Introduction
As Ksplice engineers, we often have to look at completely different sub-systems of the Linux kernel to patch them, either to fix a vulnerability or to add trip wires. As a result, we gain a lot of knowledge on various areas and this time we’ll share our experience with the internals of the pipe and splice syscalls we gained by releasing a a Known exploit detection update for Dirty Pipe.
In this article, we are going to explore the implementation of Linux pipe and splice system call. The pipe system call is used to establish a pair of file descriptors (fd), one fd is used for writing data to the pipe and which can then be read by the other fd. This makes pipes a powerful tool for inter-process communication.
Furthermore, we can leverage it by reading the content of a file from one end and make it available to be accessed by the other end.
For this blog post, I’ve chosen Linux kernel version 5.19 as the foundation for discussing implementation details.
Pipe
Internally pipe utilizes a ring buffer, where each element of the buffer is represented by the pipe_buffer structure:
struct pipe_buffer {
struct page *page;
unsigned int offset, len;
const struct pipe_buf_operations *ops;
unsigned int flags;
unsigned long private;
};
The page member points to the actual page containing the pipe buffer data. The offset and len members specify the portion within the page that can be read from or written to.
Now, let’s delve into the pipe_inode_info strucuture that describes a pipe. It includes the head and tail pointers, indicating the current positions within the pipe_buffer structure mentioned earlier. Additionally, it maintains an array of allocated pipe_buffer instances:
struct pipe_inode_info {
unsigned int head;
unsigned int tail;
unsigned int ring_size;
struct pipe_buffer *bufs;
............
};
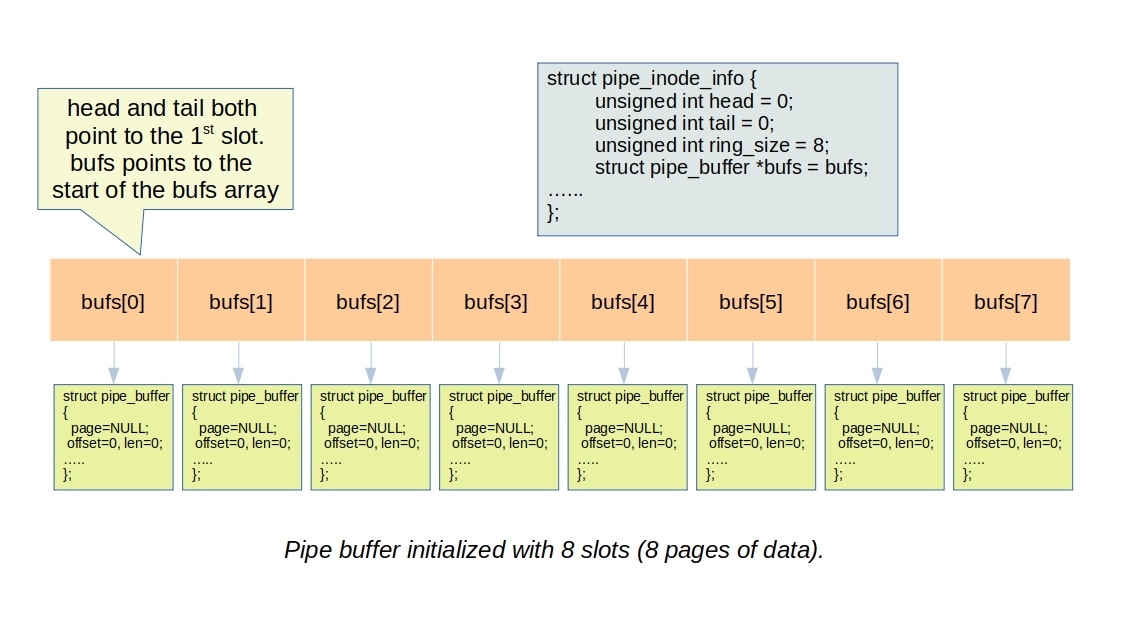
Pipe write
When a user writes to a pipe using the write system call, the Linux kernel internally invokes the pipe_write function located in fs/pipe.c file. Within the pipe_write function, the appropriate pipe_buffer pointed to by the head is selected. The function then allocates a page to store the data, advances the head pointer, and continues this process until it reaches the tail pointer or fulfills all the requested bytes to be written.
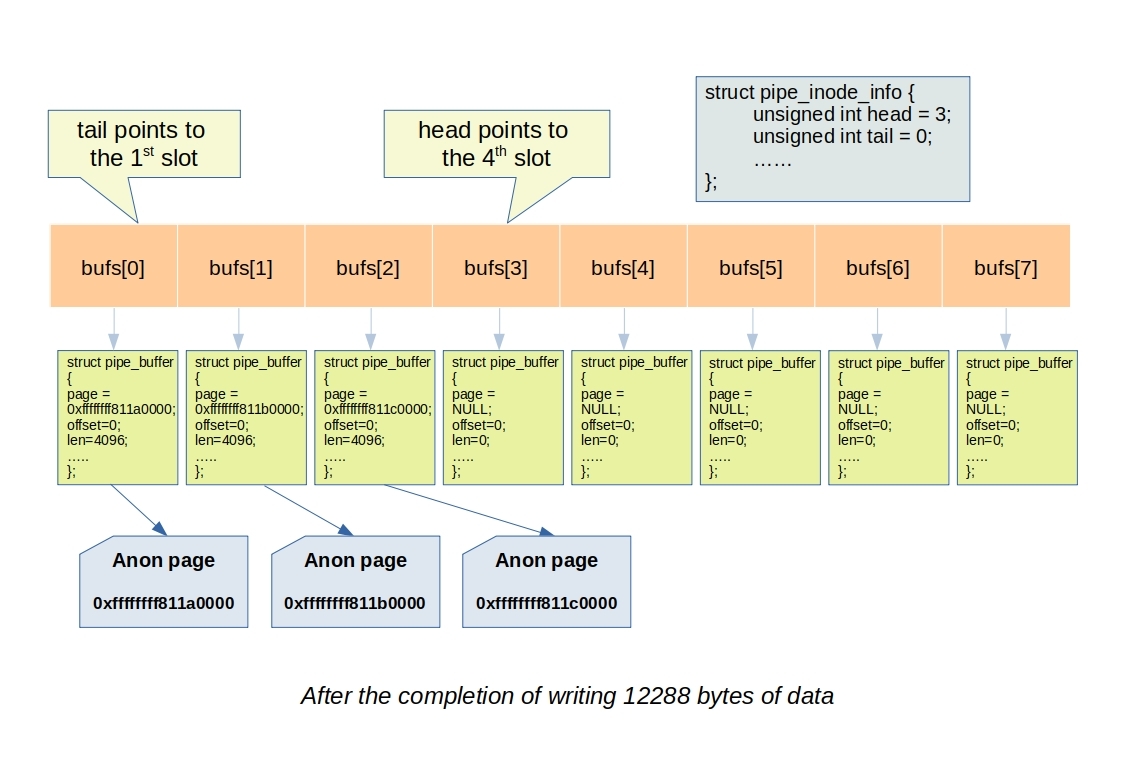
Initially, it selects the current head pointer of the pipe. It also saves the information if the pipe was empty in a variable was_empty, which is used later when waking up a reader starving for data.
head = pipe->head; was_empty = pipe_empty(head, pipe->tail);
The pipe_write function first allocates a page and then checks if the pipe is full using the pipe_full function. If the pipe is not full, it proceeds to advance the head pointer.
for (;;) {
head = pipe->head;
if (!pipe_full(head, pipe->tail, pipe->max_usage)) {
unsigned int mask = pipe->ring_size - 1;
struct pipe_buffer *buf = &pipe->bufs[head & mask];
struct page *page = NULL;
int copied;
if (!page) {
page = alloc_page(GFP_HIGHUSER | __GFP_ACCOUNT);
if (unlikely(!page)) {
ret = ret ? : -ENOMEM;
break;
}
}
/* Allocate a slot in the ring in advance and attach an
* empty buffer. If we fault or otherwise fail to use
* it, either the reader will consume it or it'll still
* be there for the next write.
*/
spin_lock_irq(&pipe->rd_wait.lock);
head = pipe->head;
if (pipe_full(head, pipe->tail, pipe->max_usage)) {
spin_unlock_irq(&pipe->rd_wait.lock);
continue;
}
pipe->head = head + 1;
spin_unlock_irq(&pipe->rd_wait.lock);
Afterwards, the allocated page is inserted into the buffer array at the slot determined by the head pointer. Subsequently, the user buffer is copied to the allocated page.
/* Insert it into the buffer array */
buf = &pipe->bufs[head & mask];
buf->page = page;
buf->ops = &anon_pipe_buf_ops;
buf->offset = 0;
buf->len = 0;
if (is_packetized(filp))
buf->flags = PIPE_BUF_FLAG_PACKET;
else
buf->flags = PIPE_BUF_FLAG_CAN_MERGE;
copied = copy_page_from_iter(page, 0, PAGE_SIZE, from);
if (unlikely(copied < PAGE_SIZE && iov_iter_count(from))) {
if (!ret)
ret = -EFAULT;
break;
}
ret += copied;
buf->offset = 0;
buf->len = copied;
if (!iov_iter_count(from))
break;
}
The pipe_write function, using the above code excerpt, continues to write data to the next available slot in the buffer array by allocating a new page and writing to it. This process repeats as long as all the requested bytes have not been written. However, if there are no more free slots available in the buffer array but there is still more data to write, the function waits on an event. Additionally, if the pipe was empty before the write operation, indicating that there were no pending data for readers, the function wakes up a reader.
if (was_empty)
wake_up_interruptible_sync_poll(&pipe->rd_wait, EPOLLIN | EPOLLRDNORM);
wait_event_interruptible_exclusive(pipe->wr_wait, pipe_writable(pipe));
Stack trace of pipe_write function.
#0 pipe_write (iocb=0xffffc90000affe70, from=0xffffc90000affe48) at fs/pipe.c:417 #1 call_write_iter (file=0xffff88810165ac00, iter=0xffffc90000affe48, kio=0xffffc90000affe70) at ./include/linux/fs.h:2058 #2 new_sync_write (filp=filp@entry=0xffff88810165ac00, buf=buf@entry=0x55da05aa2860 "total 480\ndrwxr-xr-x 8 sr sr 4096 Jul 5 04:17 .\ndrwxr-xr-x 3 root root 4096 Jun 7 2020 ..\n-rwxrwxr-x 1 sr sr 17208 Apr 28 04:48 a.out\n-rw------- 1 sr sr 32142 May 17 02:26 .bash_histo"..., len=2965, ppos=ppos@entry=0x0 <fixed_percpu_data>) at fs/read_write.c:504 #3 vfs_write (pos=0x0 <fixed_percpu_data>, count=2965, buf=0x55da05aa2860 "total 480\ndrwxr-xr-x 8 sr sr 4096 Jul 5 04:17 .\ndrwxr-xr-x 3 root root 4096 Jun 7 2020 ..\n-rwxrwxr-x 1 sr sr 17208 Apr 28 04:48 a.out\n-rw------- 1 sr sr 32142 May 17 02:26 .bash_histo"..., file=0xffff88810165ac00) at fs/read_write.c:591 #4 vfs_write (file=0xffff88810165ac00, buf=0x55da05aa2860 "total 480\ndrwxr-xr-x 8 sr sr 4096 Jul 5 04:17 .\ndrwxr-xr-x 3 root root 4096 Jun 7 2020 ..\n-rwxrwxr-x 1 sr sr 17208 Apr 28 04:48 a.out\n-rw------- 1 sr sr 32142 May 17 02:26 .bash_histo"..., count=2965, pos=0x0 <fixed_percpu_data>) at fs/read_write.c:571 #5 ksys_write (fd=<optimized out>, buf=0x55da05aa2860 "total 480\ndrwxr-xr-x 8 sr sr 4096 Jul 5 04:17 .\ndrwxr-xr-x 3 root root 4096 Jun 7 2020 ..\n-rwxrwxr-x 1 sr sr 17208 Apr 28 04:48 a.out\n-rw------- 1 sr sr 32142 May 17 02:26 .bash_histo"..., count=2965) at fs/read_write.c:644 #6 do_syscall_x64 (nr=<optimized out>, regs=0xffffc90000afff58) at arch/x86/entry/common.c:50 #7 do_syscall_64 (regs=0xffffc90000afff58, nr=<optimized out>) at arch/x86/entry/common.c:80 #8 entry_SYSCALL_64 () at arch/x86/entry/entry_64.S:120
Pipe read
In the following discussion, we will explore the functioning of the read operation on a pipe.
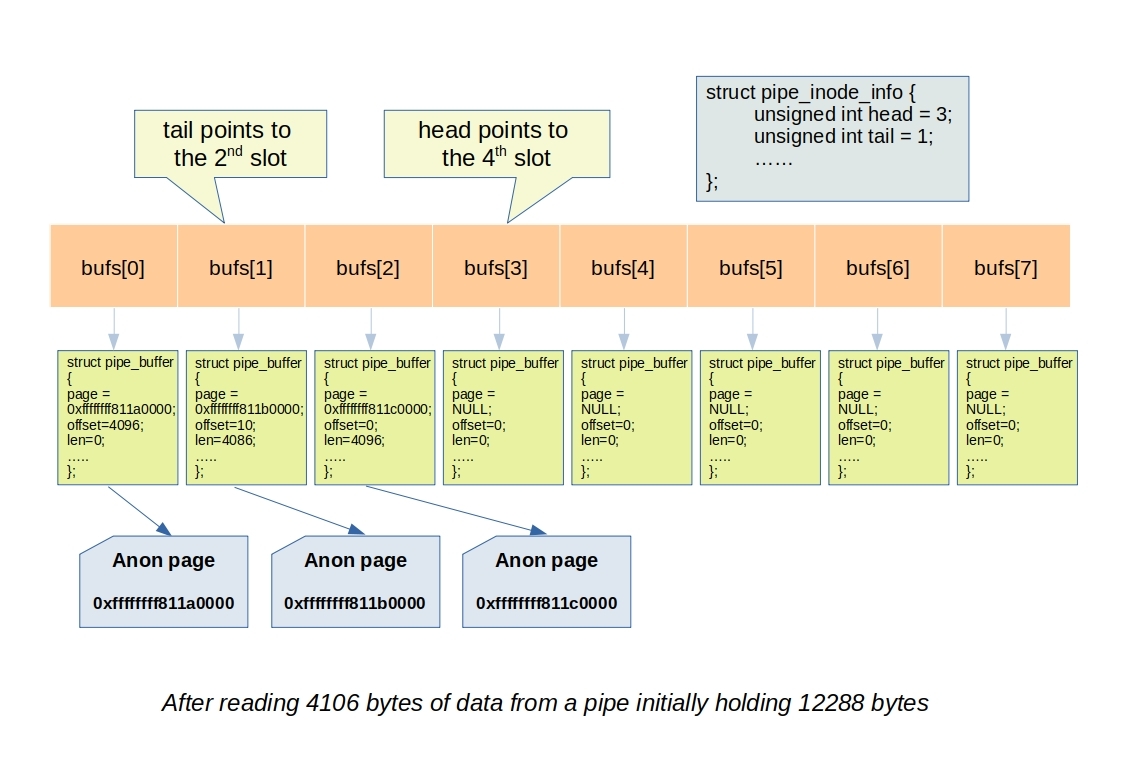
Reading from a pipe is achived through the read system call. Internally it invokes the pipe_read function.
At first, upon acquiring the pipe lock, the read operation first checks if the pipe is already full. It saves this information in a variable called was_full, which will be used later to wake up any writers waiting for the pipe buffer slot to become empty:
was_full = pipe_full(pipe->head, pipe->tail, pipe->max_usage);
Next, the read operation enters a loop to read the content of the file from the pipe. It continues the loop until either all the requested bytes are read from the pipe or if the pipe becomes empty, in which case it waits on an event to be awakened by a writer.
Inside the loop, the operation processes each pipe buffer pointed to by pipe->tail. It copies the content from the associated page of the pipe buffer to the user buffer and advances the pipe->tail pointer. It also checks if the pipe becomes empty by invoking the pipe_empty function. After the first iteration, one of the following three actions is taken:
- The loop continues to the next iteration to read from the next pipe buffer pointed to by
pipe->tail. - The loop is exited upon satisfying the requested length of bytes or if there is no writer available to fulfill the requested data.
- The read operation waits on the
pipe->rd_waitevent because the writer thread is expected to write some bytes to the pipe, which will wake up this thread for reading.
Here is the beginning of the loop, where the tail pointer is initialized from the pipe->tail:
for (;;) {
/* Read ->head with a barrier vs post_one_notification() */
unsigned int head = smp_load_acquire(&pipe->head);
unsigned int tail = pipe->tail;
unsigned int mask = pipe->ring_size - 1;
If the current pipe buffer is not empty, there is data to be copied to the user buffer. The buf->len member is reduced by the amount of data copied:
if (!pipe_empty(head, tail)) {
struct pipe_buffer *buf = &pipe->bufs[tail & mask];
size_t chars = buf->len;
size_t written;
int error;
error = pipe_buf_confirm(pipe, buf);
if (error) {
if (!ret)
ret = error;
break;
}
written = copy_page_to_iter(buf->page, buf->offset, chars, to);
if (unlikely(written < chars)) {
if (!ret)
ret = -EFAULT;
break;
}
ret += chars;
buf->offset += chars;
buf->len -= chars;
Afterwards, it checks if the current pipe buffer becomes empty (buf->len is zero). If so, it advances the pipe->tail to read from the next pipe buffer:
if (!buf->len) {
spin_lock_irq(&pipe->rd_wait.lock);
tail++;
pipe->tail = tail;
spin_unlock_irq(&pipe->rd_wait.lock);
}
total_len -= chars;
When all the bytes requested is satisfied then bail out from the loop.
if (!total_len)
break; /* common path: read succeeded */
If the pipe is not empty and all the requested bytes have not been satisfied, the loop continues:
if (!pipe_empty(head, tail)) /* More to do? */
continue;
}
The next few statements perform the following actions:
- If there is no writer and all the requested bytes have not been satisfied, it breaks out of the loop. It returns the amount of data that has been read (or 0 if no data has been read) from outside the loop.
- If
retcontains the number of bytes read, it breaks out of the loop and returns the number of bytes read from outside the loop. - If it is a non-blocking read request from the user and there is a writer thread, but not a single byte has been read, it returns EGAIN.
if (!pipe->writers)
break;
if (ret)
break;
if (filp->f_flags & O_NONBLOCK) {
ret = -EAGAIN;
break;
}
The following code snippet is executed after the loop. Firstly, it checks if the pipe is empty, in which case it does not wake up any other readers. It uses the was_full variable, which was set right before the loop, to wake up any writer threads that were waiting for a pipe buffer slot to become empty. It then wakes up any other waiting readers. Lastly, it returns the number of bytes read.
if (pipe_empty(pipe->head, pipe->tail))
wake_next_reader = false;
__pipe_unlock(pipe);
if (was_full)
wake_up_interruptible_sync_poll(&pipe->wr_wait, EPOLLOUT | EPOLLWRNORM);
if (wake_next_reader)
wake_up_interruptible_sync_poll(&pipe->rd_wait, EPOLLIN | EPOLLRDNORM);
kill_fasync(&pipe->fasync_writers, SIGIO, POLL_OUT);
if (ret > 0)
file_accessed(filp);
return ret;
Stack trace of pipe_read function:
#0 pipe_read (iocb=0xffffc90000affe78, to=0xffffc90000affe50) at fs/pipe.c:232 #1 call_read_iter (file=0xffff88810165a600, iter=0xffffc90000affe50, kio=0xffffc90000affe78) at ./include/linux/fs.h:2052 #2 new_sync_read (filp=filp@entry=0xffff88810165a600, buf=buf@entry=0x7ffe4f4dc61f "", len=1, ppos=ppos@entry=0x0 <fixed_percpu_data>) at fs/read_write.c:401 #3 vfs_read (pos=0x0 <fixed_percpu_data>, count=1, buf=0x7ffe4f4dc61f "", file=0xffff88810165a600) at fs/read_write.c:482 #4 vfs_read (file=0xffff88810165a600, buf=0x7ffe4f4dc61f "", count=1, pos=0x0 <fixed_percpu_data>) at fs/read_write.c:462 #5 ksys_read (fd=<optimized out>, buf=0x7ffe4f4dc61f "", count=1) at fs/read_write.c:620 #6 do_syscall_x64 (nr=<optimized out>, regs=0xffffc90000afff58) at arch/x86/entry/common.c:50 #7 do_syscall_64 (regs=0xffffc90000afff58, nr=<optimized out>) at arch/x86/entry/common.c:80 #8 entry_SYSCALL_64 () at arch/x86/entry/entry_64.S:120
Splice
Now, let’s delve into the splice system call, which provides an efficient way to read from or write to a file descriptor using a pipe. The splice system call moves data between two file descriptors without the need for copying between kernel address space and user address space. It can transfer up to len bytes of data from the file descriptor fd_in to the file descriptor fd_out, where one of the file descriptors must refer to a pipe.
The definition of the splice system call from the man page is as follows:
ssize_t splice(int fd_in, loff_t *off_in, int fd_out,
loff_t *off_out, size_t len, unsigned int flags);
DESCRIPTION
splice() moves data between two file descriptors without copying between kernel address space and user address
space. It transfers up to len bytes of data from the file descriptor fd_in to the file descriptor fd_out,
where one of the file descriptors must refer to a pipe.
For instance, consider the following splice call, which reads from a file and makes the data available to be read from the pipe. In this example, data is read from the file descriptor fd and transferred to the file descriptor of the pipe referenced by p[1]. This operation is achieved without intermediate data copies, as the pipe buffer directly references the page containing the data from the page cache.
splice(fd, &offset, p[1], NULL, 1, 0);
Now, we are going to explore the internal mechanism of the splice system call. splice works in three modes –
- splice from pipe to pipe.
- splice from file to pipe.
- splice from pipe to file.
The splice system call operates similarly to pipe read or pipe write functions internally. It can either read from a pipe or write to a pipe, depending on the input data source and destination. When the input data source is a file or another pipe, and the destination is a pipe, it functions as a write operation to the pipe. In this mode, it advances the head pointer of the destination pipe to place the data buffer into a pipe buffer slot. However, instead of copying the data, it establishes a reference to the buffer from the source file or another pipe.
On the other hand, if the input data source for splice is a pipe and the destination is either a file or another pipe, it behaves like a read operation from the pipe. In this scenario, the tail pointer of the pipe is advanced, and rather than copying the data, the other pipe references the page from the current pipe buffer slot. This way, splice enables efficient data transfer between different data sources and destinations without unnecessary data duplication.
Splice from pipe to pipe
Splicing from one pipe to another is the simplest form of splice operation that efficiently moves data between two pipes without the need for data copying.
Below is a depiction of two images. The initial image represents the state before the splice operation, while the subsequent one portrays the state after the splice operation.
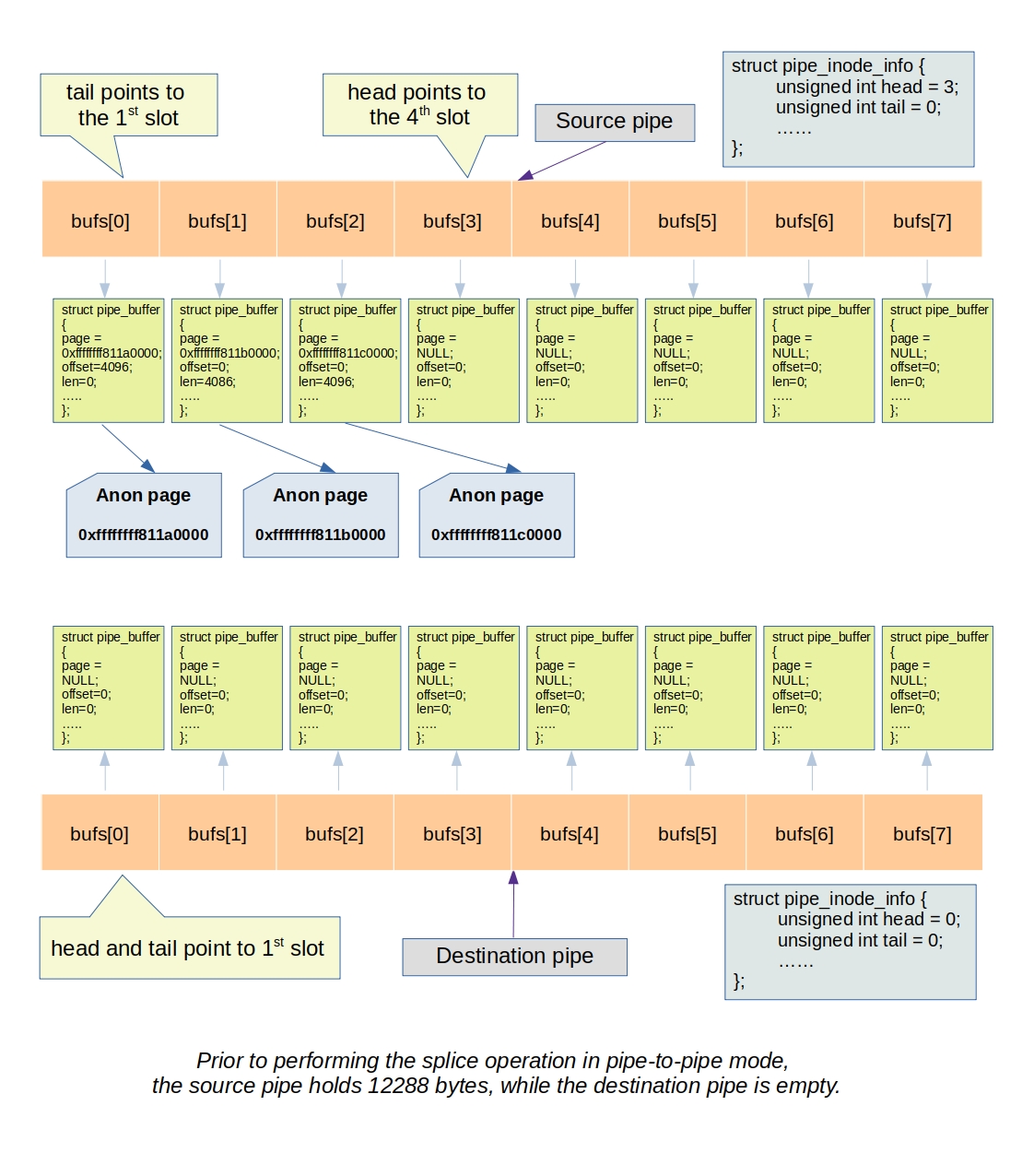
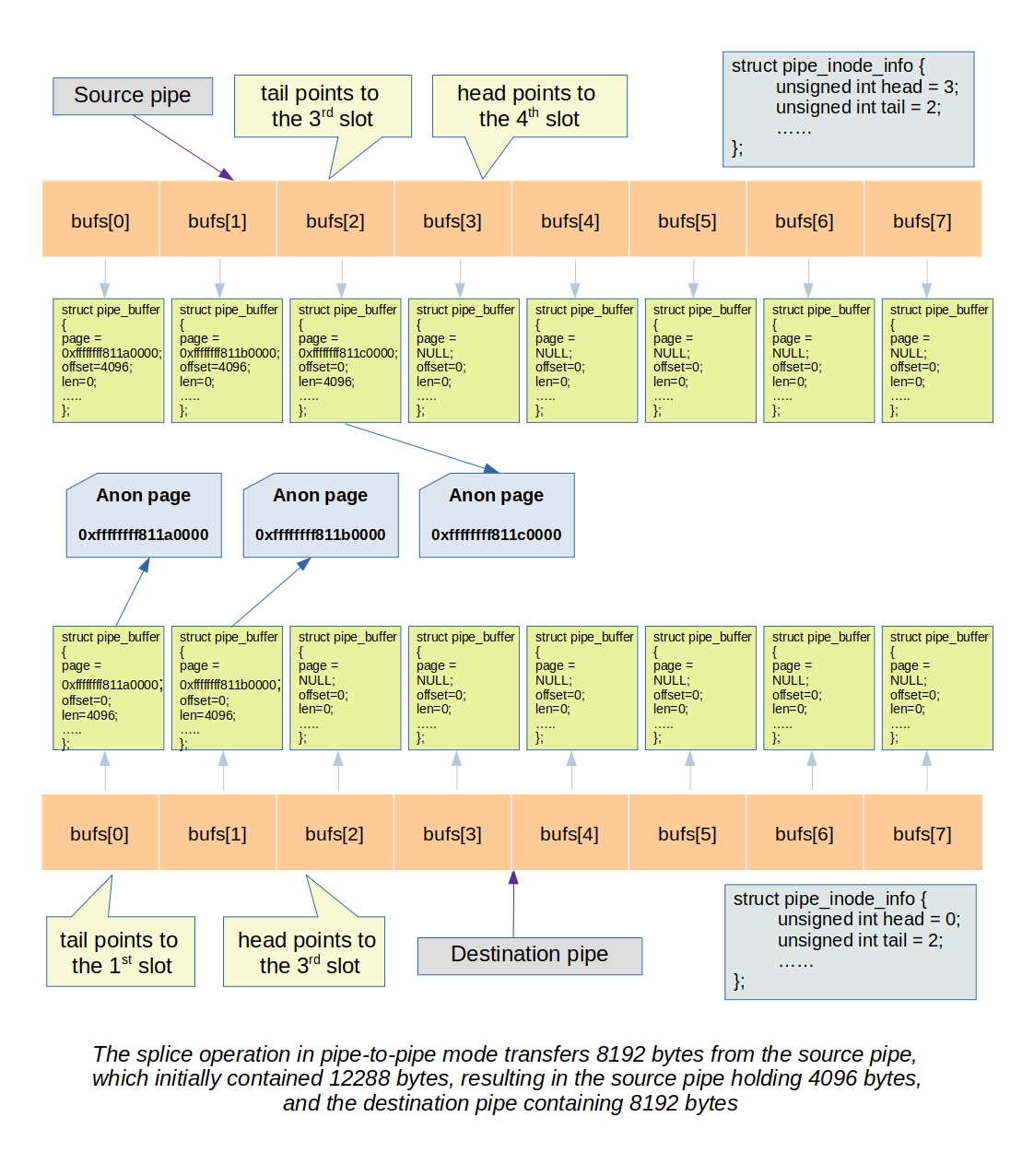
To demonstrate this process, consider the following example where we create two pipes, p_in and p_out. We write data into p_in and then use the splice system call to transfer the data from p_in to p_out:
int p_in[2], p_out[2]; pipe(p_in); pipe(p_out); write(p_in[1], data, 8192); splice(p_in[0], NULL, p_out[1], NULL, 8192, 0);
Let’s explore the process of the splice call responsible for moving data from one pipe to another. In this operation, the pointer to the page containing data from the input pipe’s buffer is directly transferred to the output pipe’s buffer. As a result, it advances the head pointer of the output pipe and the tail pointer of the input pipe, where the head pointer selects the pipe buffer slot for writing, and the tail pointer selects the pipe buffer slot for reading.
The splice_pipe_to_pipe function, located in fs/splice.c, is responsible for handling the functionality of moving data from one pipe to another. Let’s examine the code in detail.
The process starts by preparing the input and output pipes. This preparation ensures that the input pipe has data available (i.e., it is not empty) and that the output pipe has space for data (i.e., it is not full). If there is no data in the input pipe, the function waits on ipipe->rd_wait, expecting a writer on that pipe to wake it up. Similarly, if the output pipe is full, it waits on opipe->wr_wait, so that a reader on that pipe can wake it up after reading data and freeing up at least one pipe buffer slot.
Both the ipipe_prep and opipe_prep functions acquire their respective pipe mutexes at the beginning of the function and release them at the end. However, there exists a window where the code ensures that data is present in the input pipe and space is available in the output pipe. Nevertheless, right after releasing the pipe mutex, the data from the input pipe might be entirely consumed by another thread, or the output pipe might be written in a way that leaves no space available. The presence of the retry label ensures that the operation is retried, moving at least one byte, in case such a scenario occurs.
retry:
ret = ipipe_prep(ipipe, flags);
if (ret)
return ret;
ret = opipe_prep(opipe, flags);
if (ret)
return ret;
After obtaining the correct order of pipe locks, it proceeds by initializing local variables. It sets the head variable for the output pipe, the tail variable for the input pipe, and creates masks for the input and output pipes. These variables are initialized outside the main loop where data is moved, as the pointers associated with the pipes will be updated within the loop during the data transfer process.
During this process, the i_tail is advanced after reading from the input pipe, while the o_head is advanced immediately after writing to the output pipe. In this context, “reading” and “writing” refer to the act of moving the page pointer from the pipe buffer selected by the i_tail pointer of the input pipe to the pipe buffer selected by the o_head pointer of the output pipe.
pipe_double_lock(ipipe, opipe);
i_tail = ipipe->tail;
i_mask = ipipe->ring_size - 1;
o_head = opipe->head;
o_mask = opipe->ring_size - 1;
do {
Within the loop, it initializes the input pipe buffer pointer i_head and the output tail pointer o_tail. These pointers are used to check if the input pipe becomes empty or the output pipe becomes full while data is being transferred between the pipes. If either of these conditions occurs, it becomes impossible to move the page pointer from the input to the output pipe.
In such a scenario, if some amount of data has already been transferred (ret is non-zero), the function breaks out of the loop, as there is no further data to transfer. However, if the function has not transferred any data yet, it needs to retry the splice operation to ensure that at least one byte of data is moved. To achieve this, it uses the goto statement to return to the beginning of the function and start the process again, thus attempting to move at least one byte of data between the pipes.
if (pipe_empty(i_head, i_tail) ||
pipe_full(o_head, o_tail, opipe->max_usage)) {
/* Already processed some buffers, break */
if (ret)
break;
if (flags & SPLICE_F_NONBLOCK) {
ret = -EAGAIN;
break;
}
/*
* We raced with another reader/writer and haven't
* managed to process any buffers. A zero return
* value means EOF, so retry instead.
*/
pipe_unlock(ipipe);
pipe_unlock(opipe);
goto retry;
}
Next, it selects the pipe buffer pointers for the input and output pipe.
ibuf = &ipipe->bufs[i_tail & i_mask];
obuf = &opipe->bufs[o_head & o_mask];
The data movement process between the pipes is as follows:
If the number of requested bytes to read is greater than the number of bytes the current input pipe buffer contains, a full page containing the data is moved from the input pipe buffer to the output pipe buffer. After the transfer, the tail pointer of the input pipe is advanced, indicating that the slot has been consumed and is now freed for the writers on this pipe to use.
On the other hand, if we are reading only a partial amount from an input pipe buffer (i.e., the requested number of bytes is less than the content length present in the buffer), the page containing the data is shared between the input and output pipe buffers. This sharing is achieved by calling the pipe_buf_get function. In this case, the input buffer pipe’s offset is increased, and its length is decreased by the number of bytes read. However, the tail pointer of the input pipe is not advanced in this situation, as the partial read does not completely consume the data in the buffer.
if (len >= ibuf->len) {
/*
* Simply move the whole buffer from ipipe to opipe
*/
*obuf = *ibuf;
ibuf->ops = NULL;
i_tail++;
ipipe->tail = i_tail;
input_wakeup = true;
o_len = obuf->len;
o_head++;
opipe->head = o_head;
} else {
/*
* Get a reference to this pipe buffer,
* so we can copy the contents over.
*/
if (!pipe_buf_get(ipipe, ibuf)) {
if (ret == 0)
ret = -EFAULT;
break;
}
*obuf = *ibuf;
/*
* Don't inherit the gift and merge flags, we need to
* prevent multiple steals of this page.
*/
obuf->flags &= ~PIPE_BUF_FLAG_GIFT;
obuf->flags &= ~PIPE_BUF_FLAG_CAN_MERGE;
obuf->len = len;
ibuf->offset += len;
ibuf->len -= len;
o_len = len;
o_head++;
opipe->head = o_head;
}
Inside the loop, the number of read/write bytes is increased as data is successfully moved from the input pipe buffer to the output pipe buffer. Simultaneously, the length of the data in the respective pipe buffers is decreased accordingly.
ret += o_len;
len -= o_len;
} while (len);
After the loop completes and all the necessary data transfer operations have been performed, the function proceeds to unlock the pipes, releasing the locks acquired earlier in the process.
Subsequently, it wakes up any reader on the output pipe if data was moved, and it also wakes up writers on the input pipe if the tail pointer is advanced, indicating that the pipe buffer slot is free. Finally, it returns the number of bytes moved or an error code.
pipe_unlock(ipipe);
pipe_unlock(opipe);
/*
* If we put data in the output pipe, wakeup any potential readers.
*/
if (ret > 0)
wakeup_pipe_readers(opipe);
if (input_wakeup)
wakeup_pipe_writers(ipipe);
return ret;
Stack trace of splice_pipe_to_pipe function
#0 splice_pipe_to_pipe (flags=0, len=<optimized out>, opipe=0xffff88810e897f00, ipipe=0xffff88810e897c00) at fs/splice.c:1446 #1 do_splice (in=in@entry=0xffff8881017d7d00, off_in=off_in@entry=0x0 <fixed_percpu_data>, out=out@entry=0xffff88810cd7c200, off_out=<optimized out>, off_out@entry=0x0 <fixed_percpu_data>, len=12288, flags=0) at fs/splice.c:1054 #2 __do_splice (flags=<optimized out>, len=<optimized out>, off_out=0x0 <fixed_percpu_data>, out=0xffff88810cd7c200, off_in=0x0 <fixed_percpu_data>, in=0xffff8881017d7d00) at fs/splice.c:1144 #3 __do_sys_splice (fd_in=<optimized out>, off_in=0x0 <fixed_percpu_data>, fd_out=<optimized out>, off_out=0x0 <fixed_percpu_data>, len=<optimized out>, flags=<optimized out>) at fs/splice.c:1350 #4 do_syscall_x64 (nr=<optimized out>, regs=0xffffc90000ccbf58) at arch/x86/entry/common.c:50 #5 do_syscall_64 (regs=0xffffc90000ccbf58, nr=<optimized out>) at arch/x86/entry/common.c:80 #6 entry_SYSCALL_64 () at arch/x86/entry/entry_64.S:120
Splice from file to pipe
Splicing from a file to a pipe allows sharing the page cache data buffer with the pipe, avoiding data copying when reading from a pipe fed by a file. Unlike the typical scenario where we use the write system call on the pipe to feed data, in this case, data is sourced from a file.
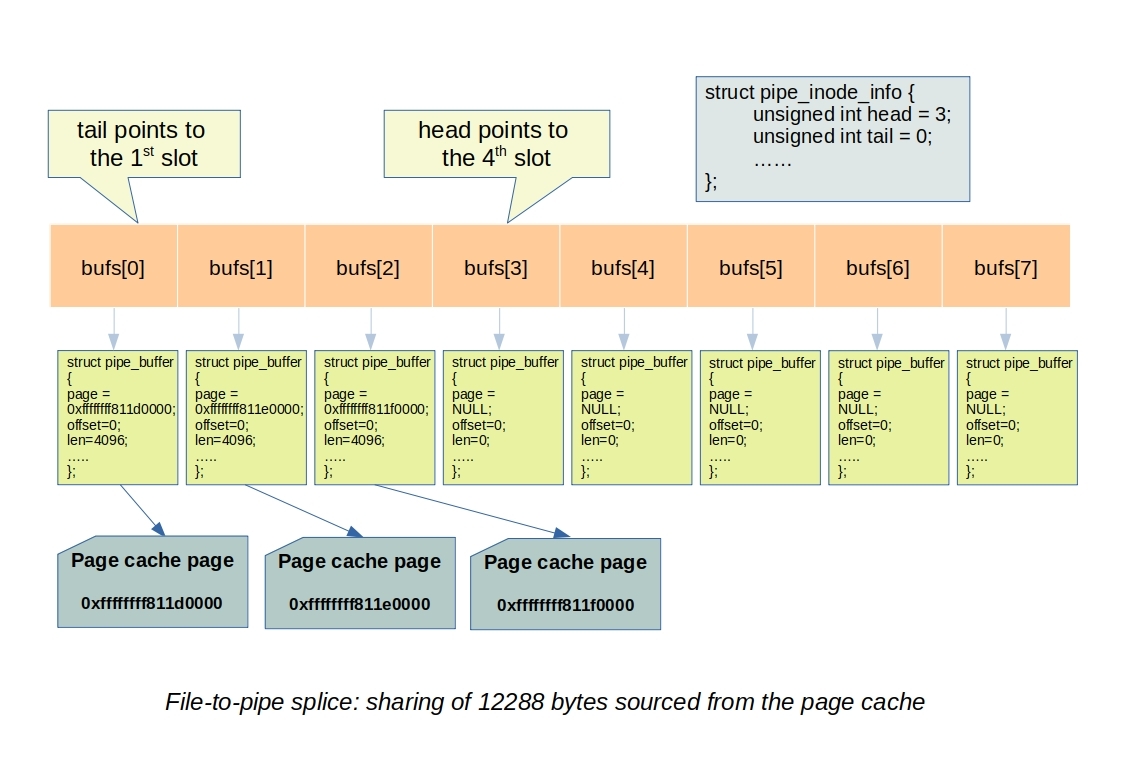
The process of sharing the page cache starts from the splice_file_to_pipe function (fs/splice.c) and involves various filesystem and memory management functions to achieve page cache sharing. Initially, this function ensures that there is at least one slot available in the pipe buffer ring, allowing pipe buffer(s) to be allocated. After this preparation, it calls do_splice_to.
The do_splice_to function calculates the maximum number of bytes it can write from the requested length and calls the file pointer’s splice_read function.
return in->f_op->splice_read(in, ppos, pipe, len, flags);
For the ext4 filesystem, the splice_read function pointer points to the generic_file_splice_read function (fs/splice.c).
const struct file_operations ext4_file_operations = {
............
.read_iter = ext4_file_read_iter,
.write_iter = ext4_file_write_iter,
............
.splice_read = generic_file_splice_read,
.splice_write = iter_file_splice_write,
............
};
The generic_file_splice_read function initializes an iov_iter for the pipe (iov_iter is an iterator for input/output vectors that define data buffer of type iovec, kvec, bio_vec, xarray, pipe or simply a user buffer).
A kiocb type local variable is also declared and initialized to assist the kernel mode function in wrapping our input file pointer (i.e., the file pointer of the data source). It helps specify the offset of the file from which the caller wants to read and to be notified of the current file position after reading is completed. The number of bytes to read is requested using the iov_iter data structure, initialized with the len parameter.
Next, it calls the call_read_iter, which accepts the pipe iterator and the kiocb. The call_read_iter reads the content from the file pointed to by the kiocb and transfers data into the data buffer pointed to by the iov_iter (in this casem a pipe iterator).
If the call_read_iter succeeds, it returns the number of bytes read. Otherwise it calls iov_iter_advance, which truncates the pipe buffer to revert any partial read. It does this by specifying the head pointer in the iterator, and the function pipe_truncate releases the pipe buffer advanced by any partial read.
struct iov_iter to;
struct kiocb kiocb;
unsigned int i_head;
int ret;
iov_iter_pipe(&to, READ, pipe, len);
i_head = to.head;
init_sync_kiocb(&kiocb, in);
kiocb.ki_pos = *ppos;
ret = call_read_iter(in, &kiocb, &to);
if (ret > 0) {
*ppos = kiocb.ki_pos;
file_accessed(in);
} else if (ret < 0) {
to.head = i_head;
to.iov_offset = 0;
iov_iter_advance(&to, 0); /* to free what was emitted */
}
return ret;
The call_read_iter function simply calls the read_iter function pointer specified by the filesystem. In the case of the ext4 filesystem, this function pointer points to ext4_file_read_iter. Eventually, it reaches the generic_file_read_iter function (mm/filemap.c).
Since this is not a direct IO read, it invokes filemap_read, defined in the same file, which takes both kiocb and iov_iter as function parameters.
The filemap function initializes the folio batch using folio_batch_init function (a folio is the base page of consecutive pages). The folio batch is needed because page cache pages can be non-consecutive, and we want to iterate over all the folio pages in the requested range. folio batch helps in this scenario.
Next, it calls filemap_get_pages to fill up the folio batch. After filling up the folio batch, the function enumerates each of the folio pages in the folllowing loop and call copy_page_to_iter from copy_folio_to_iter routine to transfer the data from the page cache pages in the folio into the desired iov iterator referenced by iter.
for (i = 0; i < folio_batch_count(&fbatch); i++) {
struct folio *folio = fbatch.folios[i];
size_t fsize = folio_size(folio);
size_t offset = iocb->ki_pos & (fsize - 1);
size_t bytes = min_t(loff_t, end_offset - iocb->ki_pos,
fsize - offset);
size_t copied;
if (end_offset < folio_pos(folio))
break;
if (i > 0)
folio_mark_accessed(folio);
/*
* If users can be writing to this folio using arbitrary
* virtual addresses, take care of potential aliasing
* before reading the folio on the kernel side.
*/
if (writably_mapped)
flush_dcache_folio(folio);
copied = copy_folio_to_iter(folio, offset, bytes, iter);
already_read += copied;
iocb->ki_pos += copied;
ra->prev_pos = iocb->ki_pos;
if (copied < bytes) {
error = -EFAULT;
break;
}
}
put_folios:
for (i = 0; i < folio_batch_count(&fbatch); i++)
folio_put(fbatch.folios[i]);
folio_batch_init(&fbatch);
} while (iov_iter_count(iter) && iocb->ki_pos < isize && !error);
file_accessed(filp);
return already_read ? already_read : error;
The copy_page_to_iter function calls the _copy_page_to_iter in a loop to handle one page at a time. _copy_page_to_iter is designed to handle different iov iterator types and calls the appropriate copy function accordingly.
static size_t __copy_page_to_iter(struct page *page, size_t offset, size_t bytes,
struct iov_iter *i)
{
if (likely(iter_is_iovec(i)))
return copy_page_to_iter_iovec(page, offset, bytes, i);
if (iov_iter_is_bvec(i) || iov_iter_is_kvec(i) || iov_iter_is_xarray(i)) {
void *kaddr = kmap_local_page(page);
size_t wanted = _copy_to_iter(kaddr + offset, bytes, i);
kunmap_local(kaddr);
return wanted;
}
if (iov_iter_is_pipe(i))
return copy_page_to_iter_pipe(page, offset, bytes, i);
if (unlikely(iov_iter_is_discard(i))) {
if (unlikely(i->count < bytes))
bytes = i->count;
i->count -= bytes;
return bytes;
}
WARN_ON(1);
return 0;
}
The function copy_page_to_iter_pipe is specifically used when transferring data between file data backed by the page cache and a pipe. It initially checks if the pipe is full; if so, there’s insufficient space to place the page cache page into the pipe, resulting in a simple return of 0.
However, if the pipe has an available slot, the function references the page and assigns buf->page (i.e. pipe buffer data page pointer) to the page cache page. In this case, the pipe buffer slot shares the data buffer with the page cache page, eliminating the need to allocate a new buffer and copy the entire content from the page cache. Finally, it advances the pipe’s head pointer.
struct pipe_inode_info *pipe = i->pipe;
struct pipe_buffer *buf;
unsigned int p_tail = pipe->tail;
unsigned int p_mask = pipe->ring_size - 1;
unsigned int i_head = i->head;
buf = &pipe->bufs[i_head & p_mask];
if (pipe_full(i_head, p_tail, pipe->max_usage))
return 0;
buf->ops = &page_cache_pipe_buf_ops;
buf->flags = 0;
get_page(page);
buf->page = page;
buf->offset = offset;
buf->len = bytes;
pipe->head = i_head + 1;
i->iov_offset = offset + bytes;
i->head = i_head;
i->count -= bytes;
return bytes;
Stack trace of splice from file to pipe
#0 copy_page_to_iter_pipe (i=0xffffc900011fbd90, bytes=1, offset=0, page=0xffffea0004995640) at lib/iov_iter.c:385 #1 __copy_page_to_iter (i=0xffffc900011fbd90, bytes=1, offset=0, page=0xffffea0004995640) at lib/iov_iter.c:860 #2 copy_page_to_iter (page=page@entry=0xffffea0004995640, offset=0, bytes=bytes@entry=1, i=i@entry=0xffffc900011fbd90) at lib/iov_iter.c:880 #3 copy_folio_to_iter (i=0xffffc900011fbd90, bytes=1, offset=<optimized out>, folio=0xffffea0004995640) at ./include/linux/uio.h:153 #4 filemap_read (iocb=0xffffc900011fbdb8, iter=0xffffc900011fbd90, already_read=0) at mm/filemap.c:2739 #5 call_read_iter (file=0xffff888102ee7900, iter=0xffffc900011fbd90, kio=0xffffc900011fbdb8) at ./include/linux/fs.h:2052 #6 generic_file_splice_read (in=0xffff888102ee7900, ppos=0xffffc900011fbe88, pipe=<optimized out>, len=<optimized out>, flags=<optimized out>) at fs/splice.c:311 #7 splice_file_to_pipe (in=in@entry=0xffff888102ee7900, opipe=opipe@entry=0xffff88810e897900, offset=offset@entry=0xffffc900011fbe88, len=len@entry=1, flags=flags@entry=0) at fs/splice.c:1018 #8 do_splice (in=in@entry=0xffff888102ee7900, off_in=off_in@entry=0xffffc900011fbef8, out=out@entry=0xffff888102ee7200, off_out=off_out@entry=0x0 <fixed_percpu_data>, len=1, flags=0) at fs/splice.c:1104 #9 __do_splice (flags=<optimized out>, len=<optimized out>, off_out=0x0 <fixed_percpu_data>, out=0xffff888102ee7200, off_in=0x7fff887c5430, in=0xffff888102ee7900) at fs/splice.c:1144 #10 __do_sys_splice (fd_in=<optimized out>, off_in=0x7fff887c5430, fd_out=<optimized out>, off_out=0x0 <fixed_percpu_data>, len=<optimized out>, flags=<optimized out>) at fs/splice.c:1350 #11 do_syscall_x64 (nr=<optimized out>, regs=0xffffc900011fbf58) at arch/x86/entry/common.c:50 #12 do_syscall_64 (regs=0xffffc900011fbf58, nr=<optimized out>) at arch/x86/entry/common.c:80 #13 entry_SYSCALL_64 () at arch/x86/entry/entry_64.S:120
Splice from pipe to file
Splicing from a pipe to a file enables transferring data from a pipe buffer to a file. This process is achieved by iterating through all the pipe buffer slots that contain data and calling a VFS (Virtual File System) routine to write the content to the output file.
Consider the following example:
int p[2]; pipe(p); write(p[1], data, 8192); splice(p[0], NULL, fd, NULL, 8192, 0);
In this example, fd is a file descriptor previously opened with O_RDWR flag. Upon calling splice system call, the kernel invokes do_splice_from function from do_splice. The do_splice_from calls the splice_write function implemented by the file operation pointer of the output file, where we want to copy the data.
return out->f_op->splice_write(pipe, out, ppos, len, flags);
For the ext4 filesystem, the iter_file_splice_write function is used to implement the splice_write functionality. iter_file_splice_write reads from the pipe by enumerating all the pipe buffer slots (i,e, advancing the tail pointer on each iteration), initializes a bio_vec array with the pages obtained from pipe buffer slots, and then calls vfs_iter_write to write the content of the pages from the bvec array to the out file.
The implementation of iter_file_splice_write starts by initializing a variable called sd, which encapsulates all the offset and length information needed for writing. Next, it allocates the bio_vec array to hold all the pages from the pipe.
struct splice_desc sd = {
.total_len = len,
.flags = flags,
.pos = *ppos,
.u.file = out,
};
int nbufs = pipe->max_usage;
struct bio_vec *array = kcalloc(nbufs, sizeof(struct bio_vec),
GFP_KERNEL);
head = pipe->head;
tail = pipe->tail;
mask = pipe->ring_size - 1;
It then enters a loop to initialize the bio_vec array elements with the pages from pipe buffer slots (i.e. each of array element contains a page from each of the buffer slot).
/* build the vector */
left = sd.total_len;
for (n = 0; !pipe_empty(head, tail) && left && n < nbufs; tail++) {
struct pipe_buffer *buf = &pipe->bufs[tail & mask];
size_t this_len = buf->len;
/* zero-length bvecs are not supported, skip them */
if (!this_len)
continue;
this_len = min(this_len, left);
ret = pipe_buf_confirm(pipe, buf);
if (unlikely(ret)) {
if (ret == -ENODATA)
ret = 0;
goto done;
}
array[n].bv_page = buf->page;
array[n].bv_len = this_len;
array[n].bv_offset = buf->offset;
left -= this_len;
n++;
}
Subsequently, the function initializes a bvec iterator with the array just prepared and calls vfs_iter_write to invoke file system, effectively writing the pages from the iterator.
iov_iter_bvec(&from, WRITE, array, n, sd.total_len - left);
ret = vfs_iter_write(out, &from, &sd.pos, 0);
if (ret <= 0)
break;
After the write operation, it advances the tail pointer of the pipe for the fully consumed buffers by the vfs_iter_write.
/* dismiss the fully eaten buffers, adjust the partial one */
tail = pipe->tail;
while (ret) {
struct pipe_buffer *buf = &pipe->bufs[tail & mask];
if (ret >= buf->len) {
ret -= buf->len;
buf->len = 0;
pipe_buf_release(pipe, buf);
tail++;
pipe->tail = tail;
if (pipe->files)
sd.need_wakeup = true;
} else {
buf->offset += ret;
buf->len -= ret;
ret = 0;
}
}
This process repeats until all the data from the pipe buffer is written to the file.
Stack trace of splice from file to pipe
#0 __filemap_add_folio (mapping=mapping@entry=0xffff888102a39e30, folio=folio@entry=0xffffea00047fad00, index=index@entry=0, gfp=3264, gfp@entry=1055946, shadowp=shadowp@entry=0xffffc90000c0ba88) at mm/filemap.c:917 #1 filemap_add_folio (mapping=mapping@entry=0xffff888102a39e30, folio=folio@entry=0xffffea00047fad00, index=index@entry=0, gfp=gfp@entry=1055946) at mm/filemap.c:959 #2 __filemap_get_folio (mapping=mapping@entry=0xffff888102a39e30, index=index@entry=0, fgp_flags=fgp_flags@entry=526, gfp=1055946) at mm/filemap.c:2003 #3 pagecache_get_page (mapping=mapping@entry=0xffff888102a39e30, index=index@entry=0, fgp_flags=fgp_flags@entry=526, gfp=<optimized out>) at mm/folio-compat.c:126 #4 grab_cache_page_write_begin (mapping=mapping@entry=0xffff888102a39e30, index=index@entry=0) at ./include/linux/pagemap.h:274 #5 ext4_da_write_begin (file=<optimized out>, mapping=0xffff888102a39e30, pos=0, len=4096, pagep=0xffffc90000c0bbd8, fsdata=<optimized out>) at fs/ext4/inode.c:2977 #6 generic_perform_write (iocb=iocb@entry=0xffffc90000c0bcf0, i=i@entry=0xffffc90000c0bdb8) at mm/filemap.c:3779 #7 ext4_buffered_write_iter (iocb=iocb@entry=0xffffc90000c0bcf0, from=from@entry=0xffffc90000c0bdb8) at fs/ext4/file.c:270 #8 ext4_file_write_iter (iocb=0xffffc90000c0bcf0, from=0xffffc90000c0bdb8) at fs/ext4/file.c:679 #9 call_write_iter (file=<optimized out>, iter=<optimized out>, kio=<optimized out>) at ./include/linux/fs.h:2058 #10 do_iter_readv_writev (filp=filp@entry=0xffff88810f06bf00, iter=iter@entry=0xffffc90000c0bdb8, ppos=ppos@entry=0xffffc90000c0bdf8, type=type@entry=1, flags=flags@entry=0) at fs/read_write.c:742 #11 do_iter_write (flags=0, pos=0xffffc90000c0bdf8, iter=0xffffc90000c0bdb8, file=0xffff88810f06bf00) at fs/read_write.c:868 #12 do_iter_write (file=0xffff88810f06bf00, iter=0xffffc90000c0bdb8, pos=0xffffc90000c0bdf8, flags=0) at fs/read_write.c:849 #13 iter_file_splice_write (pipe=0xffff88810e897780, out=0xffff88810f06bf00, ppos=0xffffc90000c0be88, len=<optimized out>, flags=<optimized out>) at fs/splice.c:689 #14 do_splice_from (flags=0, len=<optimized out>, ppos=0xffffc90000c0be88, out=0xffff88810f06bf00, pipe=0xffff88810e897780) at fs/splice.c:767 #15 do_splice (in=in@entry=0xffff88810f06b400, off_in=off_in@entry=0x0 <fixed_percpu_data>, out=out@entry=0xffff88810f06bf00, off_out=off_out@entry=0x0 <fixed_percpu_data>, len=12288, flags=0) at fs/splice.c:1079 #16 __do_splice (flags=<optimized out>, len=<optimized out>, off_out=0x0 <fixed_percpu_data>, out=0xffff88810f06bf00, off_in=0x0 <fixed_percpu_data>, in=0xffff88810f06b400) at fs/splice.c:1144 #17 __do_sys_splice (fd_in=<optimized out>, off_in=0x0 <fixed_percpu_data>, fd_out=<optimized out>, off_out=0x0 <fixed_percpu_data>, len=<optimized out>, flags=<optimized out>) at fs/splice.c:1350 #18 do_syscall_x64 (nr=<optimized out>, regs=0xffffc90000c0bf58) at arch/x86/entry/common.c:50 #19 do_syscall_64 (regs=0xffffc90000c0bf58, nr=<optimized out>) at arch/x86/entry/common.c:80 #20 entry_SYSCALL_64 () at arch/x86/entry/entry_64.S:120
Conclusion
If this kind of work sounds interesting to you, consider applying for a job with the Ksplice team! Feel free to drop us a line at ksplice-support_ww@oracle.com.