Introduction
irqbalance is a command line tool that distributes load, generated by different interrupt sources, across CPUs in order to achieve better system performance. It can be run in a oneshot mode where it distributes interrupts once and then stops. However by default it runs as a daemon and periodically performs interrupt load balancing at intervals of a fixed time period (default 10 sec, but configurable as well). At a very high level irqbalance periodically gathers interrupt and softirq related load by reading relevant entries in /proc/interrupts and /proc/stat and changes the affinity of one or more interrupts so that this load is more evenly distributed between NUMA nodes, processor packages and/or CPUs.
In this article we will look into the design and operation details of irqbalance. We will see how it collects, manages and utlizes relevant data to take decisions related to interrupt(irq) load balancing. This article does not cover the description of irqbalance options or the config file because this information can be easily obtained from the irqbalance man page (see References). Throughout this article the terms interrupt and irq have been used interchangeably.
Data structures
irqbalance collects and stores needed data in objects of different types. This section describes the main data structures used by irqbalance. This is not a complete list of each and every object type used by irqbalance but it covers the ones that will be referenced in later sections. Getting an understanding of these objects will also help anyone who wants to go through the irqbalance code for debugging or for deeper understanding of the code. The following lists the main objects used by irqbalance:
- struct topo_obj: represents an object in the system topology tree created by
irqbalance - struct irq_info: represents each irq managed by
irqbalance - Object lists: glib lists of objects of different types
topo_obj
irqbalance is used on a diverse range of systems. These systems can range from small scale embedded devices consisting of just a few CPUs to large scale enterprise systems consisting of hundreds of CPUs and multiple physical sockets and/or NUMA nodes. irqbalance needs to work satisfactorily on all of these systems. For example on a single socket systems with multiple CPUs, irqbalance just needs to ensure that no CPU gets overloaded with irq load but on a multi socket and/or multi node system irqbalance also needs to ensure that irq load gets evenly distributed between the sockets/nodes.
As a result irqbalance needs to have a clear idea of the underlying system components between which irq load distribution is needed. In order to do that, irqbalance creates a system topology tree. Each level of this tree represents different components. For example NUMA nodes are at the top and individual CPUs are at the bottom level. Objects at the top level have no parents and objects at each level are parents of one or more objects one level below. Each object in this topology tree is of type “struct topo_obj”:
struct topo_obj {
uint64_t load;
uint64_t last_load;
uint64_t irq_count;
enum obj_type_e obj_type;
int number;
int powersave_mode;
cpumask_t mask;
GList *interrupts;
struct topo_obj *parent;
GList *children;
GList *numa_nodes;
GList **obj_type_list;
};
load and last_load represent current and last load respectively. The difference between these two gives the load between consecutive scans (more about this later). irq_count is the sum of counts of contained irqs. obj_type is the type of this object. A topo_obj can be of any of the following enum types:
enum obj_type_e {
OBJ_TYPE_CPU, ← CPU
OBJ_TYPE_CACHE, ← CPUs sharing cache(usually threads of the same core)
OBJ_TYPE_PACKAGE, ← A physical package/socket
OBJ_TYPE_NODE ← NUMA node
};
number is a unique identifier of topo_obj. For some object types(CACHE, PACKAGE) it is allocated by irqbalance and for other object types (NODE, CPU) this is obtained by parsing the name of sysfs directory of that node or cpu. mask is bit mask of contained CPUs , interrupts is a list of interrupts assigned to this object. For objects of type OBJ_TYPE_CPU interrupts is a list of interrupts assigned to this CPU and mask is bit mask of this cpu. For upper level objects these members are just a union of corresponding child values. children is a list of child topo_obj objects, parent is the parent topo_obj. numa_nodes specifies to which NUMA node a cache_domain or processor package belongs. Usually a processor package or cache domain belong to one node only. irqbalance maintains a global list for topo_obj of each type and topo_obj.obj_type_list points to the corresponding global list.
Topology objects at each layer, have topology objects one level above as their parent and topology objects one level below as their children.
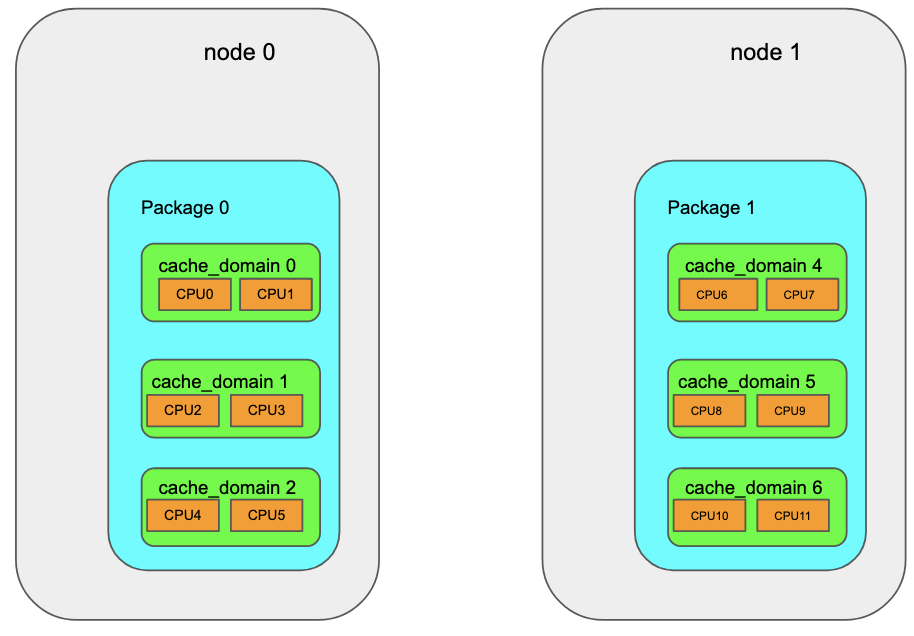
Typically a OBJ_TYPE_NODE type topo_obj has one or more children of type OBJ_TYPE_PACKAGE, which in turn have one or more children of type OBJ_TYPE_CACHE, which in turn have one or more children of type OBJ_TYPE_CPU as shown in the figure below:
irq_info
irqbalance maintains all information about each managed irq in an object of type “struct irq_info”.
struct irq_info {
int irq;
int class;
int type;
int level;
int flags;
struct topo_obj *numa_node;
cpumask_t cpumask;
uint64_t irq_count;
uint64_t last_irq_count;
uint64_t load;
int moved;
int existing;
struct topo_obj *assigned_obj;
char *name;
};
irq is the identification number of the interrupt. class specifies the class of irq (ethernet, storage etc) and type specifies whether the irq source is a legacy or MSI PCI device. level specifies the level of load balancing for this irq. We need to map high frequency irqs to specific CPU but low frequency irqs can be mapped to a group of CPUs under a package or cache_domain. level specifies to what depth we need to go to find a proper destination for a given irq. flags is just used to specify if an irq has been banned (IRQ_FLAG_BANNED). irq_count indicates the total number of occurrence till now and last_irq_count indicates the total number of occurrence at last scan time. irq_count – last_irq_count gives the number of occurrence in this scan window (default scan duration 10 sec). load is the weighted average load (see load calculation section below)of this irq. assigned_obj points to the topo_obj to which this irq is mapped at any moment and that determines which CPU(s) this irq gets mapped to, till next scan time.
Object lists
irqbalance maintains lists of different types of objects. Each of these lists are of type GList (provided by glib). Some of the most frequently used lists are as follows:
- GList *numa_nodes: List of NUMA nodes
- GList *packages: List of all packages
- GList *cache_domains: List of all cache domains.
- GList *cpus: List of all CPUs
- GList *rebalance_irq_list: List of irqs marked for migration in the current scan window
- GList *cl_banned_irqs: List of banned irqs (the ones which are not considered for load balancing)
irqbalance operation
irqbalance performs 2 main tasks
- Build and maintain the system topology tree
- Perform irq load balancing
Build and maintain system topology tree
As mentioned earlier, in order to achieve the desired result, irqbalance needs to be aware of the CPU hierarchy. So it creates a system topology tree consisting of struct topo_obj type objects. irqbalance creates this topology tree at start time. After each scan irqbalance checks if some CPU/IRQ has been hotplugged in/out and if it detects any such change it rebuilds the entire topology tree. Irrespective of when or how many times the topology tree is created, the involved steps are always the same.
There are 2 parts of this task:
- Building and maintaining the processor tree
- Building and maintaining the IRQ database
Build and maintain the processor tree
At first a dummy numa node is created (for both NUMA and non-NUMA systems), the corresponding topo_obj has topo_obj.number set to NUMA_NO_NODE (i.e -1). This allows irqbalance to work even on those systems where NUMA is not supported.
For systems with NUMA support (a system with one node can also have NUMA support as far as irqbalance is concerned), irqbalance reads /sys/devices/system/node and creates a topo_obj of OBJ_TYPE_NODE for each of the found nodes. The topo_obj.number is the same as the NUMA node number, topo_obj.mask is based on the corresponding node’s cpumap (i.e. /sys/devices/system/node/nodeX/cpumap).
After creating objects corresponding to NUMA nodes, the rest of the hierarchy tree is built from down to top. Before proceeding further irqbalance checks for CPUs that can’t be considered in load balancing decision making. By default isolated (/sys/devices/system/cpu/isolated) and nohz_full (/sys/devices/system/cpu/nohz_full) processors are not considered for irq load balancing but this behavior can be overridden by setting the IRQBALANCE_BANNED_CPUS environment variable.
After setting the bit mask of banned CPUs (i.e banned_cpus), irqbalance reads CPU information for each CPU from the corresponding /sys/devices/system/cpu/cpuX (X is number of a CPU) file.
The offline CPUs are skipped and for each online CPU, it allocates and initializes a topo_obj of type OBJ_TYPE_CPU. topo_obj.mask is set to the bitmask of this CPU and topo_obj.number is set to the number of this CPU. For banned CPUs the allocated topo_obj is freed but for unbanned CPUs we proceed further and add this CPU to cache_domain and package.
/sys/device/system/cpu/cpuX/topology/physical_package_id provides the processor package number and bitmask of other CPUs on the same package can be read from /sys/devices/system/cpu/cpuX/topology/core_siblings.
cache_domain decides the cache level at which irq load balancing should be performed. This value is configurable (via command line option -c) but defaults to L2 cache. Processors from the same package, that share the cache with this CPU, are found in /sys/devices/system/cpu/cpuX/cache/indexM/shared_cpu_map (here X is the CPU number and M is the maximum cache level)
After getting its package and cache_domain related information, the CPU is recursively added to corresponding topology objects. topo_obj objects for cache_domain and/or packages are created as needed. topo_obj.parent and topo_obj.children are assigned as per retrieved information. Each of the newly allocated topo_obj gets added to the corresponding global list.
Build and maintain the irq database
At first irqbalance obtains the list of currently present interrupts by parsing /proc/interrupts. Each line (except the header) of /proc/interrupts contains each interrupt’s ID (number or string), number of interrupt’s occurrence on each CPU and additional information about the interrupt like responsible driver, type(edge/level triggered) etc. Interrupts with non-numeric IDs (NMI, LOC, TLB etc.) are internal interrupts and are ignored by irqbalance. For each managed irq, an irq_info object (described earlier) is set up. Devices responsible for an irq are identified to determine irq type (irq_info.type). This is done by parsing /sys/bus/pci/devices/DEVICE_ID directories. If the device directory contains an msi_irqs directory, the device can be matched to one or more irq_info objects based on the irq numbers in the mentioned directory. PCI devices since version 2.2 are MSI capable and since PCI version 3.0, MSI-X allows more irq vectors per device. For such interrupts, irq_info.type is either IRQ_TYPE_MSI or IRQ_TYPE_MSIX. For devices without MSI support, the irq file in the devices directory provides the irq number and irq_info.type is IRQ_TYPE_LEGACY.
Once an irq_info has been initialized, irqbalance checks if some applicable user policy has been defined for this irq and modifies some fields of irq_info accordingly. Eventually this irq_info gets added to the global irq database (GList *interrupts_db)
Load balancing
irqbalance periodically checks irq load on a given system. The default frequency for this scan is 10 sec but it can be changed by -t or –interval= command line options. The load calculation and resultant decision making is described below. It must be remembered that while changing the mapping of an irq, irqbalance always respects the node preference specified by the driver and does not move irq away from that node. If the driver has not specified any preferred node then irq can be mapped to any node.
Load calculation
In order to decide which (if any) irqs to move, irqbalance needs to determine the load at each topology object and make its decisions accordingly. It parses /proc/interrupts and /proc/stat, at the end of each scan window and calculates irq load for that scan window.
Parsing /proc/stat is needed to get load statistics for processors. For each unbanned CPU, the time (in nanosecs) spent in handling irqs and softirqs is obtained and that CPU’s topo_obj.load and topo_obj.last_load are populated. topo_obj.load is the load at the end of this scan window and topo_obj.last_load is the load at the end of the last scan window, so their difference becomes the load during the current window. The calculated load at each CPU is propagated all the way to the top of the topology tree. This means the load at CPUs is added to get the load at parent cache_domain, load at cache_domain is added to get the load at parent processor package and the load at packages is added to get the load at NUMA node level.
Similarly the local irq count at each object is calculated by parsing /proc/interrupts and adding irq count at child level to get irq count at parent level.
After this the load of the corresponding CPU branch is computed. This means that the load at each node is evenly divided between its children processor packages, the load at each processor package is evenly divided between its children cache_domains and the load at each cache_domain is evenly divided between its children CPUs. Once the load at each CPU has been obtained, a fair share of that load goes to each irq on that CPU and irq_info.load is accordingly updated. This is how irqbalance calculates the load due to each irq and the load at each topology object.
Once the load has been calculated irqbalance needs to uniformly distribute it.
Load balancing at startup
When irqbalance (re)starts, the load due to each IRQ and at each topo_obj is considered 0. At this point an irqbalance subroutine, force_rebalance_irq, is invoked for each managed interrupt. At this point in time irq_info.assigned_obj is NULL so each of the managed irqs ends up in rebalance_irq_list (list of irqs marked for movement). As the load at each topological entity (node, package, cache_domain, CPU) is 0, irqbalance ends up distributing all managed interrupts in a round robin fashion (as much as possible) from top to the bottom of the topology tree. This means at first irqs are distributed between nodes in a round robin way, then irqs given to each node are distributed between child packages of respective nodes, then irqs given to packages are distributed between child cache domains and finally irqs belonging to a cache domain are distributed between child CPUs. As mentioned earlier while trying to find the destination node for an IRQ, only the preferred node (specified by driver) is considered and only those IRQs that don’t have any preferred node can be put on any node.
Periodic load balancing
Once irqbalance has started and distributed IRQs in a round robin way, from that point onward at the end of each scan window, irqbalance takes the difference of irq and softirq load at the beginning and end of that scan window. This difference is the load for this scan window and load balancing is done based on this. The involved steps are as follows:
- Read /proc/interrupts and /proc/stat and calculate load at each object.
- Find overloaded objects and move one or more of their irq(s) to rebalance_irq_list
- For each irq in rebalance_irq_list, find the destination in a top down manner and set irq_info.assigned_obj to topo_obj corresponding to the destination
- Assign each IRQ to CPUs that are online and specified by corresponding irq_info.assigned_obj.mask
While finding overloaded objects, at first overloaded CPUs are found. In order to find overloaded CPUs, the CPU with minimal load is located and also the total and average load across all CPUs are calculated. If the current load at any CPU is higher than the minimal load, interrupts assigned to it are sorted according to their class and workload. Some of these irqs are then moved to rebalance_irq_list (i.e marked for migration). Not all irqs can be marked for migration from one CPU to another. If the irq is banned from balancing or if its load is very low (<=1) or if it is the only irq being served by this CPU, then the irq is not selected for migration. If the irq is eligible for migration, it is checked if migrating this irq will swap the imbalance between this CPU and the CPU with minimal load and only if migration will not swap imbalance, the irq is selected for migration. The load at the CPU with the minimal load, so far, is adjusted to account for the load of irq selected for migration.
Overloaded package, cache_domain and NUMA nodes are found in a similar way and selected irqs are moved to rebalance_irq_list.
Once all eligible irqs have been moved to rebalance_irq_list, rebalance_irq_list is sorted according to class and load of each irq. Then for each irq in this sorted list a destination node is found and irq_info.assigned_obj points to topo_obj of that node. Obviously while selecting the destination node, the node with minimal load, amongst all eligible nodes is selected. If an irq has a single preferred node, it will not be moved away from that node. Once a node has been selected for all irqs in rebalance_irq_list, the irqs at each node are distributed from top to bottom of the topology tree (finishing when irq_info.level for the chosen irq has been reached). At each stage objects with the least load or with less irqs assigned (in case of the same load), are selected and irq_info.assigned_obj is changed to point to the corresponding topo_obj. Once final placement of an irq has been determined its irq_info.assigned_obj points to destination topo_obj.
So far the decision has not yet been conveyed to the kernel. Finally for each of the above irqs, /proc/irq/IRQ_NUM/smp_affinity is set according to bitmask (irq_info.assigned_obj.mask & cpu_online_mask) and this action causes actual migration of interrupts.
The same steps are repeated at the end of each scan window.
Conclusion
This article described the internals of the irqbalance daemon. The information provided here can be used to debug and better understand load balance decisions taken by irqbalance.