When thinking about high availability (HA) for their database, people routinely think about protection from instance failures, node failures, and even more disastrous events such as data center failures. However, one category of “failures” that is equally disastrous but commonly overlooked is “logical corruptions,” a.k.a. application or human errors.
Any simple but incorrect data manipulation can cause logical corruption. For example, an almost humorous but potentially disastrous situation caused by a human error may involve promoting all of a company’s employees in the HR system to Vice President by accidentally leaving out the where clause in an update statement. The database usually needs to be stopped to recover and prevent any further dependent corruptions to the data, which routinely results in noticeable downtime for the database and the application.

These types of human errors happen from time to time despite the best precautions. That is the way of life in today’s world with its fast-moving pace where application and data changes are often required with short notice. The question then becomes quite simple, how best restore from such a failure?
One way of answering this question depends on how the compromised database was protected in the first place (e.g., using backups only, replication, or a combination thereof). For the sake of this discussion, we will consider both the Oracle Database and, to provide some contrast, Google Spanner.
For the longest time, Google Spanner has claimed that they do not even need backups as they maintain a sufficient number of “replications” for their database so that a database as a whole and even sub-sets of data are unlikely to fail at once. However, it is still possible for Google Spanner administrators to create backups if they want that capability, but Google Spanner replication is the default approach. Replication alone cannot be seen as an ideal solution for this case and many other HA and DR situations, which we will examine in more detail later in this article.
From the Oracle Database perspective, digging into how to protect a database adequately from the holistic HA & DR perspective is beyond the focus of this blog post (for those interested, please check out the MAA Webcast Series for a great starting point). Instead, let’s focus on the challenges of resolving logical data corruptions caused by human and application errors.
Traditional Blunt Force Recovery Methods for Logical Corruptions Are Painful
If we consider the logical corruption event above, the updated data would be valid from a SQL transaction perspective. Based on that, it is quite likely that further damage could result as subsequent statements might be based on logically corrupted data. Regardless of the level and depth of the logical corruption, no errors will be seen from the database perspective as this is a normal successful operation. However, the same cannot be said from the application’s perspective or business, which will no doubt see this logical corruption as a severe issue.
Consequently, any restore and recovery operation will need to work on very granular pieces of data, likely across a set of different database objects. Unfortunately, many typical recovery solutions would not be ideal in this case. Let’s look at a couple of examples of recovery for other database technologies. Specifically, we will use Google Spanner’s approach to understand functional gaps better and to provide comparison and contrast to Oracle’s solution.
Example 1: Replication – The idea behind replication for protection is that data can always be restored from one of the remaining replicas. Oracle (Active) Data Guard provides replication for the Oracle Database, but it is just part of a more holistic solution for high availability and disaster recovery.
For those familiar with the concept of replication, it may seem obvious why this approach won’t facilitate an easy recovery in the case of a logical corruption such as the one discussed above. As a matter of fact, this approach may even complicate the problem. The reason is that once the “wrong update” (a.k.a. the logical corruption) has been submitted for commit, distributed databases using replication-based protection will only confirm the commit once the majority number of replicas have received the update. Therefore, by the time the commit has been confirmed, the logical corruption will have already expanded to impact all of the replicas that were expected to protect the data.
Example 2: Backup & Recovery – Now that we have established that replicas wouldn’t really work to restore data from this type of corruption, recovery from backup & restore usually would come to mind as an alternative approach to recover from such logical corruptions. While many might think this to be a valid approach, the practicality of it is cumbersome at best. If we again use Google Spanner as an example of database technology, we would find that only recently did Google even introduce backups for each copy of the data (including the copies in replicas). Therefore, to fully restore Google Spanner databases, one would have to perform as many local restore and recovery operations as the number of replicas that were impacted by the logical corruption in the first place, which may be quite a few.
In addition, the restoration and recovery required are very complicated. Why? A restore and recovery operation is generally designed to restore a full set of database entities – e.g. a complete Oracle Database. However, a logical corruption as described cannot simply be recovered that way. What is needed is a “point in time recovery” (PITR) to the state of the database prior to when the problematic update or insert was committed. This is a complex process that would require the restoration from backup to an auxiliary database and then exporting/importing the needed data to the production database.
Example: How to Recover from Logical Corruptions
An example always helps, so let’s explore how we might resolve this logical corruption in an Oracle Database. Specifically, let’s walk through a scenario including the following stages and steps:
- Acknowledge the situation – data is incorrectly updated (logical corruption strikes)
- Restoring data via Oracle Backup and Recovery (sub-optimal approach)
- Oracle Flashback technology to the rescue (ideal approach)
Staging the Situation – Data is Incorrectly Updated
Assume the following table:
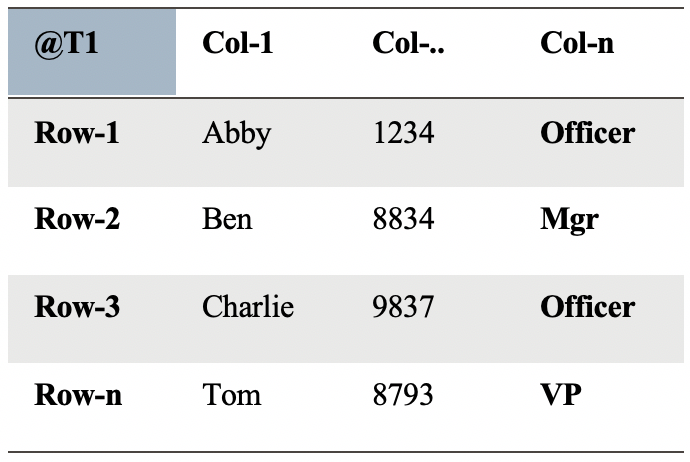
An update is executed against the table resulting in the following “Logical Corruption”:
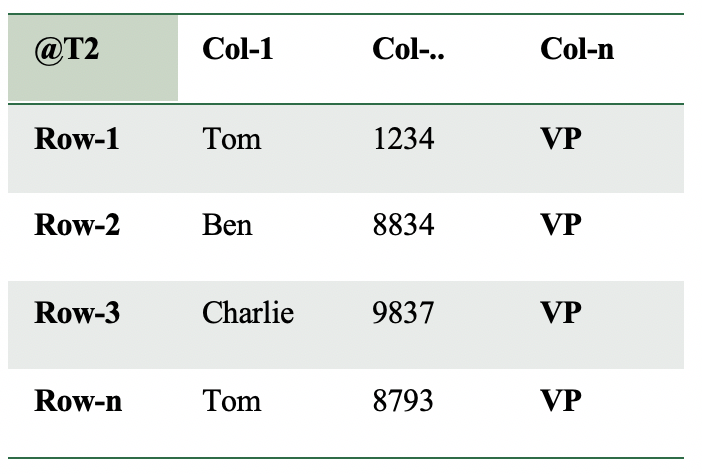
This is a big mistake that could have severe consequences. Imagine when this happens in a payroll or CRM system. Even worse, if col-n is used to grant access rights, this could lead to some serious security breaches.
Restoring Data via Oracle Backup and Recovery
Even using an Oracle Database, the RMAN approach is not ideal in this case, although often more robust than other databases. Since Oracle 12.1, RMAN has the RECOVER TABLE command that performs a point in time restore (PITR) operation for a single table. This automatically creates an auxiliary instance, performs a point-in-time restore, and then automatically performs the import of the corrupted table to the impacted database. No need to lose any data, and even better, the database remains online during this operation! The documentation provides examples of how to do this to illustrate all the steps to get the table back.
Oracle Flashback Technology to the Rescue
The above process could be somewhat complicated and require recovery time proportional to the size of the tablespace hosting the table, even when using RMAN. But Oracle Database has a unique feature that can quickly solve the wrong update without needing to restore the database.
In Oracle, we can perform a flashback table operation. The database must have flashback logging enabled. The following query helps to verify the current status of the database:
SELECT FLASHBACK_ON FROM V$DATABASE;
When the output from this query is no, it is simple to enable Flashback with the following command:
ALTER DATABASE FLASHBACK ON;
When running the query again, the database is ready to use Flashback. In the background, it will start to collect Flashback logs. Flashback uses these flashback logs to access previous versions of data blocks in combination with some data in the archived redo log files.
When flashing back a table, the flashback table command looks into the information in the flashback logs to see what the data looked like prior to the logical corruption incident. That way, data can be retrieved from the past using a simple, convenient, and reliable manner without needing to take the database down or start unnecessary auxiliary instances that may lead to resource issues with very large databases.
For example, if you want to rewind the table a minute in the past (assuming you were fast to react but a more extended timeframe would work as well) before when the corruption has hit the system, it is easy as invoking:
FLASHBACK TABLE <table_name> TO TIMESTAMP (SYSTIMESTAMP - INTERVAL '1' minute);
Without restoring the entire database, without auxiliary instances. Just retrieve the correct data and make it current again. Simple.
This is why Oracle Flashback is often better than a backup, particularly in cases of local corruption caused by human or application error. It is simple to implement, fully integrated into the Oracle Database, and most of all, it doesn’t require database and application downtime. Oracle Database is unique in its approach to disaster recovery to ensure your data is truly protected from all disaster events.
