advanced techniques to sample data, collect statistics on data and queries, and build machine learning models to model memory usage, network load and execution time. These machine learning models are then used by MySQL Autopilot to execute its core capabilities. MySQL Autopilot makes the HeatWave query optimizer increasingly intelligent as more queries are executed, resulting in continually improving system performance over time.
Autopilot focuses on four aspects of the service lifecycle: system setup, data load, query execution and failure handling.
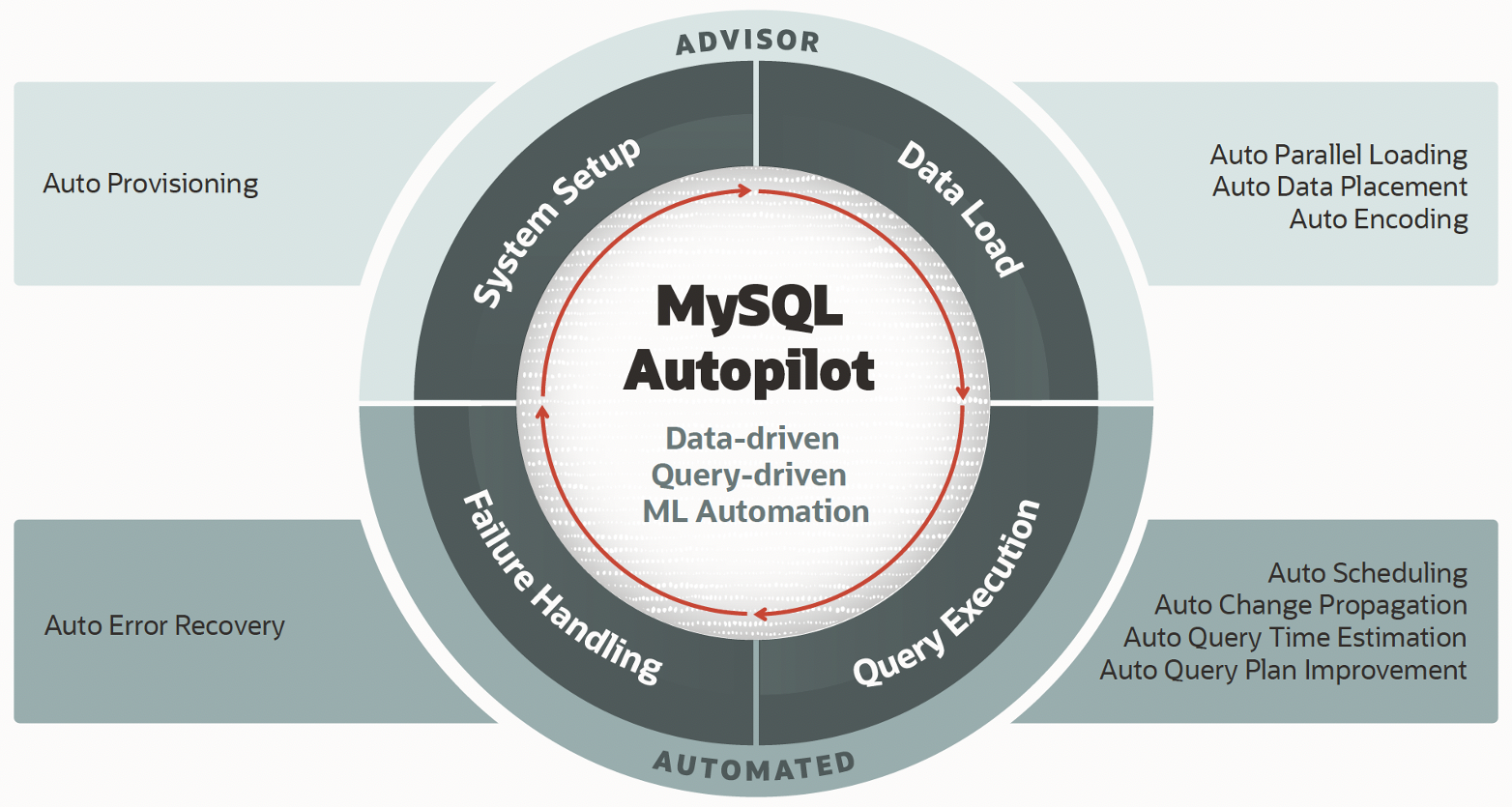
Figure 1. MySQL Autopilot automates different aspects of the service to improve performance, scalability and usability of the system
System Setup
1. Auto provisioning predicts the number of HeatWave nodes required for running a workload by adaptive sampling of table data on which analytics is required. This means that customers no longer need to manually estimate the optimal size of their cluster.
Data Load
2. Auto parallel loading optimizes the load time and memory usage by predicting the optimal degree of parallelism for each table being loaded into HeatWave.
3. Auto encoding determines the optimal representation of columns being loaded into HeatWave taking queries into consideration. This optimal representation provides the best query performance and minimizes the size of the cluster to minimize the cost.
4. Auto data placement predicts the column on which tables should be partitioned in-memory to achieve the best performance for queries. It also predicts the expected gain in query performance with the new column recommendation.
Query Execution
5. Auto query plan improvement learns various statistics from the execution of queries and improves the execution plan of future queries. This improves the performance of the system as more queries are run.
6. Auto query time estimation estimates the execution time of a query prior to executing the query, allowing quick tryout and test on different queries
7. Auto change propagation intelligently determines the optimal time when changes in MySQL Database should be propagated to the HeatWave storage layer. This ensures that changes are being propagated at the right optimal cadence.
8. Auto scheduling determines which queries in the queue are short running and prioritizes them over long running queries in an intelligent way to reduce overall wait time.
Failure Handling
9. Auto error recovery: Provisions new nodes and reloads necessary data from the HeatWave storage layer if one or more HeatWave nodes is unresponsive due to software or hardware failure
Auto Provisioning
Auto Provisioning provides recommendation on how many HeatWave nodes are needed to run a workload. When the service is started, database tables on which analytics queries are run need to be loaded to HeatWave cluster memory. The size of the cluster needed depends on tables and columns required to load, and the compression achieved in memory for this data. Figure 2 compares the traditional (i.e., manual) approach to estimating the cluster size with Auto Provisioning. In traditional provisioning, users need to guess a cluster size. Underestimation results in data load or query execution failure due to space limitations. Overestimation results in additional costs for unneeded resources. As a result, users iterate until they determine the right cluster size, and this size estimate becomes inaccurate when tables are updated.
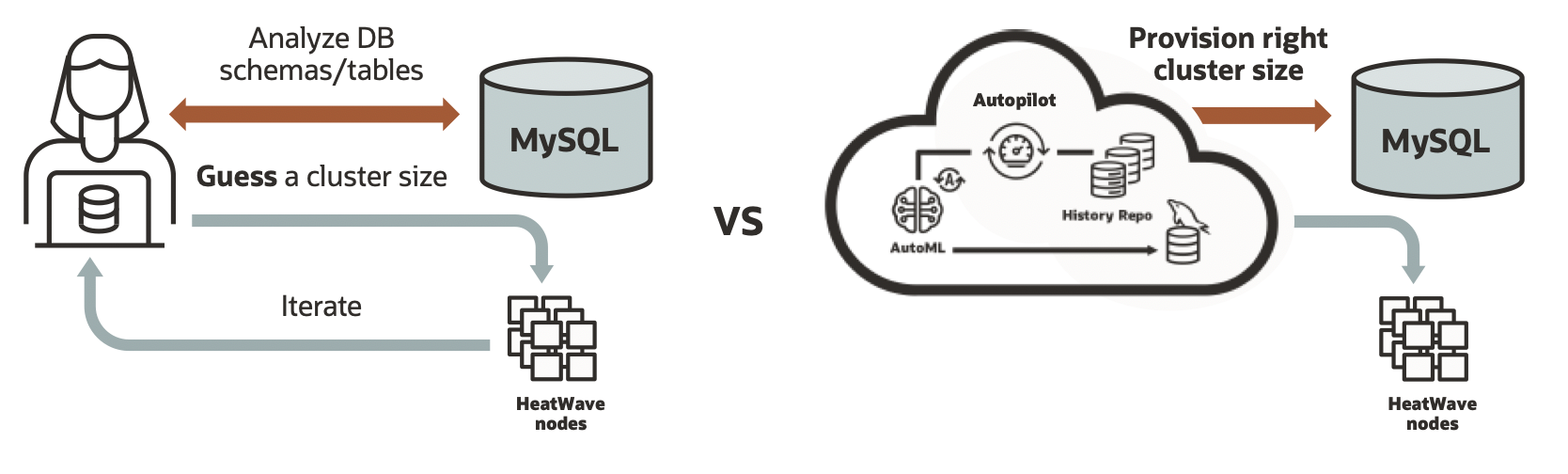
Figure 2. Comparison of a manual provisioning vs Auto provisioning
The right side of figure 2 shows how auto provisioning, a ML-based cluster size estimation advisor, solves this problem. By leveraging well trained and accurate ML models, the user consults auto provisioning advisor to obtain the right cluster size for their dataset. As a result, users do not need to guess the cluster size. Later, if the customer data grows or additional tables are added, the users can again take advantage of the auto provisioning advisor.
Below is an example of the accuracy of memory prediction observed on some data sets.
| Datasets |
TPCH 1024G |
TPCDS 1024G |
Cust A |
Cust B |
| Accuracy |
98.4% |
96.9% |
98.3% |
96.9% |
Auto Parallel Load
Loading data into HeatWave involves several manual steps. The time required to perform these steps depends on the number of schemas, tables, and columns, and statistics. Auto parallel load automates these steps by predicting the degree of parallelism per table via machine-learning models to achieve optimal load speed and memory usage.
Auto Encoding
HeatWave supports two string column encoding types: variable-length and dictionary. The type of encoding affects the query performance as well as the supported query operations. It also affects the amount of memory required for HeatWave nodes. By default, HeatWave applies variable-length encoding to string columns when data is loaded, which may not be the optimal encoding choice for query performance and cluster memory usage for certain workloads.
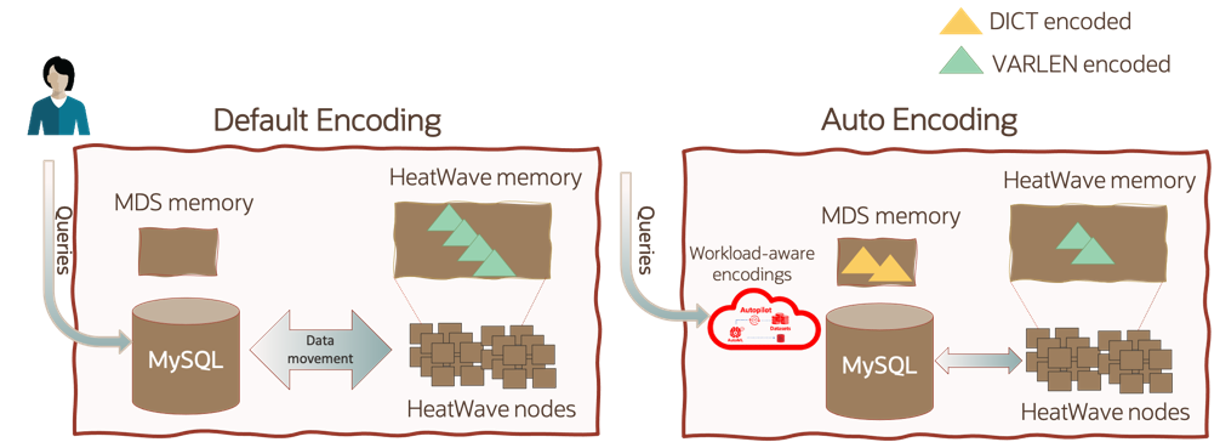
Figure 3. Comparison of a default encoding vs auto encoding
Auto encoding provides recommendations for string columns that reduce memory usage and help improve query performance. Figure 3 shows the difference between default encoding and auto encoding. In the default case, the variable-length encoding ensures best query offload capability. However, this can impact ideal query performance due to data movement between HeatWave nodes and MySQL nodes. Auto encoding uses machine learning to analyze column data, HeatWave query history, and available MySQL node memory to identify which string columns can be coded in dictionary encoding. When the suggestion is applied, the overall query performance is improved due to reduced data movement in system, and HeatWave memory usage is reduced due to efficient (i.e., smaller) dictionary codes and the corresponding dictionaries that maintain the mapping between the strings and the codes reside in the memory of the MDS node.
Auto Data Placement
Data placement keys are used to partition table data when loading tables into HeatWave. Partitioning table data by JOIN and GROUP BY key columns can improve query performance by avoiding costs associated with redistributing data among HeatWave nodes at query execution time.
Determining the best data placement key is a tedious task requiring understanding query access patterns and system behavior. Moreover, picking wrong partitioning keys can lead to sub-optimal performance due to increased data distribution costs during query execution time.
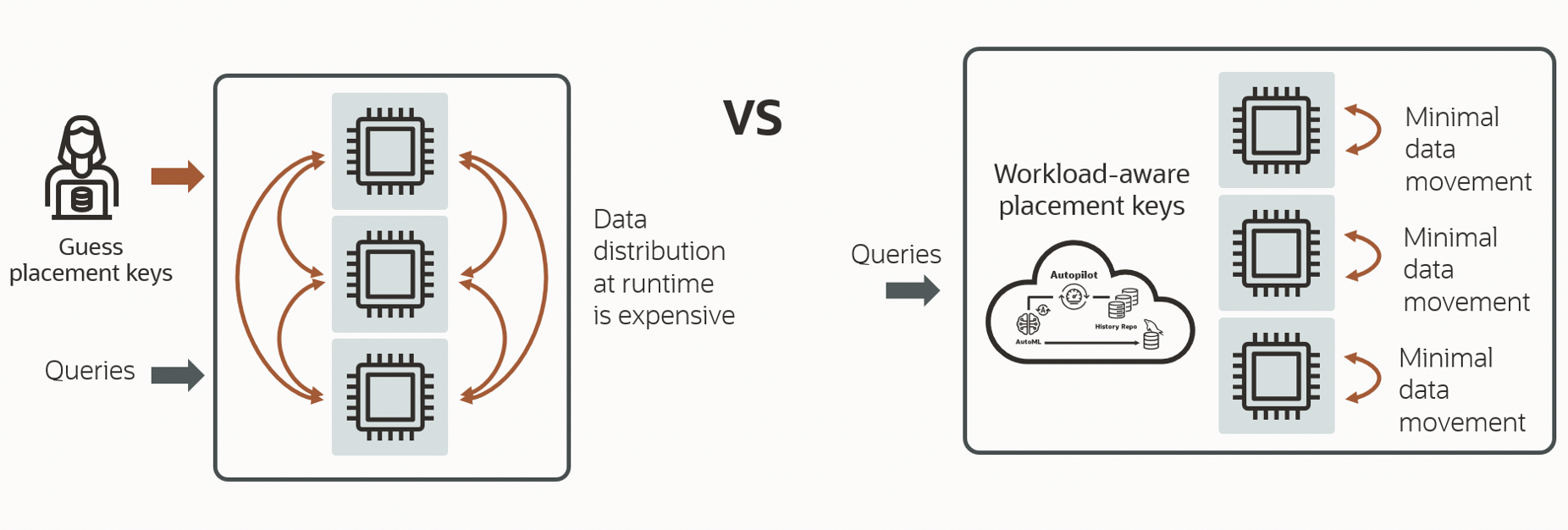
Figure 4. Comparison of manual data placement vs auto data placement
Figure 4 depicts a comparison between default query execution and execution with auto data placement. Based on machine learning models, auto data placement recommends appropriate data placement keys by analyzing table statistics and HeatWave query history and provides an estimation of query performance improvement. Once the suggestion is applied, query performance is improved by minimizing the data movement between nodes during execution.
The system predicts the optimal key on which the placement should be done and also predicts the expected improvement in the execution time. Below is the an example of improvement observed with auto data placement.
| Dataset |
Time with primary key placement |
Predicted improvement |
Actual improvement |
| TPCH 1024 |
332 sec |
26% |
37% |
| TPCH 4096 |
373 sec |
20% |
25% |
Auto Query Plan Improvement
Auto query plan improvement enhances query performance by improving query plan statistics based on previous query executions. By maintaining more accurate query statistics, HeatWave creates better query plan and makes better decisions on the underlying physical operators; consequently improves the overall query performance.
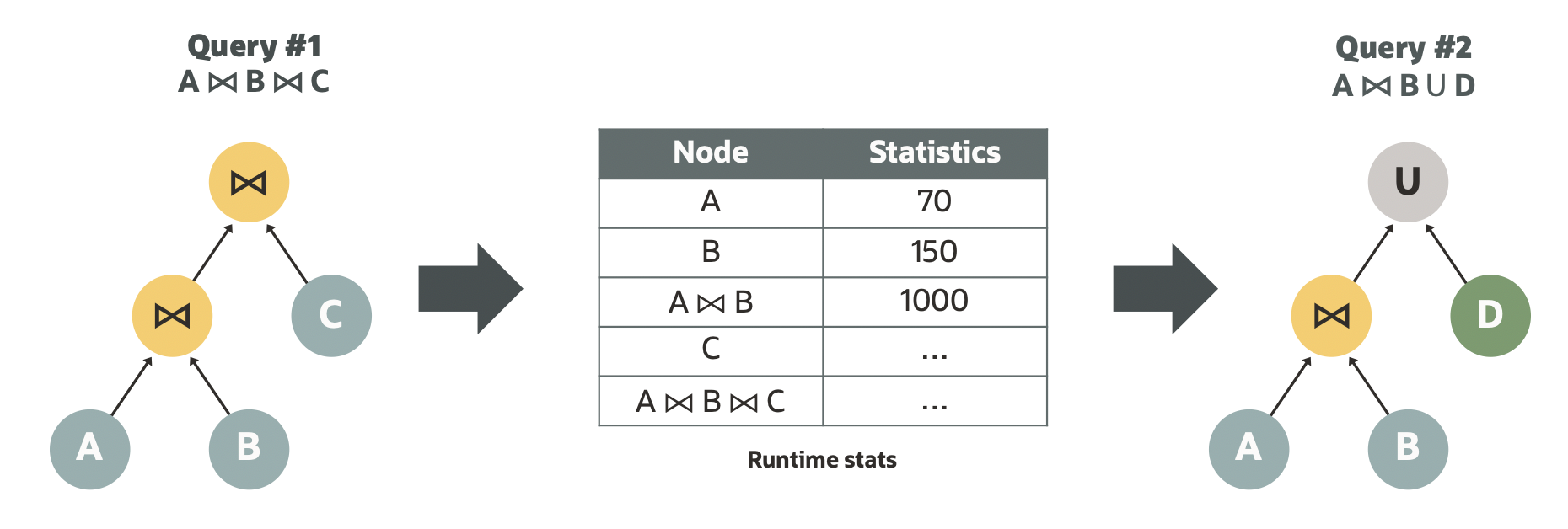 Figure 5. Query 2 benefits from statistics of a previous similar query (query 1) with auto query plan improvement
Figure 5. Query 2 benefits from statistics of a previous similar query (query 1) with auto query plan improvement
Figure 5 shows how auto query plan improvement works without user intervention. After a query (Q1) executes on HeatWave, auto query plan improvement collects and stores the cardinalities of all operations in the query execution plan (e.g., scan, join, group by). When a similar (or identical) query arrives (Q2), the system checks whether it can take advantage of the previously collected statistics information for Q2. If the system determines a similarity between the two query plans, a better query plan is generated based on statistics information from Q1. In doing so, it improves query performance and cluster memory usage significantly.
Auto Query Time Estimation
Users are often interested in accurate query time estimates before running the query. Such functionality allows users to estimate their application performance better and to understand the resource needed. Auto query time estimation not only provides user-visible estimations for query run times, but it also uses the same building blocks internally to improve query performance by optimizing query (sub-)plans.
Instead of using static, analytical models, auto query time estimation integrates a data-driven query time estimation module, which improves as queries run. To do so, HeatWave leverages load- and run-time statistics and dynamically tunes query cost models during execution. As a result, auto query time estimation improves with time as more queries are executed on the system.
Auto Change Propagation
Data updated in MySQL is propagated and persisted to HeatWave data layer as change logs. During data reload, HeatWave first restores data from the base data, then applies the data from the change logs. Over time, the persisted change log volume increases, which can result in an increased reload time as all the change logs need to be applied to the base data. So, the change logs are consolidated from time-to-time to alleviate increased reload latency as shown in Figure 6. However, determining when to consolidate is not an easy task, which depends on several factors such as transaction rate, system load, failure probability.
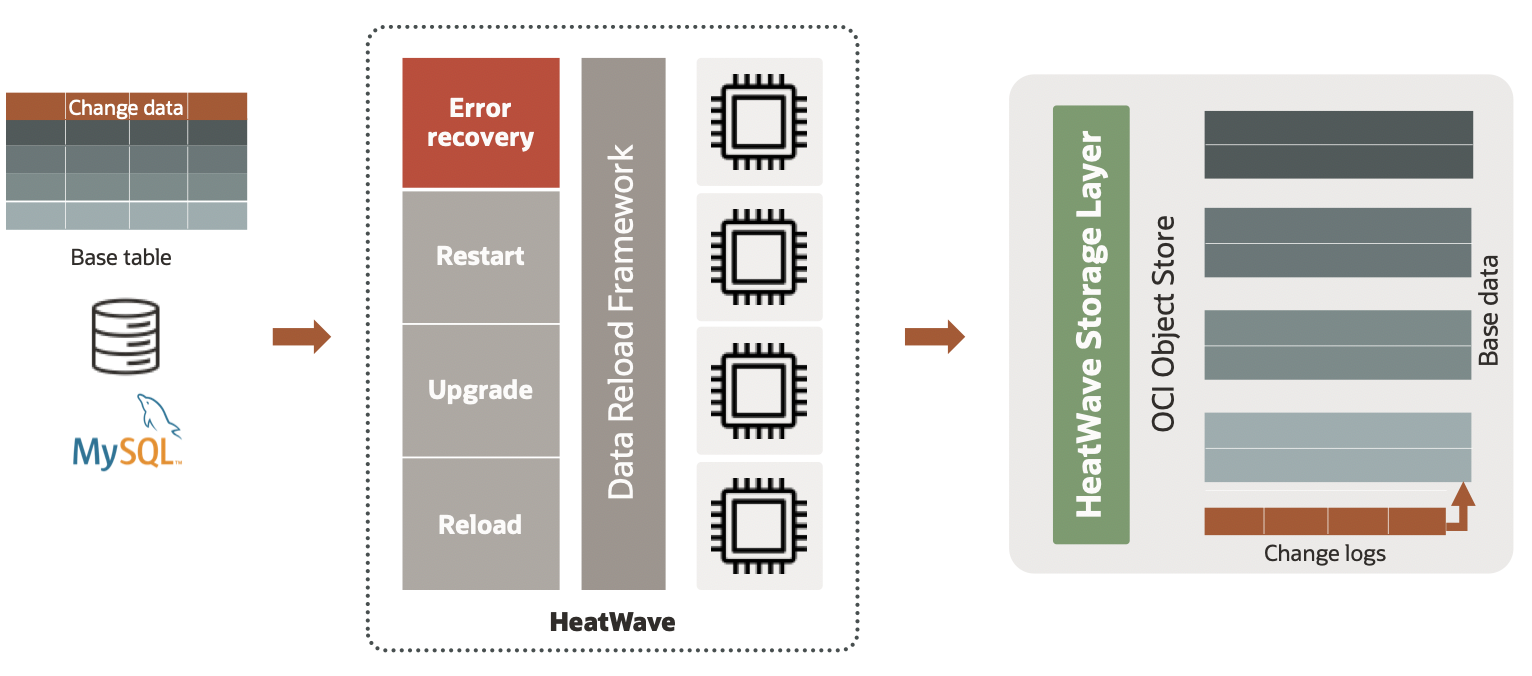
Figure 6. Auto change propagation
To minimize consolidation time during reloading from the storage layer, auto change propagation uses data driven mechanism to determine the best change propagation interval and choice. Auto change propagation analyzes rate of changes, incoming DMLs, object storage resources, and previously seen change activity. As a result, the changes are propagated at the best time interval, which results in optimized consolidation time for critical system operations.
Auto Scheduling
Traditional database systems process queries based on their arrival time, which can result in long-running queries starving short-running queries, as shown in Figure 7.
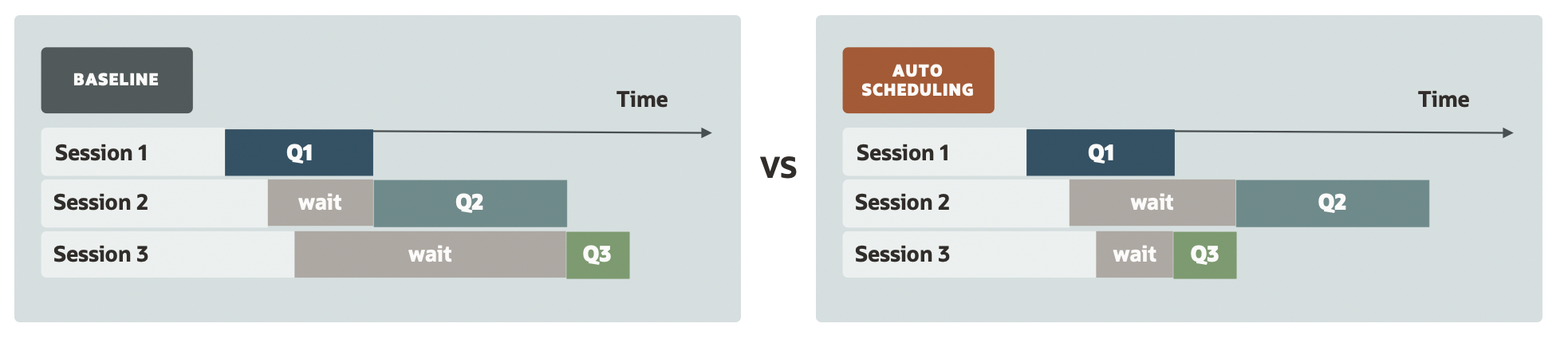
Figure 7. Traditional database system vs HeatWave auto scheduling
On the left, is a sub-optimal case where three queries (Q1, Q2, Q3) from three user sessions arrive one after the other and are scheduled in the FIFO order. After the execution completes, one can identify that waiting time for Q3 could be reduced significantly with minimal impact on Q2 latency.
On the right, it shows how auto scheduling improves user experience for short running queries in a multi-session application. Auto scheduling identifies and prioritizes short-running queries by automatically classifying queries into short or long queries using HeatWave data driven algorithms. Therefore, Q3 is prioritized before Q2 as Q3 is identified as a short-running query.
Auto Scheduling reduces elapsed time for short-running queries significantly when the multi-session applications consist of a mix of short and long running queries. It also ensures long-running queries are not penalized and are not postponed indefinitely.
Auto Error Recovery
HeatWave automatically provisions a new HeatWave node(s) when a hardware or software failure is detected on a node. When the cluster is restored, auto error recovery automatically reloads the data only to the re-provisioned node(s), allowing a very fast recovery.
Conclusion
MySQL HeatWave is the only MySQL based database which provides machine learning based automation. MySQL Autopilot automates the task of optimally provisioning a cluster, loading data and query processing. It makes HeatWave increasingly intelligent as more queries are executed, resulting in continually improving system performance over time. The introduction of Autopilot widens the performance and price performance advantage of MySQL HeatWave over other database services.
Additional References:
Watch the MySQL Autopilot webinar
Learn more about MySQL Database Service
