Scheduler Soft Affinity
Oracle Linux kernel developer Subhra Mazumdar presents a new interface to the Linux scheduler he is proposing.
Servers are getting bigger and bigger with more CPU cores, memory and I/O. This trend has lead to workload consolidation (e.g multiple virtual machines (VMs) and containers running on the same physical host). Each VM or container can run a different instance of the same or different workload. Oracle Database has a similar virtualization feature called Oracle Multitenant where a root Database can be enabled to act as a Container Database (CDB) and house multiple lightweight Pluggable Databases (PDBs), all running in the same host. This allows for very dense DB consolidation. Large servers usually have multiple sockets or NUMA (Non Uniform Memory Access) nodes with each node having its own CPU cores and attached memory. Cache coherence and remote memory access is facilitated by inter-socket links (QPI in case of Intel) but usually much more costlier than local access and coherence. When running multiple instances of a workload in a single NUMA host, it is good practice to partition them e.g give a NUMA node partition to each DB instance for best performance. Currently the Linux kernel provides two interfaces to hard partition instances: sched_setaffinity() system call or cpuset.cpus cgroup interface. This doesn’t allow one instance to burst out of its partition and use potentially available CPUs of other partitions when they are idle. Another option is to allow all instances to spread across the system without any affinity, but this suffers from a cache coherence penalty across sockets when all instances are busy.
Autonuma Balancer
One potential way to achieve the desired behavior is to use the Linux autonuma balancer which migrates pages and threads to align them. For example, if each DB instance has memory pinned to one NUMA node, autonuma can migrate threads to their corresponding nodes when all instances are busy, thus automatically partitioning them. Motivational experiments, however, show not much benefit is achieved by enabling autonuma. In this case 2 DB instances were run on a 2 socket system, each with 22 cores. Each DB instance was running an OLTP load (TPC-C) and had its memory allocated from one NUMA node using numactl. But autonuma ON vs OFF didn’t make any difference. The following statistics show (for different number of TPC-C users) the migration of pages by autonuma, which didn’t have any performance benefit. This also shows that numactl only restricts the initial memory allocation to a NUMA node and autonuma balancer is free to migrate them later. Below numa_hint_faults is the total number of NUMA hinting faults, numa_hint_faults_local is the number of local faults so the rest are remote and numa_pages_migrated is the number of pages migrated by autonuma.
users (2x16) no affinity
numa_hint_faults 1672485
numa_hint_faults_local 1158283
numa_pages_migrated 373670
users (2x24) no affinity
numa_hint_faults 2267425
numa_hint_faults_local 1548501
numa_pages_migrated 586473
users (2x32) no affinity
numa_hint_faults 1916625
numa_hint_faults_local 1499772
numa_pages_migrated 229581Other disadvantages of autonuma balancer are a) it can be ineffective in case of memory spread among all NUMA nodes and b) can be slow to react due to periodic scanning.
Soft Affinity
Given the above drawbacks, a logical way to achieve the best of both worlds is via the Linux task scheduler. A new interface can be added to specify the scheduler prefer a given a set of CPUs while scheduling a task, but using other available CPUs if the preferred set is all busy. The interface can either be a new system call (e.g sched_setaffinity2() that takes an extra parameter to specify HARD or SOFT affinity) or by adding a new parameter to cpuset (e.g cpuset.soft_cpus). It is important to note that Soft Affinity is orthogonal to cpu.shares: the latter decides how many CPU cycles to consume while former decides where to preferably consume those cycles. Under the hood the scheduler will add an extra set, cpu_preferred, in addition to the existing cpu_allowed set per task. cpu_preferred will be set as requested by the user using any of the above interfaces and will be a subset of cpu_allowed. In the first level of search, the scheduler chooses the last level cache (LLC) domain, which is typically a NUMA node. Here the scheduler will always use cpu_preferred to prune out remaining CPUs. Once LLC domain is selected, it will first search the cpu_preferred set and then (cpu_allowed – cpu_preferred) set to find an idle CPU and enqueue the thread. This only changes the wake up path of the scheduler, the idle balancing path is intentionally kept unchanged: together they achieve the “softness” of scheduling.
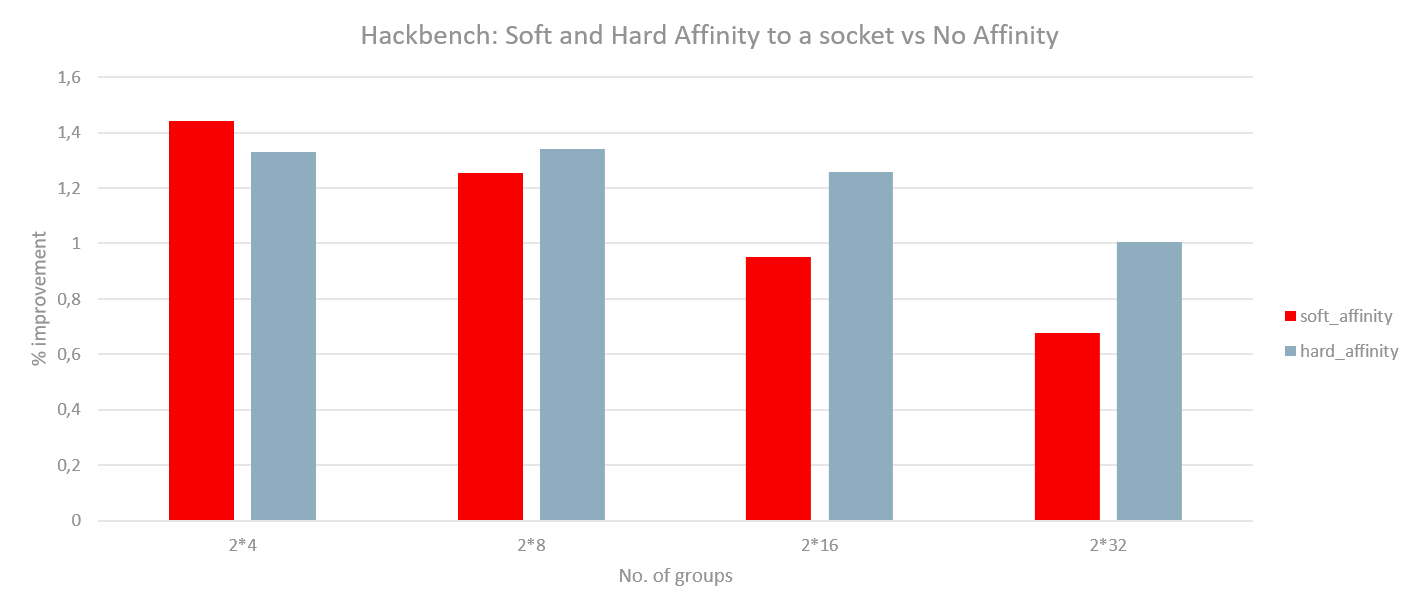
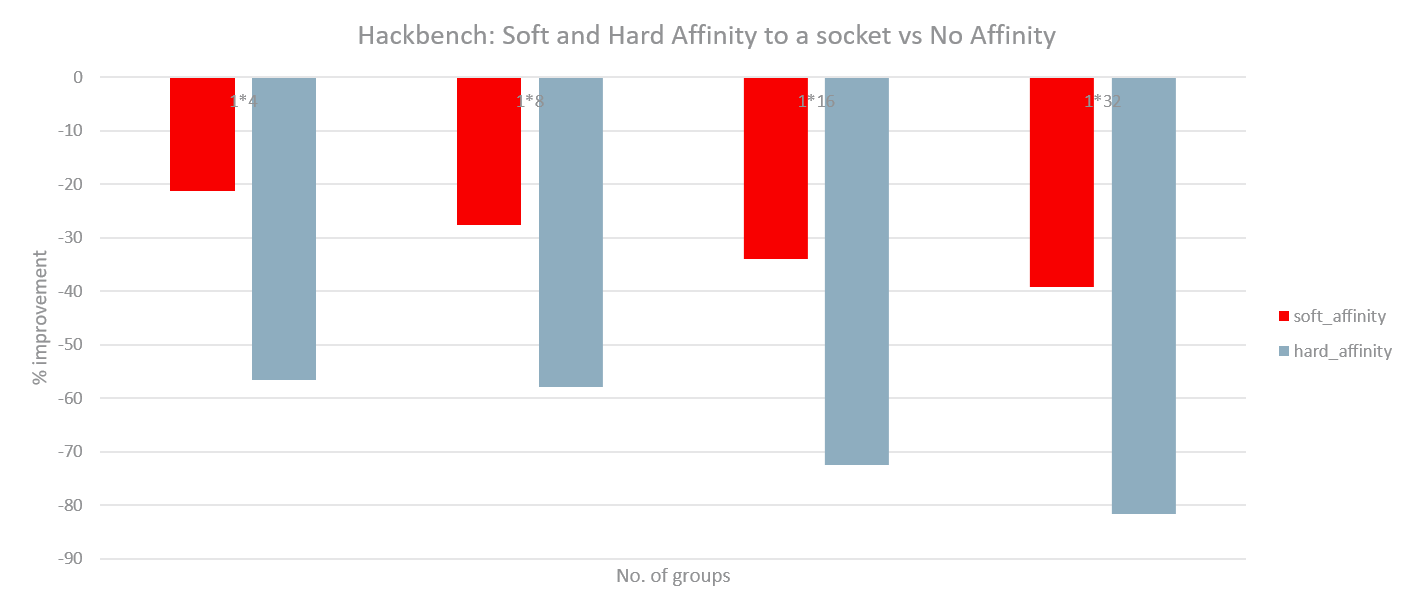
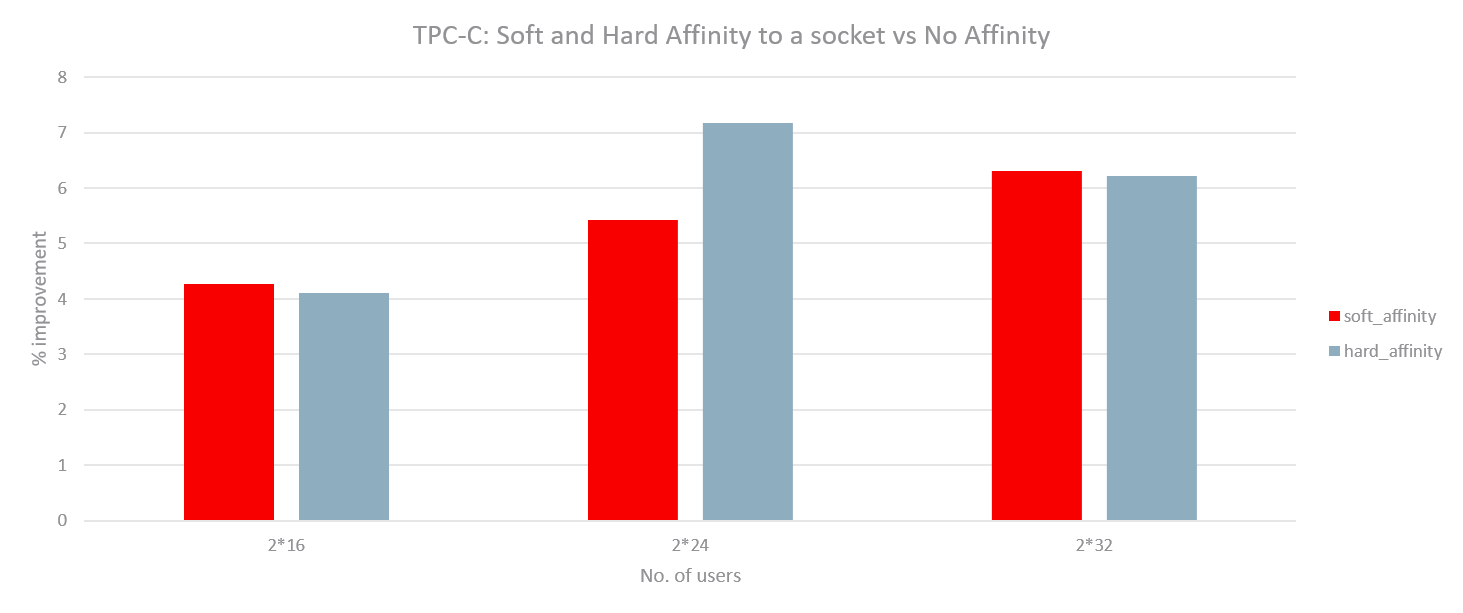
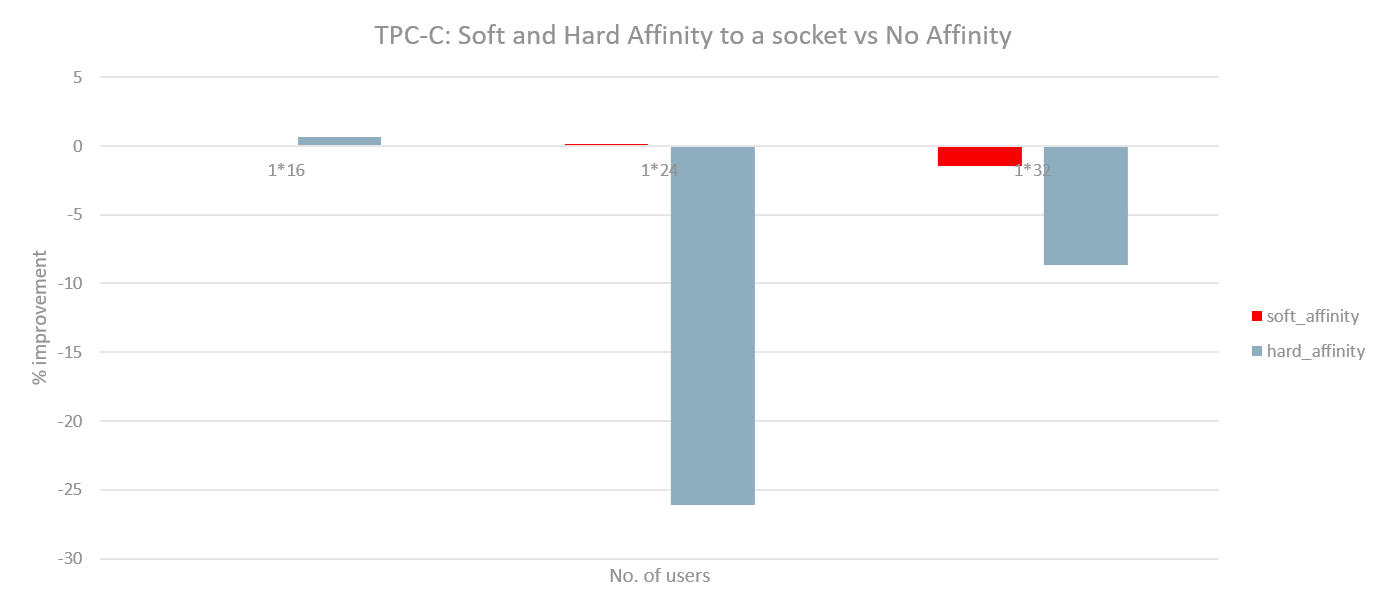
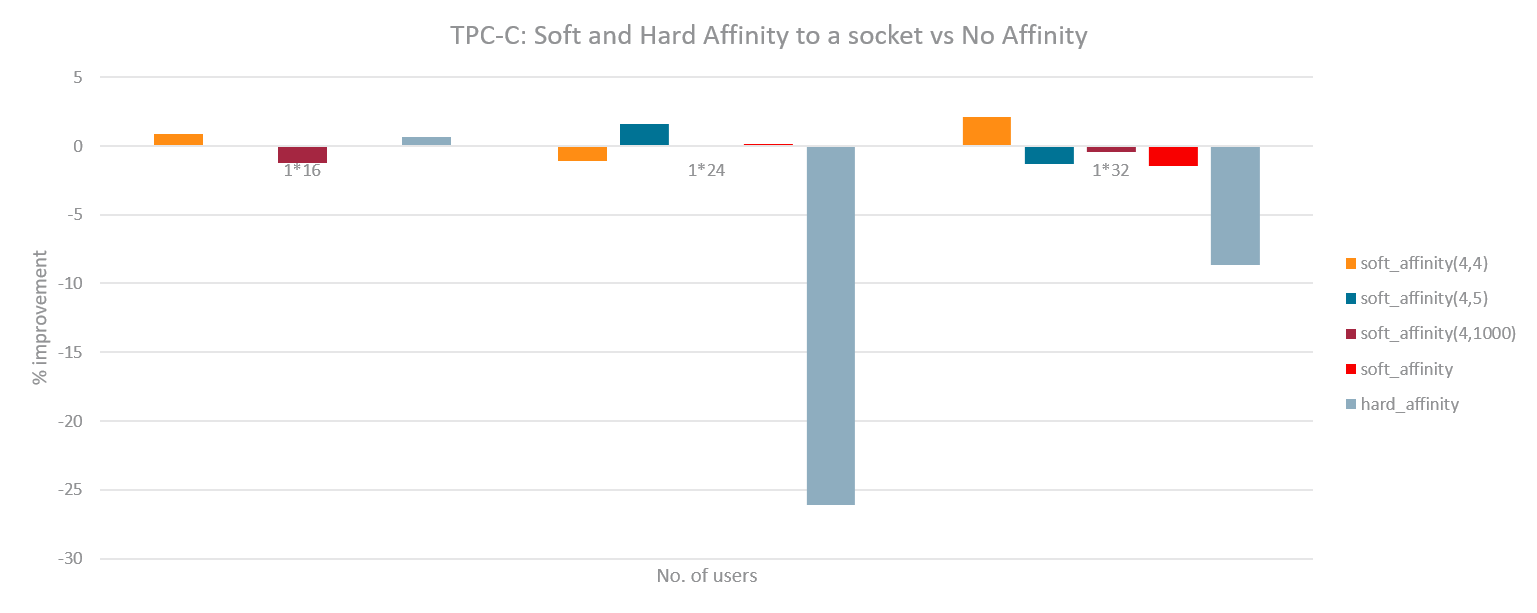
With such an implementation, experiments were run with 2 instances of Hackbench and then 2 instances of DB by soft affinitizing each instance to one NUMA node on a 2-socket system. Another set of runs were done with only 1 instance active but still soft affinitized to the corresponding node. The load in each instance of Hackbench or DB was varied by varying the number of groups and number of users respectively. The following graphs outline the performance gain (or regression) for hard affinity and soft affinity with respect to no affinity. Hackbench shows little improvement for hard or soft affinity (possibly due to less data sharing) while the DB shows substantial improvement for the 2 instance case. For 1 instance, Hackbench shows significant regression while DB achieves performance very close to no affinity. The DB seems to achieve best of both worlds with such a basic implementation: improvement like hard affinity and almost no regression like no affinity.
Load Based Soft Affinity
While basic impleme ntation of Soft Affinity above worked well for DB, Hackbench showed serious regression for 1 instance case due to not using CPUs in the system efficiently. This begs the question: should the decision to trade off cache coherence for CPUs be conditional? The optimum trade off point of a given workload will depend on amount of data sharing between threads, the coherence overhead of the system and how much extra CPUs will help the workload. Unfortunately the kernel can’t find this online, offline workload profiling is needed to quantify the different cost metrics. A reasonable approach to solve this is having kernel tunables that will allow tuning for different workloads. Two scheduler related kernel tunables are introduced for this purpose: sched_preferred and sched_allowed. The ratio of CPU utilization of cpu_preferred set and cpu_allowed set is compared to the ratio sched_allowed:sched_preferred; if greater the scheduler will choose cpu_allowed set in the first level of search, if lesser it will choose the cpu_preferred set. Setting the relative values of the tunables Soft Affinity can be made “harder” or “softer”. To compare the utilization of two sets we can’t iterate over all CPUs as that will add significant overhead. Hence two sample CPUs are chosen, one from each set and compared.
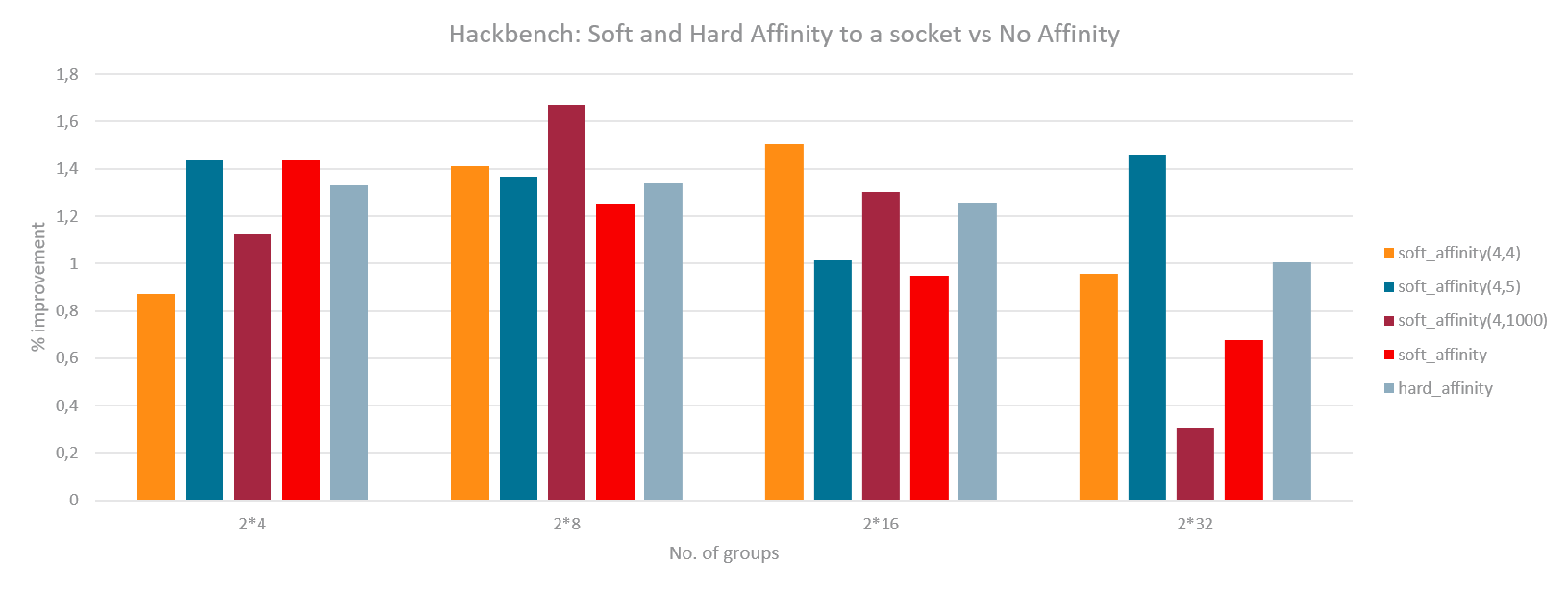
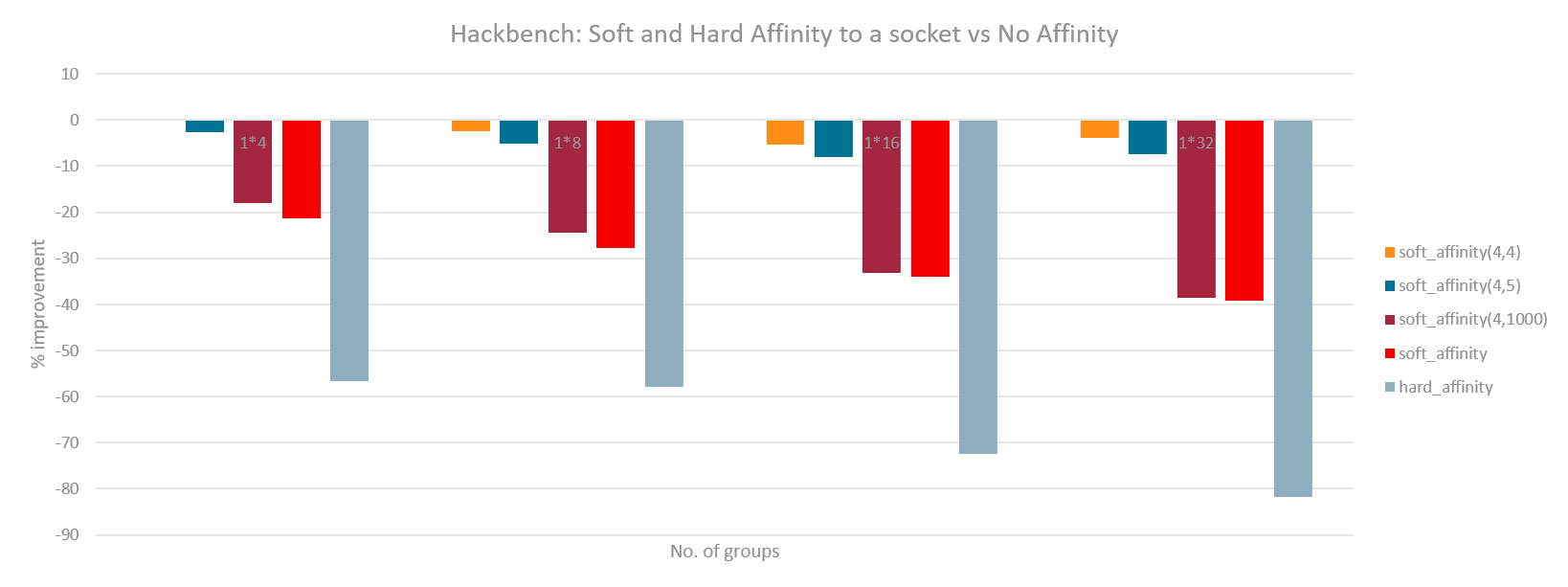
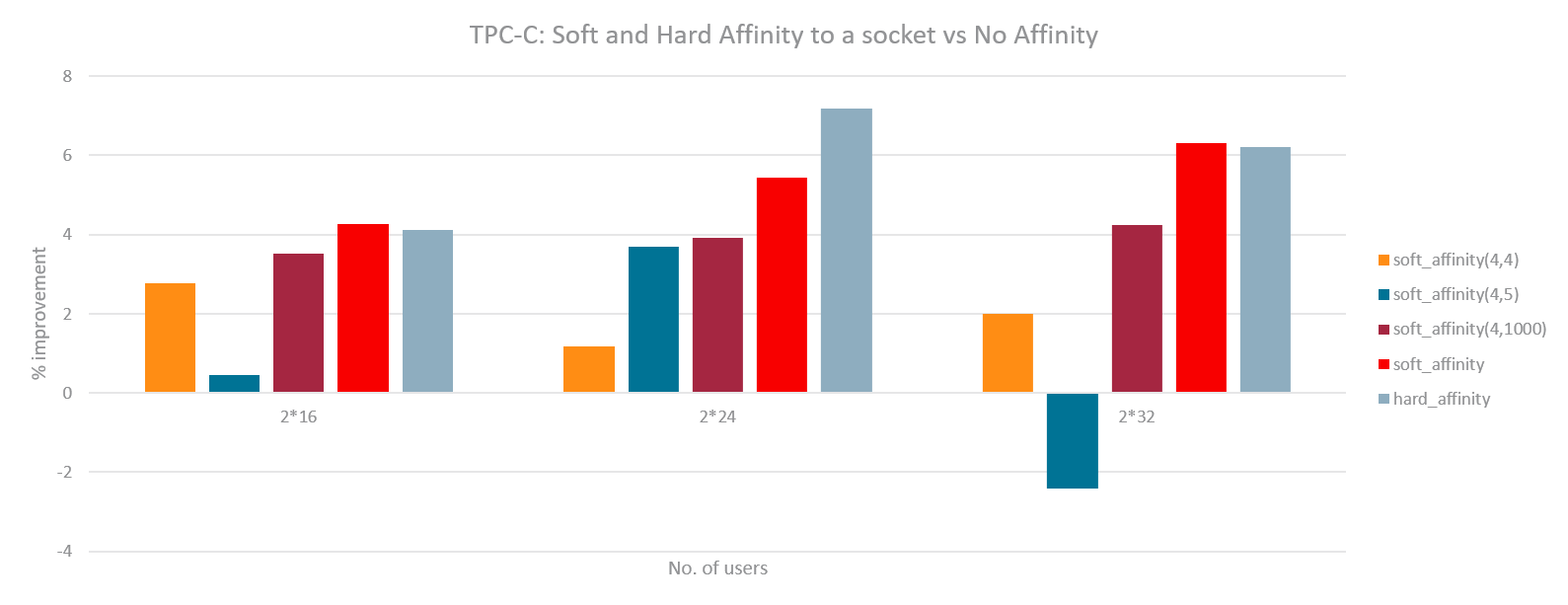
The same experiments were run with the new load based Soft Affinity. Following graphs have the tunable pair (sched_preferred, sched_allowed) sorted from softest to hardest value. As can be seen, for DB case, harder Soft Affinity works best similar to the previous basic implementation. For Hackbench, a softer Soft Affinity works best thereby preserving the improvements but minimizing the regression. A separate set of experiments were also done (graphs not shown) where memory of each DB instance was spread evenly among NUMA nodes. This had similar improvements thus proving that the benefit of partitioning is primarily due to LLC sharing and saving cross socket coherence overhead.
Soft Affinity Overhead
The final goal of Soft Affinity is to introduce no overhead if not used. The scheduler wake-up path adds a few more conditions but breaks early if cpu_preferred == cpu_allowed. This keeps overhead minimal as shown in the following graph which compares the performance of Hackbench for 1 and 2 instance case for a varying number of groups. The difference in the last column is actually the improvement of Soft Affinity kernel with respect to the baseline kernel. This is actually within the noise margin but proves that overhead of Soft Affinity is negligible. The latest version of Soft Affinity with load based tunables has been posted upstream, you can find it here: https://lkml.org/lkml/2019/6/26/1044