Introduction
The Linux kernel uses the slab allocator to avoid memory fragmentation and to speedup allocation of frequently used objects. Since the slab allocator is one of the main memory allocation mechanisms (others being page/buddy allocator and the vmalloc allocator), memory corruption bugs often involve slab objects and in such cases it is helpful to know the internals of the slab allocator so that we can retrieve as much information as possible from the available data (usually a vmcore). Further, knowing the different debugging mechanisms that can be used for debugging the slab allocator is also beneficial as it helps in catching issues at runtime. This series of 2 articles describes the internals of the slab allocator and slab debugging mechanisms currently available in the kernel. In the first part we will look into details of how the slab allocator has been designed and how it works. In second part we will see how each of the debugging mechanisms, covered here, detect different types of memory errors. We will also see the advantages and limitations of each of these mechanisms so that one can decide which mechanism to use in which case.
In this article we will look into the internals of the slub allocator. This article is based on the v5.19 kernel but can it be used as a reference for other kernel versions as well.
Linux SLUB allocator
The Linux kernel is responsible for managing the available physical memory that it needs to satisfy memory allocation/de-allocation requests coming from different sources like device drivers, usermode processes, filesystems etc. It needs to ensure that it efficiently serves these requests under the specified constraints (if any) and to do so it relies on different types of memory allocators. Each allocator has its own interface and underlying implementation. The three main memory allocators used by the kernel are:
- Page allocator
- Slab allocator
- Vmalloc allocator
There are other allocators as well such as contiguous memory allocator (CMA) etc.
The Linux kernel groups available physical memory into pages (usually of size 4K) and these pages are allocated by the page allocator which serves as an interface for allocating physically contiguous memory in multiples of page size. For allocating large virtually contiguous blocks (that can be physically discontiguous) the vmalloc interface is used.
More commonly the allocation requests initiated by the kernel for its internal use are for smaller blocks (usually less than page size) and using the page allocator for such cases results in wastage and internal fragmentation of memory. In order to avoid these issues the slab allocator is used. The idea of the slab allocator is based on the idea of object cache. The slab allocator uses a pre-allocated cache of objects. This cache of objects is created by reserving some page frames (allocated via the page allocator), dividing these page frames into objects and maintaining some metadata about the objects. This metadata facilitates traversal through the list of objects and it also provides state information of these objects. Obviously this idea can be implemented in multiple ways where one implementation is beneficial in one environment and another implementation is beneficial in another environment. Hence, the Linux kernel has 3 flavors of slab allocators namely, SLAB, SLUB and SLOB allocators. The SLUB allocator is the default and most widely used slab allocator and this article will only cover the SLUB allocator. From this point onwards slab and slub have been used interchangeably.
Lets see the layout of a slab object and the layout of slab cache itself
slab object layout for the SLUB allocator
A slub object consists of one or more of the following parts:

Out of these only “Object content” is always present. This is the actual payload of a slab object. The presence/absence of other fields depends on SLUB debugging options that have been enabled.
Each slab cache is represented by a kmem_cache object which contains all the information needed for slab cache management. Free objects that will be allocated next are maintained in a list called “freelist” and the next free object is pointed to by “free pointer (FP)”. This free pointer is usually located at the beginning of the object. The location of FP within the object may change depending on the kernel version and/or debug options but it is always present somewhere within the area alloted for the object.
Let’s have a look at each of the fields mentioned in above diagram.
REDZONE left padding
This field is present whenever the RED zoning slub_debug (slub_debug = Z) option has been enabled. If enabled it exists at the beginning of the object.
kmem_cache→ red_left_pad indicates the size of this field. The actual object content lies at an offset of kmem_cache→ red_left_pad from the start of the object address. Also when this field is present for a slab cache the free pointer (pointer to the next free object) does not point to the start address of the object, rather than that it points to an offset of kmem_cache→ red_left_pad from the start of the object address. This allows clients of the SLUB allocator to work seamlessly with addresses obtained from the SLUB allocator.
Object payload
This field is always present and holds the actual payload of the object. If no debug options are in use then a slub object consists of this part only. The size of this portion is kmem_cache→ object_size.
REDZONE
Again this field is present only if slub_debug=Z option has been enabled. There are no explicit fields in kmem_cache to indicate the size of this field, usually it’s size is sizeof (void*) which happens if kmem_cache→ object_size is aligned to sizeof (void*). Otherwise some space will be left between the end of object content and start of the metadata area and that space is used as REDZONE.
Metadata
The presence and content of this field depends on the debugging option(s) as well. It can contain one or more amongst the following pieces of information:
Freepointer : Slub allocation tracker (struct track) : Kasan allocation meta
As the presence of this field depends on specific debug options, we will examine the contents of this field for different debugging options in subsequent article(s) about different SLUB debugging mechanisms.
Padding
Some additional padding bytes are left at the end of the object to make sure that the next object resides at an aligned address.
slab cache layout for the SLUB allocator
Each slab cache consists of one or more slabs. Each slab in turn consists of one or more pages and these pages contain fixed size objects. For slabs that consist of more than one page, compound pages are used. So a slab consists of one normal or one compound page. Both slabs and objects are organized into lists and there are multiple lists of both slabs and objects. The figure below shows a very top level view of a slab cache:
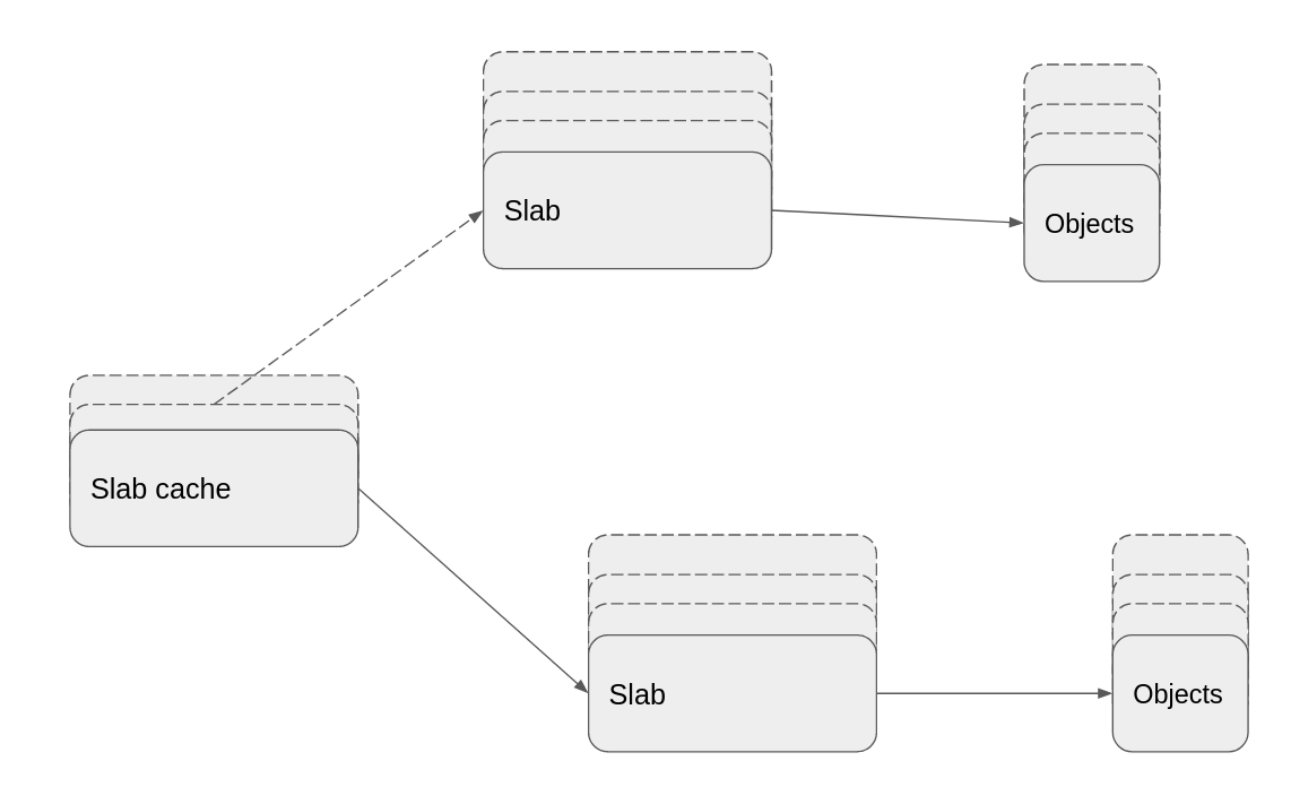
Each slab cache is represented by a kmem_cache object and each kmem_cache object has a per-CPU pointer (cpu_slab) to a kmem_cache_cpu object. A kmem_cache_cpu object holds per-CPU information for a slab cache. Each slab is represented by a slab object. In kernels older than 5.17 an anonymous union within the page object contains information about a slab (if that page is part of a slab). kmem_cache_node represents a memory node used by the slab allocator.
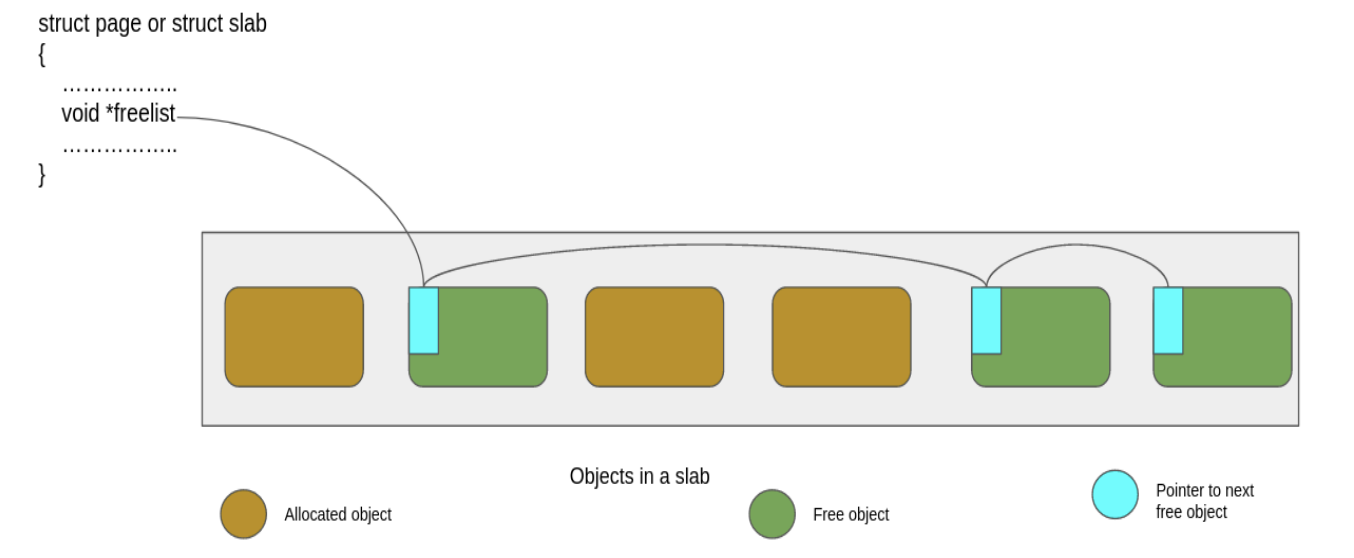
Objects within a slab are maintained in lists and the freelist member of the slab (or page) object points to the first free object of this list. The figure below shows the layout of a slab:
Each slab cache has a per-cpu active slab (kmem_cache.cpu_slabs.slab or kmem_cache.cpu_slabs.page), a per-cpu partial slab list (kmem_cache.cpu_slabs.partial, dependent on config options) and a per-node partial slab list kmem_cache.nodes[node_no].partial. slabs in the per-cpu partial slab list are connected via slab.next and slabs in the per-node partial slab lists are connected via slab.slab_list
Objects are always allocated from the per-cpu active slab. When all objects of an active slab have been allocated, the first object from one of the other slabs is returned as an allocated object and this slab becomes the active slab. Each slab cache also contains a per-cpu freelist (kmem_cache.cpu_slabs.freelist) which consists of objects on the active slab. So objects on the active slab can reside on one of the two lists at any point of time, a lockless freelist (kmem_cache_cpu.cpu_slabs.freelist) or a regular freelist (slab/page.freelist). On architectures that support switching two words using cmpxchg (x86_64, aarch64 etc.), allocating from and freeing into lockless freelist can be done without taking any locks and without disabling interrupt and preemption. Object allocation is always attempted from the lockless freelist first. Not all operations involving slab objects and slabs can be done in a lockless manner. For example manipulating a slab’s regular freelist (i.e slab.freelist), list of slabs etc. require locking.
The SLUB allocator uses the following locks:
- slab_mutex: This is a global mutex and is used to protect the list of slab caches (i.e. slab_caches), to synchronize metadata changes to slab cache structures and to synchronize memory hotplug callbacks
- kmem_cache_node→list_lock: This spinlock protects the partial and full slab list on each node. It also protects the partial slab counter. Since this lock is centralized (being per-node rather than per-cpu) it has significant overhead associated with it
- kmem_cache_cpu→lock: This is a spinlock which protects per-cpu kmem_cache_cpu (i.e. kmem_cache.cpu_slab) against preemption or irq on the same CPU
- slab_lock(slab): This is a wrapper around page lock, thus it is a bit spinlock that protects freelist, inuse, objects and frozen attributes of a slab. This is needed when we can’t use cmpxchg for these attributes either because the underlying architecture does not support it or because some slub debugging option has been enabled
- object_map_lock: This is a global spinlock that is used only in case of debugging
The figure below shows detailed layout of a slab cache:
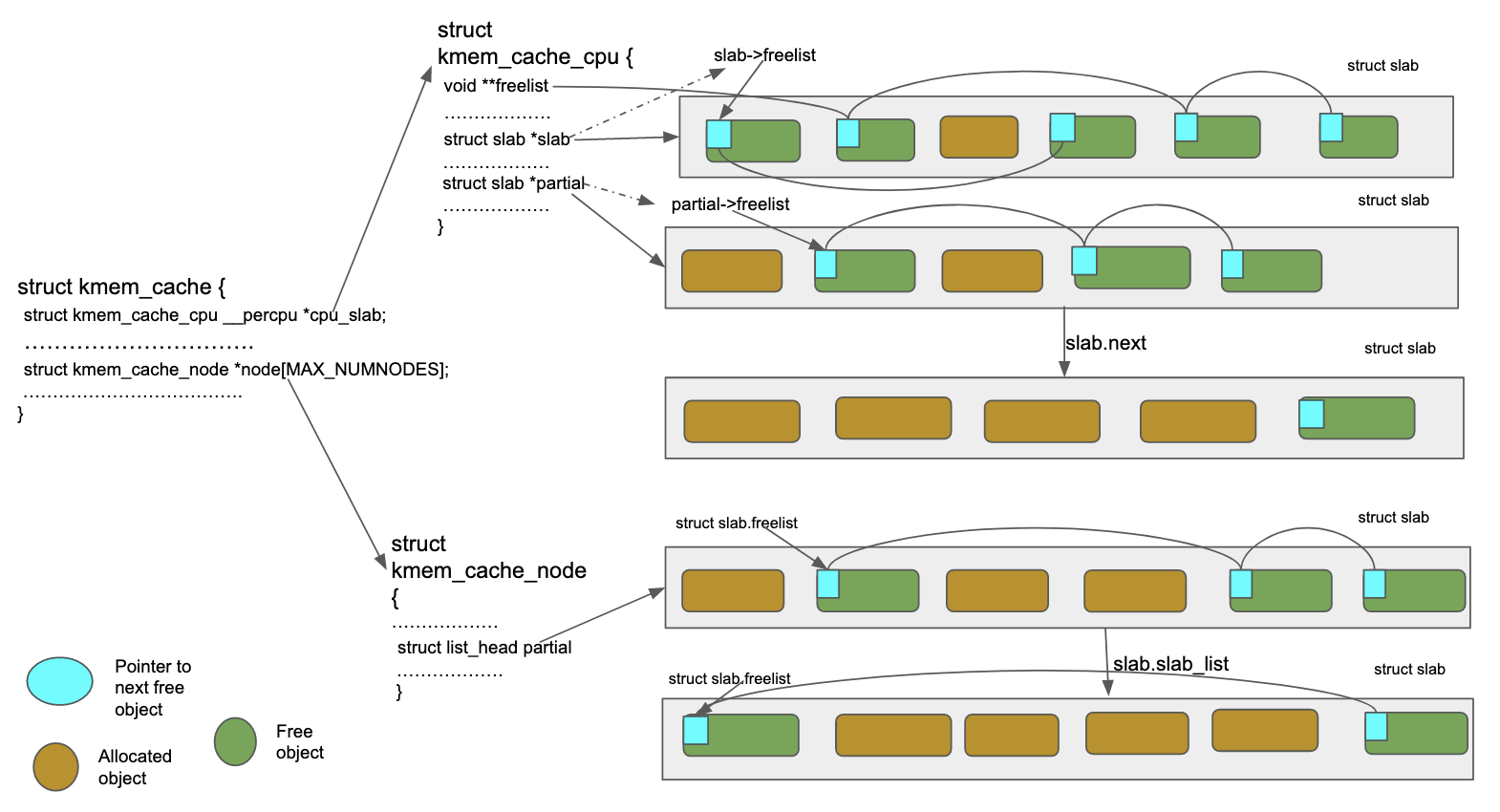
We can see from the above that both kmem_cache_cpu.freelist and kmem_cache_cpu.slab.freelist are pointing to objects on the active slab and these are two different lists albeit consisting of objects from the same slab (i.e the current active slab). We will understand more about these two lists once we look into object allocation mechanisms in the subsequent section.
A slab can be full, partially full or empty. A full slab has all of its objects allocated and an empty slab has all of its objects free. If needed empty slabs can be destroyed/reclaimed and underlying pages can be returned to the page allocator. A slab can be acting as a per-cpu active slab or it can be residing in a per-cpu partial slab list or it can be residing in a per-node partial slab list. Slabs in any of the partial lists are either partially or fully empty. A full slab does not exist on any of the above mentioned lists. There is no need to maintain a list of full slabs (except for slub debugging) because when an object from a full slab is freed we can get the address of the slab from the address of the object and put this slab (which is a partial slab now) into a proper slab list.
A slab can consist of one or more pages and this does not depend on the object size i.e. a slab can consist of multiple pages even if its objects are smaller than a page. The number of pages in a slab depends on kmem_cache.oo (i.e. the number of objects per slab)
For slabs consisting of multiple pages, a compound page (group of 2 or more physically contiguous pages) is allocated for each slab. In kernels older than 5.17 a page object has slab_cache and freelist members and in the case of compound pages managed by the slab allocator slab_cache and freelist members of only the head page are valid. slab_cache and freelist members of tail pages are not used to identify slab_cache or to identify the first free object on the slab. From 5.17 onwards slab_cache, freelist and other slab related members have been moved to a separate slab object.
Irrespective of whether a slab is represented by a slab or page object, slab.freelist or page.freelist points to the first free object on that slab and in the case of slabs consisting of a compound page, freelist of the head page points to the first free object on the slab and this first free object can be anywhere in the slab i.e it can be on the head page or it can be on one of the tail pages.
Allocating a slub object
So far we have looked into the layout of a slab cache and have seen different slab lists and object lists that exist in slab cache. Now we will see how objects are allocated from a slab cache. This will not only help understand the object allocation mechanism but will also help understand how slab states and different slab lists are maintained.
It must be remembered that allocation always happens from the active slab and both per-cpu freelist and active slab’s freelist (if not NULL) point to an object on the active slab. A slab cache is created with a fixed number of objects and later on it can be extended if needed.
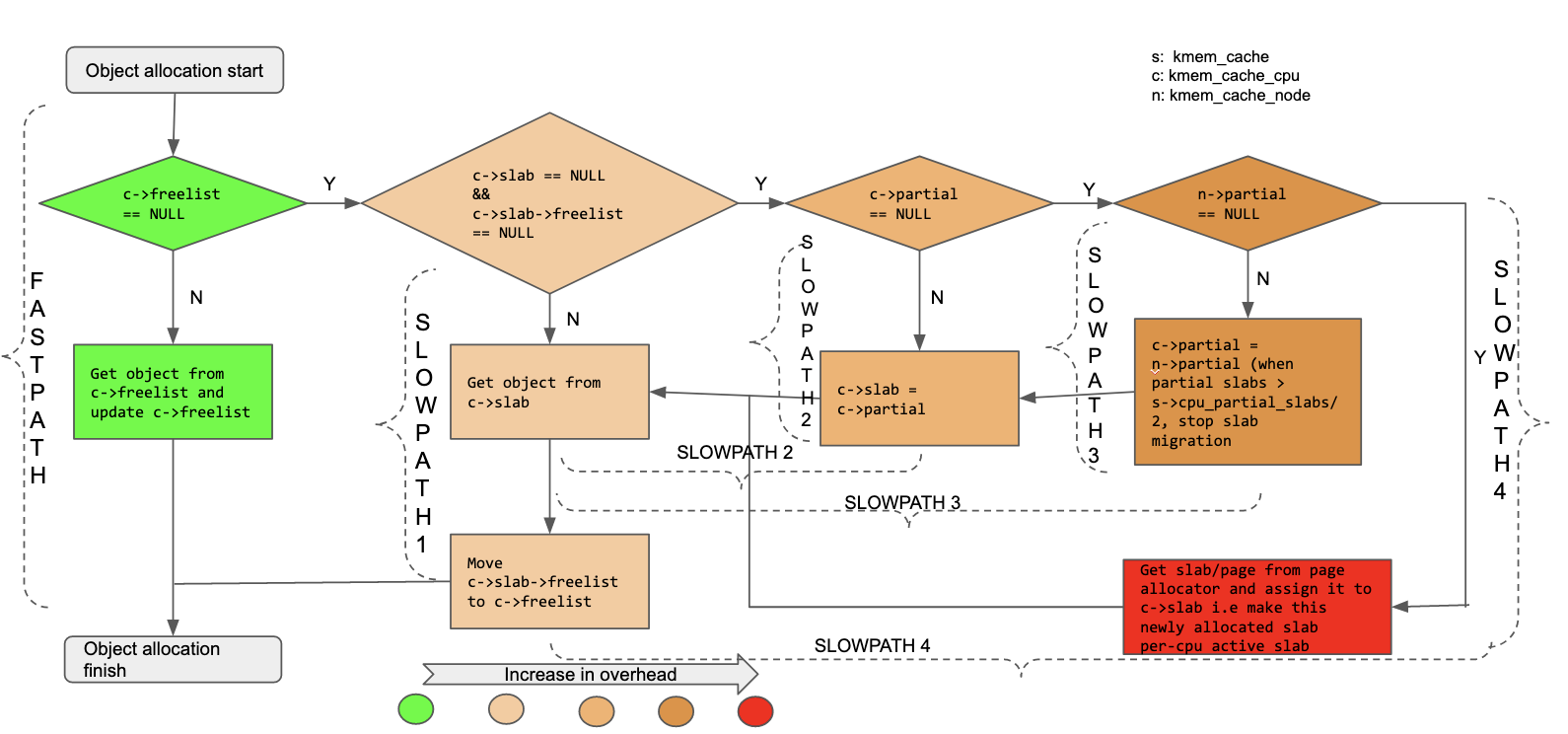
There are 2 allocation paths for objects: fastpath and slowpath.
Fastpath allocation happens when per-cpu lockless freelist (kmem_cache.cpu_slab->freelist) contains free objects. This is the simplest allocation path and it does not involve any locking or irq/preemption disabling. The object at the front of this freelist (i.e the one pointed to by kmem_cache.cpu_slab->freelist) is returned as an allocated object and next available object in the freelist becomes the head of the list. If allocation ends up consuming all objects in the lockless freelist, then this list becomes NULL and will get objects when allocation is next attempted. As mentioned earlier if the CPU does not support cmpxchg for 2 words or if slub debugging (slub_debug) is enabled, fastpath is not used. The fastpath allocation path has been marked as “FASTPATH” in the figure shown below
Allocation via all other paths are termed as slow path allocation but all of these paths have different overheads. These paths have been described below in order of increasing overhead.
If the per-cpu lockless freelist does not contain free objects but the freelist of active slab does contain free objects then the first object of the slab’s freelist is returned as an allocated object and the rest of the active slab’s freelist is transferred to that CPU’s lockless freelist. The active slab’s freelist becomes NULL. This path involves disabling preemption and acquiring kmem_cache_cpu.lock so it is slower than fastpath allocation but is still faster than other allocation paths that we will see later. This allocation path has been marked as “SLOWPATH 1” in the below figure. Explicit disabling of preemption is needed because for CONFIG_PREEMPT_RT kernels kmem_cache_cpu.lock is a per-cpu spinlock and leaves preemption enabled. In this article we are only covering kernels where CONFIG_PREEMPT_RT is disabled. As mentioned earlier a CPU’s active slab’s freelist and that CPU’s lockless freelist, both, point to an object on the active slab. How does this happen ? When a slab becomes a per-cpu active slab, right at that point of time, it’s freelist has been transferred to the per-cpu lockless freelist and slab’s freelist itself has become NULL. Now objects are allocated from this per-cpu lockless freelist and eventually they are freed as well. If object’s allocated from a CPU’s lockless freelist are freed by the same CPU then these objects go to the head of that CPU’s lockless freelist but if these objects are freed by other CPUs, then these objects go to the head of that slab’s freelist. This is how we can end up in a situation where a CPU’s lockless freelist does not have free objects but that CPU’s current active slab’s freelist has some objects.
In allocation paths discussed so far a CPU’s active slab had some free objects but it may happen that there are no more free objects in the active slab but the per-cpu partial slab list has slabs with free objects (assuming support of partial slab list is enabled). In this case the first slab in the per-cpu partial slab list becomes the active slab, its freelist is transferred to the CPU’s lockless freelist and objects get allocated from that freelist. This path also only involves disabling preemption and acquiring kmem_cache_cpu.lock but has additional overhead compared to the previous path. This additional overhead comes from the fact that in this case we need to make the first slab in per-cpu partial slab list, the current active slab and the second slab (if any) in the per-cpu partial slab list becomes head of this list. This allocation path has been marked as “SLOWPATH 2” in the figure below.
If per-cpu slabs (active and partial) do not have free objects, then allocation is attempted from slabs from the per-node partial slab list. How does the per-node partial slab list get its slabs. Slabs are never explicitly allocated for the per-node partial slab list. When a full slab becomes empty or partial, we try to put it into the per-cpu partial slab list first and if that is not possible (either because the per-cpu partial slab list is not supported or because it has the maximum allowed number of objects), the slab is put into the per-node partial slab list. This is how the per-node partial slab list gets its slabs.
Now when neither of the per CPU active or partial slabs have free objects, slub allocator tries to get slabs from the partial slab list of local node but if it can’t find slabs in that node’s partial slab list, then it tries to get partial slabs from the per-node partial slab list corresponding to other nodes. The nodes nearer to CPU are tried first. The traversal of a node’s partial slab list involves acquiring kmem_cache_node.list_lock and since this is a central lock, the involved overhead is much more than acquiring kmem_cache_cpu.lock needed in previously described cases. While looking for a slab, slub allocator iterates through the per-node partial slab list and for the first found slab, it notes the first free object and this object will be returned as an allocated object and the rest of this slab becomes the per-cpu active slab. This allocation path has been marked as “SLOWPATH 3” in below figure.
If the per-cpu partial slab list is supported then slub allocator continues even after getting a usable slab and making it the active slab. It moves slabs from the per-node partial slab list to the per-cpu partial slab list and continues doing so until all slabs in the per-node partial slab list have been moved or the limit of maximum number of slabs that can be kept in a per-cpu partial slab list has been reached. The maximum number of slabs that can exist in the per-cpu partial slab list depends on object size. slub allocator tries to keep a certain number of objects available in the per-cpu partial slab list. Based on this number of objects and assuming that each slab will be half full, slub allocator decides how many slabs can reside in the per-cpu partial slab list. The number of objects in the per-cpu partial slab list, depends on the object size and can be 6, 24, 52 or 120. For larger objects, the number of objects that the slub allocator tries to maintain in the per-cpu partial slab list is smaller. For example for objects of size >= PAGE_SIZE this number is 6 and for objects of size < 256 this number is 120.
Lastly if all of the slabs of a slab cache are full, a new slab gets allocated using page allocator and this newly allocated slab becomes the CPU’s current active slab. Amongst all the slow allocation paths this is the slowest one because it involves getting new pages from the buddy allocator. This allocation path has been marked as “SLOWPATH 4” in the figure below.
Freeing a slub object
Just like allocation, multiple scenarios can arise while freeing a slub object. One or more objects may be getting freed from:
- per-cpu active slab
- per-cpu partial slab list
- per-node partial slab list
- Full slab
Also if GENERIC KASAN is in use, freed objects don’t become usable straightaway (i.e they are not put in any of the freelists mentioned earlier) and are put into a quarantine list. Without quarantine the freed objects become usable straight away.
While freeing SLUB object(s) we may have to account for 2 main things. First is how to accommodate the freed object(s) in a proper freelist (per-cpu lockless freelist or slab’s regular freelist) and second is how to accommodate resultant changes in a slab’s state. For example a full slab will become partial after freeing one object or a partial slab will become empty after freeing it’s last in use object.
If we are freeing an object with GENERIC KASAN in place, then we just need to update the corresponding shadow bytes and put the object on the quarantine list. We don’t need to do anything to update the corresponding slab’s freelist and also the state of the corresponding slab does not change i.e a full slab does not become partial or a partial slab with only one allocated object does not become empty. These conditions will be accounted for when the objects in the quarantine list are taken care of.
If we are freeing an object with no GENERIC KASAN (i.e no quarantine) we can have the following scenarios. In all of the below scenarios, objects being freed are inserted into a corresponding freelist in such a way so that it becomes the first available object(s) on that freelist. We should also note that for per CPU active slabs we have 2 freelists, a lockless freelist pointed to by kmem_cache_cpu->freelist and a regular freelist pointed to by slab.freelist or page.freelist (of head page of active slab).
If the object being freed belongs to an active slab and the CPU freeing the object is the same as the one to which this active slab belongs, then the freed object goes into the lockless freelist i.e the freelist pointed to by kmem_cache_cpu→freelist. If the object being freed belongs to an active slab but the CPU freeing the object is not the one to which this active slab belongs to, then the freed object goes into the regular freelist of active slab. Both of these operations can be performed without needing any locking if cmpxchng for 2 words is supported and if we are not using slub debugging.
If the object does not belong to an active slab then it may belong to a full or partial slab. If the object belongs to a full slab, then after freeing the object the slab becomes a partial slab and is put either on the per-cpu partial slab list (if we are using per-cpu partial slab) or on the per-node partial slab list. If this newly partial slab ends up on a per-cpu partial slab list and no further slab list management is needed, then this entire operation only needs kmem_cache_cpu.lock. However while putting this partial slab on a per-cpu partial slab list if it is found that the per-cpu partial slab list is already full, then all slabs from the per-cpu partial slab list are unfrozen i.e they are moved to a per-node partial slab list and this new partial slab is put on the per-cpu partial slab list. Adding slabs into a per-node partial slab list requires kmem_cache_node.list_lock and hence there is this additional overhead.
If the object belongs to a partial slab we have 2 scenarios to consider. If the slab remains partial even after freeing the object then nothing else is needed and the slab remains on the list it was already on. This applies to both the per-cpu partial slab list or the per-node partial slab list. But if the partial slab becomes an empty slab after freeing up the object, it will be left in its current list if the number of partial slabs for the concerned node is within the limits (i.e < slab cache’s min_partial). This applies to both slabs belonging to a per-cpu partial slab list and slabs belonging to a per-node partial slab list. If the number of partial slabs are outside the limit (i.e >= slab cache’s min partial) then the newly available empty slab is freed and is removed from the corresponding partial slab list.
All of the above mentioned freeing paths have been captured in the figure below. Operations involving per-node partial slab list manipulation need kmem_cache_node.list_lock and have been marked in red. Operations involving per-cpu partial slab list manipulation need kmem_cache_cpu.lock and have been marked in orange. Both red and orange blocks constitute the SLOWPATH of free. As described in the allocation part, the overhead of kmem_cache_node.list_lock is much more than that of kmem_cache_cpu.lock.
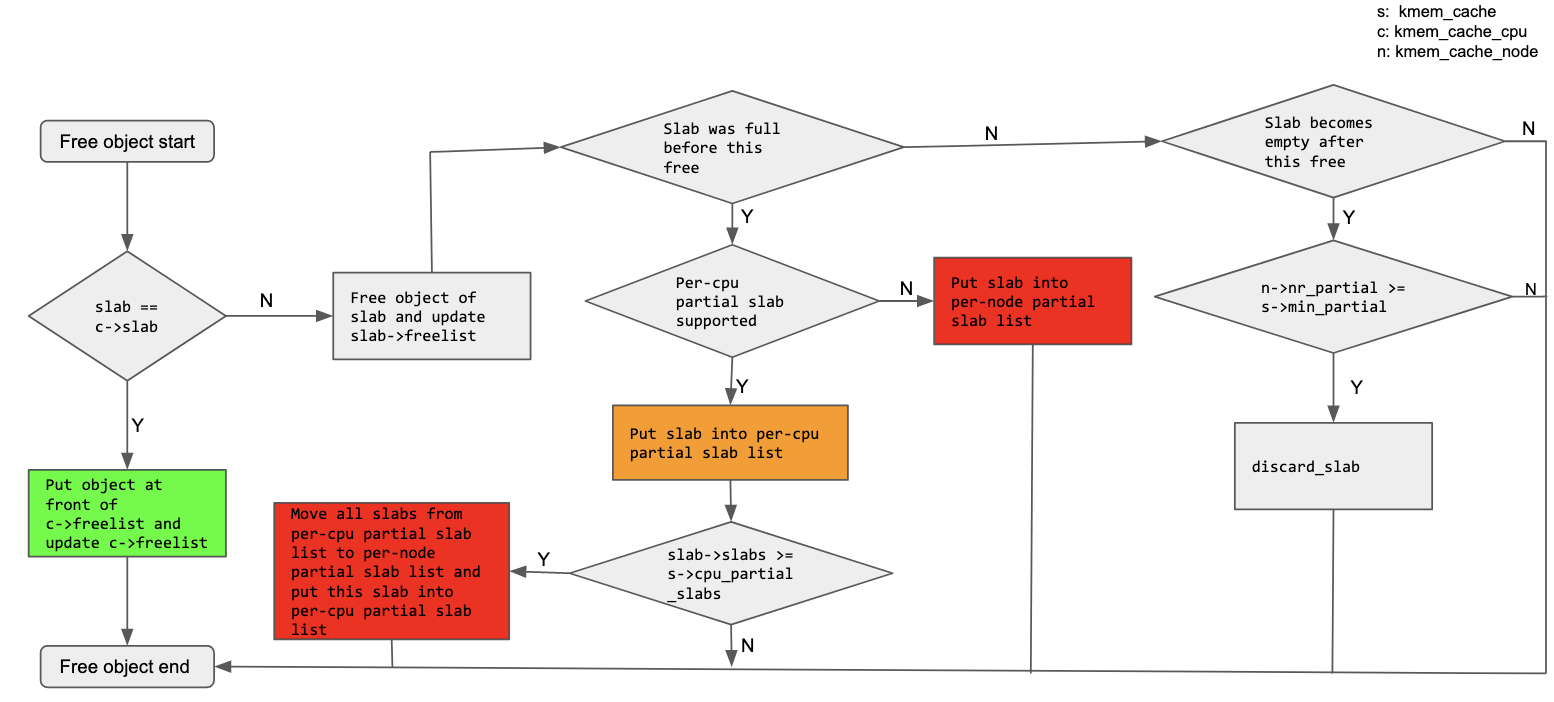
So far we have covered the cases involving freeing of a single object. When freeing multiple elements the behaviour is identical when it comes to managing full, partial or empty slabs. The only difference is what goes to the front of the destination freelist. When freeing a single object, this object is moved to the front of destination freelist but when freeing multiple objects, a detached freelist is created and this list gets spliced to the front of the destination freelist.
Conclusion
This article described the organization of SLUB allocator and how allocation/freeing mechanisms work. The way SLUB objects and associated metadata (if any) is organized and managed, memory corruption involving objects and/or metadata can lead to all sorts of weird outcomes which mostly result in system crashs. For example as the objects within a slab are lying adjacent to each other an out-of-bound (OOB) access in one object can corrupt the content of an allocated object and this can lead to various issues arising due to the wrong state of the impacted object. An OOB access can also corrupt the freepointer (FP) residing at the beginning of an object, this in turn will corrupt the freelist and cause a crash when the object allocation path would try to dereference the object pointed to by this corrupted freelist. A use-after-free (UAF) error can also lead to similar issues where a dangling pointer ends up corrupting an allocated object or corrupting the freepointer of a free object. Also as the freed objects are put at the head of a freelist, freeing the same object twice or freeing an invalid object (whose address is not a slab address or whose address is not the start address of an object) can cause freelist corruption.
SLUB allocator, on its own, will not be able to detect and report such errors and this brings into fold different debugging mechanisms (slub_debug, KASAN and KFENCE) that can be used with SLUB allocator. These debugging mechanisms will be described in next article(s).