Welcome to part 2 of this 3-part series on Kernel and Userspace Tracing Using BCC. Part 2 of this series will provide info on getting your Oracle Linux 7 machine’s environment setup for running BCC scripts, a mini introduction to BCC programs / scripts, and then finally two simple BCC script examples broken down step-by-step. If you would like more background information on tracing, BPF, and BCC, see part 1 of this series.
Creating Custom BCC Programs
In this section, we’ll go through some BCC program development tips, simple examples of BPF programs, and highlight the key components of these programs. This guide is not meant to replace the BCC Python developer guide, but rather compliment it. You will definitely want to check out the BCC Python developer guide afterwards, as the examples here won’t represent everything you can do with BCC.
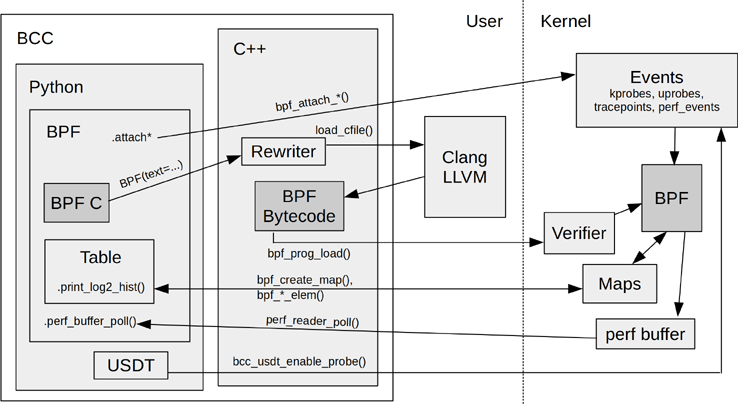
First, before we jump into creating new BCC programs, we’ll need to make sure our environment is set up and ready to go!
Setting up BCC Development on Oracle Linux 7
To get set up with BCC on your Oracle Linux machine, you’ll want to make sure you have at least Linux 4.1. However, it’s strongly recommended you have at least Linux 4.9, as attaching a perf event requires it, along with BPF_PROG_TYPE_PERF_EVENT support. The examples we’ll go through on this page will not work if your Linux version is not at least 4.9.
Luckily, getting set up with BCC is straightforward!
- Ensure the following configurations are enabled in your current running kernel configuration.
In /boot/config-$(uname -r):CONFIG_BPF=y CONFIG_BPF_SYSCALL=y # [optional, for tc filters] CONFIG_NET_CLS_BPF=m # [optional, for tc actions] CONFIG_NET_ACT_BPF=m CONFIG_BPF_JIT=y # [for Linux kernel versions 4.1-4.6] CONFIG_HAVE_BPF_JIT=y # [for Linux kernel versions 4.7+] CONFIG_HAVE_EBPF_JIT=y CONFIG_BPF_EVENTS=y
Note: These configurations are typically enabled by default, but doublecheck to make sure they are.
- Install / update basic dependencies from Oracle repos.
$ yum install bison cmake ethtool flex git iperf3 \ libstdc++-static python-netaddr gcc gcc-c++ make \ zlib-devel elfutils-libelf-devel ncurses-devel bcc* \ libbpf-devel kernel-uek-$(uname -r) \ kernel-uek-debug-devel-$(uname -r) \ kernel-uek-devel-$(uname -r)
Once these two steps are complete, you’re ready to go to start making your own custom BCC programs!
Note 1: To see some of the new pre-made tools that came with the installation, go to /usr/share/bcc/tools.
Note 2: If you’ve, by chance, happened to have previously downloaded and installed the upstream version of BCC (e.g. from GitHub), you will need to change the path of the target LLVM package to the one Oracle’s repo provides (llvm-private) instead of the one provided by Redhat’s software libraries.
In the meantime, if you receive an error like the one down below, make sure to run scl enable rh-dotnet20 bash command to enable the rh-dotnet20 software collection before running anything BCC related.
Traceback (most recent call last):
File "./trace.py", line 14, in <module>
from bcc import BPF, USDT, StrcmpRewrite
File "/usr/lib/python2.7/site-packages/bcc/__init__.py", line 27, in <module>
from .libbcc import lib, bcc_symbol, bcc_symbol_option, bcc_stacktrace_build_id, _SYM_CB_TYPE
File "/usr/lib/python2.7/site-packages/bcc/libbcc.py", line 17, in <module>
lib = ct.CDLL("libbcc.so.0", use_errno=True)
File "/usr/lib64/python2.7/ctypes/__init__.py", line 360, in __init__
self._handle = _dlopen(self._name, mode)
OSError: libclangFrontend.so: cannot open shared object file: No such file or directory
For other Linux distributions, see BCC’s INSTALL.md page in the BCC GitHub repo (link provided in References section).
BCC Tool Development Tips
Here are six important aspects about BCC tool development that you should be aware of when writing your own custom BCC programs:
- BPF C (embedded C) is restricted: no loops or kernel function calls. You may only use the bpf_* kernel helper functions and some compiler builtins.
You can, however, unroll loops if you have definitive bounds for your loops. For example, strcmp won’t work but you can work around that if you know the length of the string you’re comparing others with.The following is an example of an unrolled loop workaround that does a string comparison:
#define MY_STR_LEN 10 static inline bool equal_to_mystr(char *str) { char comparand[MY_STR_LEN]; bpf_probe_read(&comparand, sizeof(comparand), str); char mystr[] = "my string!"; for (int i = 0; i < MY_STR_LEN; ++i) if (comparand[i] != mystr[i]) return false; return true; }
Similarly, you can’t use memcpy to write from and to memory areas. Instead, you have to use BCC’s builtin function __builtin_memcpy(&dest, str, sizeof(dest)). - All memory must be read through bpf_probe_read(), which does necessary security checks.
If you want to dereference a->b->c->d, you can try to do it, as BCC has a rewriter that may translate it to the necessary bpf_probe_read(). However, explicit calls of bpf_probe_read() are always a safe bet and recommended.Memory can only be read to the BPF stack of BPF maps. The stack is limited in size, so use BPF maps for storing large objects and/or preserve data over numerous events.
- There are three main ways to get data from kernel to userspace (in a BPF C program).
BPF_PERF_OUTPUT(…) and output_name.perf_submit(…):- Send per-event details to userspace via. a custom data structure you define
BPF_HISTOGRAM(…) or other BPF maps:
- Maps are a key,value hash from which more advanced data structures are built
- Typically used for summary statistics (e.g. histograms)
- Efficient when periodically read from userspace (instead of using BPF_PERF_OUTPUT)
bpf_trace_printk(…):
- For debugging only, as all bpf_trace_printk() calls and some tracers (e.g. ftrace) write to the same common trace_pipe
- Use static tracing (kernel tracepoints, USDT tracepoints) instead of dynamic tracing (kprobes, uprobes) whenever possible.
Recall that dynamic tracing has an unstable API (because we hook onto the name of the function, which can change over software versions), so your tools will break if the code it’s tracing changes. - Keep in mind the event frequency and overhead work associated with each event (see next section).
A tracepoint / probe placed at a very frequent event with lots of actions to perform for each event will cause high CPU overhead and lock-up your system. - Do as much (and as little) work as possible in the BPF C program instead of in userspace.
It’s much faster to do the work for each event in the kernel compared to handling most of the work in userspace. Depending on the size of your program, this effect may be negligible.
Event Frequency and Overhead
It’s important to keep in mind that we’re not getting this observability without a cost. Each enabled probe/tracepoint will incur some amount of work to be done for every time it’s hit, both in kernel and userspace, creating CPU overhead. The three main factors that determine the CPU overhead for a tracing program are:
- Frequency of the targeted event
- Processing workload for each event
- Number of CPUs on the system
An application will suffer this overhead on a per-CPU basis using the relationship below:
overhead = (frequency * workload) / numCPUs
In other words, tracing 1 million events per second on a single CPU may bring the system to a crawl, whereas a 128-CPU system may barely be affected. The number of CPUs and the overhead of the work being performed can vary by a single order of magnitude. However, event frequency can vary by several orders of magnitude, making it the biggest wildcard when trying to estimate overhead.
You can find more detailed information on event frequency, CPU overhead, other tips and tricks, and common problems in Chapter 18: Tips, Tricks, and Common Problems from the BPF book by Brendan Gregg.
BCC Script Examples
Now for the fun; recall that a BPF script contains two key elements: BPF C code (aka embedded C) and the BPF userspace code (typically in Python or C++). The BPF C code can be contained in the Python script itself (as a large multi-lined string) or defined in its own C file and read in.
Example 1: sys_sync Hello World
For our first example, we’ll attach to the kprobe for the sys_sync() syscall. Recall that kprobes are part of dynamic tracing, so we just need to enable tracing for that probe by hooking onto it. To get output into userspace, we’ll first look at doing that with bpf_trace_printk().
Using bpf_trace_printk():
First, we’ll try printing “Hello World” every time the user executes sync on the command line. Recall that the bpf_trace_printk() function should only be used for debugging purposes, but for a first example it provides a good introduction.
Examine the following BPF Python program:
#!/usr/bin/python
from bcc import BPF
# Define BPF program
bpf_txt = """
int hello_world_printk(void *ctx) {
bpf_trace_printk("Hello World!\\n");
return 0;
}
"""
# Load BPF program
bpf_ctx = BPF(text=bpf_txt)
bpf_ctx.attach_kprobe(event=bpf_ctx.get_syscall_fnname("sync"),
fn_name="hello_world_printk")
# Print header
print("%s" % "MESSAGE")
# Format output
while 1:
try:
bpf_ctx.trace_print(fmt="{5}")
except KeyboardInterrupt:
print()
exit()
As you can see, our first BPF program includes a small BPF C program (as a python string) with the function hello_world_printk(void *ctx), and then a python script to load in the BPF program. We then “hook” / enable the kprobe for sys_sync and handle the output we get from the BPF printk. Let’s break this down piece by piece:
bpf_txt: The BPF C program, contains one function hello_world_printk.
- Typically, functions defined in the BPF C program are set to correspond to an event (e.g. kprobe, uprobe, kernel tracepoint, USDT tracepoint) and execute their code every time that event is hit
- In our case, every time we hit the kprobe event sys_sync (by executing the sync command), we print “Hello World!” to BPF printk’s common trace_pipe
- Every BPF C function must return an int (typically just 0). For some reason, this is a necessary formality (if you want to know why, see this issue)
- All C functions declared in the BPF program are expected to be executed on a probe/tracepoint, hence they all need to take a pt_regs *ctx as the first argument (or void *ctx if you don’t intend to use it)
- If you need to define some helper function (i.e. the equal_to_mystr() helper function above) that is not set to be executed by an event, they need to be defined as static inline in order to be used and inlined by the compiler
void *ctx: ctx has arguments (as struct pt_regs *ctx), but since we’re not using them for this example, we can just cast it to void *
bpf_trace_printk(): A simple kernel facility for printf() to the common trace_pipe (/sys/kernel/debug/tracing/trace_pipe).
- Limitations: 3 arguments max: 1 string (%s), and two non-string variables
- trace_pipe is globally shared (concurrent programs also using bpf_trace_printk() will clash)
- A better output interface is BPF_PERF_OUTPUT() (next example)
- bpf_trace_printk
bpf_ctx = BPF(text=bpf_txt): This essentially loads the BPF C program and runs it through a compiler, verifier, etc.. and returns a BPF object that we use to enable events.
attach_kprobe(event=’…’, fn_name=’…’): Instruments the kernel function, specified by the value of event, using kernel dynamic tracing of the function entry, and attaches our C defined function, specified by the value of fn_name, to be called when execution hits that event.
- In our example, we specify the event by calling the BPF helper function get_syscall_fnname(“sync”), which simply returns the corresponding kernel function name of the syscall. See get_syscall_fnname()
- Equivalently, doing attach_kprobe(event=’__x64_sys_sync’, fn_name=’hello_world_printk’) produces the same result (given an x64 architecture)
- attach_kprobe
trace_print(fmt=’…’): A BCC routine that reads trace_pipe and prints the output with in the specified format (optional) (used in tandem with bpf_trace_printk).
- By default (i.e. just trace_print()), each read from the trace_pipe comes with the following fields:
- {1}: Process ID (PID)
- {2}: CPU #
- {3}: Flags
- {4}: Unix timestamp
- {5}, {6}, {7}: optional fields (if those fields are used)
- In our case, we only want to print out the message “Hello World!”, so we only specify the 5th ({5}) field, which contains our message
- trace_print
while 1: We use an infinite while loop here (as most BPF programs do) so we can continuously poll the trace_pipe (or any other output stream) and check to see if there’s data to read on the other side.
- Use try: and except: for safer handling
Using BPF_PERF_OUTPUT():
The first example with bpf_trace_printk() was just to get you introduced to how these BPF programs work and how to use BPF’s printk to extract information from it. However, as mentioned before, it should only to be used for debugging, as there’s some serious limitations to it.
In this next example, we’ll use BPF_PERF_OUTPUT() to do the same thing. This method of receiving output from the BPF C program is the recommended approach for most scenarios.
Examine the following BPF program that does the same thing as the previous example, except this time we’re using BPF’s perf output:
#!/usr/bin/python
from bcc import BPF
# Define BPF program
bpf_txt = """
#define MY_STR_LEN 12
BPF_PERF_OUTPUT(events);
struct data_t {
char str[MY_STR_LEN];
};
int hello_world_perf(struct pt_regs *ctx) {
struct data_t data = {};
__builtin_memcpy(&data.str, "Hello World!", sizeof(data.str));
events.perf_submit(ctx, &data, sizeof(data));
return 0;
}
"""
def handle_event(cpu, data, size):
output = bpf_ctx["events"].event(data)
print("%s" % output.str)
# Load BPF program
bpf_ctx = BPF(text=bpf_txt)
bpf_ctx.attach_kprobe(event=bpf_ctx.get_syscall_fnname("sync"),
fn_name="hello_world_perf")
# Print header
print("%s" % "MESSAGE")
# Open perf "events" buffer, loop with callback to handle_event
bpf_ctx["events"].open_perf_buffer(handle_event)
# Format output
while 1:
try:
bpf_ctx.perf_buffer_poll()
except KeyboardInterrupt:
print()
exit()
Compared to the first example using bpf_trace_printk(), using BPF_PERF_OUTPUT() has introduced a few other things we should be aware of:
BPF_PERF_OUTPUT(events): Creates a BPF table for pushing out custom event data to userspace via a perf ring buffer.
- Preferred method for pushing per-event data to userspace
- In our example, the output table is named events and the custom event data (in struct data_t data) is pushed to userspace via. events.perf_submit()
- BPF_PERF_OUTPUT
struct data_t: Defines the custom C data structure to pass data (via perf’s ring buffer) from kernel to userspace.
- In our example, the only data we’re sending is our “Hello World!” string, so we define a char array with a length >= the actual length of the string
__builtin_memcpy(): Built-in version of memcpy().
- Recall that there are no loops allowed in BPF C code, thus memcpy() is not allowed
events.perf_submit(): A method of submitting custom event data to userspace with a BPF_PERF_OUTPUT table.
bpf_ctx[“events”].open_perf_buffer(handle_event): Associate the Python handle_event function with the BPF_PERF_OUTPUT(events) output stream.
- Essentially, “handle the output data from the events perf buffer in the python function handle_event“
- open_perf_buffer
perf_buffer_poll(): Poll any open perf buffers for new data.
- If there’s new data, call the perf buffer stream’s Python handler function (e.g. handle_event) to handle the data
- perf_buffer_poll
handle_event(cpu, data, size): Python function to handle reading events from the events stream.
- The function parameters cpu, data, size are required as arguments
- bpf_ctx[“events”].event(data) grabs the event data as a Python object, which is auto-generated from the C data structure struct data_t
- The fields of the Python event object are exactly as it’s defined in the BPF C program (e.g. output.str)
Example 2: execve Data
For our second example, let’s look at a more interesting system kernel function call, execve(), and see how we can get different types of information from it. Recall that execve() executes the program referred to by its first argument. This will cause the program that is currently being run by the calling process to be replaced with a new program; so we’ll be able to see different processes and their PIDs.
Extracting Event Data:
For this example, we’ll grab some more data about each event. More specifically:
- Timestamp
- PID
- Executed process’s name
- Time taken to execute the execve() function
There are simple BPF function calls that will get us the first three fields, but how do we find the total time it took to execute the execve() function for each executed process?
Recall that we’ve been using kprobes to hook onto the sync() function, and that a kprobe event is essentially the moment execution begins for the kernel function it’s hooked on to. Also recall that a kretprobe event is essentially the moment execution returns from the kernel function it’s hooked on to.
If we can save the time when execution begins and the time when execution ends, we can then find the difference in those two values, thus finding the time it took to execute. And, while it would be easy to send both the start and end time to userspace and find the difference there, it’s much more efficient to handle this in the kernel.
To save the start time, we’ll use a BPF_HASH(name, key, value) where the key will be the PID of the created child process and the value will be the beginning timestamp (in nanoseconds).
Examine the following BPF program:
#!/usr/bin/python
from bcc import BPF
# Define BPF program
bpf_txt = """
#include <linux/sched.h>
// Default key value is u64, but PID is u32
BPF_HASH(start, u32);
BPF_PERF_OUTPUT(events);
struct data_t {
u32 pid;
u64 ts;
char comm[TASK_COMM_LEN];
u64 exe_time;
};
int start_execve(struct pt_regs *ctx) {
u64 ts;
u32 pid;
// Get PID and timestamp (in ns)
pid = bpf_get_current_pid_tgid();
ts = bpf_ktime_get_ns();
// Save the start time (with key=PID) and return
start.update(&pid, &ts);
return 0;
}
int end_execve(struct pt_regs *ctx) {
u64 *tsp, ts, delta;
struct data_t data = {};
// Get PID and end timestamp (in ns)
data.pid = bpf_get_current_pid_tgid();
ts = bpf_ktime_get_ns();
// Get the process's name
bpf_get_current_comm(&data.comm, sizeof(data.comm));
// Lookup start time for corresponding PID
tsp = start.lookup(&data.pid);
if (tsp != NULL) {
// Start time is also the timestamp, find delta
data.ts = *tsp;
data.exe_time = ts - *tsp;
// Delete the hash entry and submit data
start.delete(&data.pid);
events.perf_submit(ctx, &data, sizeof(data));
}
return 0;
}
"""
def handle_event(cpu, data, size):
output = bpf_ctx["events"].event(data)
print("%-18d %-16s %-6d %-16d" %
(output.ts, output.comm, output.pid, output.exe_time))
# Load BPF program
bpf_ctx = BPF(text=bpf_txt)
event_name = bpf_ctx.get_syscall_fnname("execve")
bpf_ctx.attach_kprobe(event="event_name", fn_name="start_execve")
bpf_ctx.attach_kretprobe(event="event_name", fn_name="end_execve")
# Print header
print("%-18s %-16s %-6s %-16s" %
("TIME(ns)", "COMM", "PID", "EXE TIME(ns)"))
# Open perf "events" buffer
bpf_ctx["events"].open_perf_buffer(handle_event)
# Poll for events
while 1:
try:
bpf_ctx.perf_buffer_poll()
except KeyboardInterrupt:
print()
exit()
Example output:
[root@jonpalme-ol7-bm: my_scripts]# ./execve_data.py TIME(ns) COMM PID EXE TIME(ns) 442209714069764 ls 55937 201051 442222059918600 df 55950 197757 442227147857252 lscpu 55955 186674 442236219753381 ip 55963 166857 442244634509346 unix_chkpwd 55972 385405 442244644602391 sh 55973 563984 442244645938214 logrotate 55973 345753 ...
Compared to our previous example, we have a bit more going on here, particularly in the BPF C program. Here we’ve expanded our output data structure struct data_t data to account for the PID, timestamp, current process name, and execution time.
We’re also now using two BPF C functions for our BPF C program: start_execve and end_execve. start_execve gathers the data we want to collect at the beginning of the function (PID & start time) and saves it to our BPF hash table start. Then in end_execve we get the start time (from our start hash table), end time, and find the difference. Lastly, still in end_execve, we pack up the rest of the data we want and submit it to userspace.
Let’s take a look at some of the new things we see in this example:
BPF_HASH(start, u32): Creates a hash map named “start”, with the key type being u32.
- Default: BPF_HASH(name, key_type=u64, value_type=u64, size=10240)
- Our key type is u32 here since bpf_get_current_pid_tgid returns the PID in the lower 32 bits and the thread group ID in the upper 32 bits. Setting this to u32 automatically discards the upper 32 bits
- BPF_HASH
bpf_get_current_pid_tgid(): Returns the process ID in the lower 32 bits and the thread group ID in the upper 32 bits.
- The pid in the lower 32 bits is the kernel’s view of the PID (userspace usually presents this as the thread ID)
- The thread group ID is in the upper 32 bits and is what userspace often thinks of as the PID
- Returns u64 but setting this to u32 discards the upper 32 bits
- bpf_get_current_pid_tgid
bpf_ktime_get_ns(): Returns a u64 number as time in nanoseconds.
- The number of nanoseconds since system boot
- bpf_ktime_get_ns
bpf_get_current_comm(): Populates the first argument address with the current process name.
- The first argument should be a pointer to a char array of at least size TASK_COMM_LEN, which is defined in linux/sched.h
- bpf_get_current_comm
start.lookup(): Lookup the key in the map, and return a pointer to its value if it exists, else NULL.
- We pass the key in as an address to a pointer
- map.lookup
start.delete(): Delete the key from the hash.
start.update(): Associate the value in the second argument with the key, overwriting any previous value.
attach_kretprobe(event=’…’, fn_name=’…’): Instruments the return of the kernel function event and attaches our C defined function name to be called when the kernel function returns.
- We attach both a kprobe and kretprobe in our example to find the start and end time of the kernel function
- attach_kretprobe
Extracting More Event Data
What if we wanted to know more about the commands issued from our previous example? Say, the arguments of each command, up to some number of arguments? Well, we can do that! While we’re at it, let’s also get the return value of execve from our kretprobe.
Recall the arguments to execve:
SYSCALL_DEFINE3(execve,
const char __user *, filename,
const char __user *const __user *, argv,
const char __user *const __user *, envp)
{
return do_execve(getname(filename), argv, envp);
}
Examine the code below to see how we do this:
#!/usr/bin/python
from bcc import BPF
# Define BPF program
bpf_txt = """
#include <linux/sched.h>
// Default key value is u64, but PID is u32
BPF_HASH(start, u32);
BPF_PERF_OUTPUT(events);
BPF_PERF_OUTPUT(args);
#define ARGSIZE 128
#define MAXARGS 8
struct args {
char argv[ARGSIZE];
};
struct data_t {
u32 pid;
u64 ts;
char comm[TASK_COMM_LEN];
u64 exe_time;
int retval;
};
int syscall_execve(struct pt_regs *ctx,
const char __user *filename,
const char __user *const __user *__argv,
const char __user *const __user *__envp) {
u64 ts;
u32 pid;
struct args arg_data = {};
// Get PID and timestamp (in ns)
pid = bpf_get_current_pid_tgid();
ts = bpf_ktime_get_ns();
// Save the start time (with key=PID) and return
start.update(&pid, &ts);
// Get full filepath for command
bpf_probe_read_user(&arg_data.argv, sizeof(arg_data.argv), (void *)filename);
args.perf_submit(ctx, &arg_data, sizeof(arg_data));
// Read arguments (up to MAXARGS arguments)
#pragma unroll
for (int i = 1; i < MAXARGS; i++) {
const char *argp = NULL;
bpf_probe_read_user(&argp, sizeof(argp), (void *)&__argv[i]);
if (argp) {
bpf_probe_read_user(&arg_data.argv, sizeof(arg_data.argv), (void *)(argp));
args.perf_submit(ctx, &arg_data, sizeof(arg_data));
}
else break;
}
return 0;
}
int end_execve(struct pt_regs *ctx) {
u64 *tsp, ts, delta;
struct data_t data = {};
// Get PID and end timestamp (in ns)
data.pid = bpf_get_current_pid_tgid();
ts = bpf_ktime_get_ns();
// Get the process's name
bpf_get_current_comm(&data.comm, sizeof(data.comm));
// Lookup start time for corresponding PID
tsp = start.lookup(&data.pid);
if (tsp != NULL) {
// Start time is also the timestamp, find delta
data.ts = *tsp;
data.exe_time = ts - *tsp;
// Delete the hash entry and submit data
start.delete(&data.pid);
// Save return value of execve
data.retval = PT_REGS_RC(ctx);
events.perf_submit(ctx, &data, sizeof(data));
}
return 0;
}
"""
argvs = ""
def arg_builder(cpu, data, size):
global argvs
output = bpf_ctx["args"].event(data)
argvs = argvs + output.argv + " "
def handle_event(cpu, data, size):
global argvs
output = bpf_ctx["events"].event(data)
print("%-18d %-16s %-6d %-10d %-35s %-5d" %
(output.ts, output.comm, output.pid, output.exe_time, argvs, output.retval))
argvs = ""
# Load BPF program
bpf_ctx = BPF(text=bpf_txt)
event_name = bpf_ctx.get_syscall_fnname("execve")
bpf_ctx.attach_kprobe(event="event_name", fn_name="start_execve")
bpf_ctx.attach_kretprobe(event="event_name", fn_name="end_execve")
# Print header
print("%-18s %-16s %-6s %-10s %-35s %-5s" %
("TIME(ns)", "COMM", "PID", "EXE TIME", "ARGS", "RETVAL"))
# Open perf "events" buffer
bpf_ctx["events"].open_perf_buffer(handle_event)
bpf_ctx["args"].open_perf_buffer(arg_builder)
# Poll for events
while 1:
try:
bpf_ctx.perf_buffer_poll()
except KeyboardInterrupt:
print()
exit()
Example output:
[root@jonpalme-ol7-bm: my_scripts]# ./execve_more_data.py TIME(ns) COMM PID EXE TIME ARGS RETVAL 680084610622215 ls 53036 258291 /bin/ls --color=auto -a 0 680088120119237 ls 53039 150290 /bin/ls --color=auto /tmp -lrt 0 680095079987477 ps 53046 191785 /bin/ps -aA 0 ...
To get all the arguments from the executed command, we’ve added a few more interesting things to the BPF C program:
BPF_PERF_OUTPUT(args): Another perf output table called args that we’ll send our arguments to userspace to be concatenated.
- We put each argument individually into our arguments data structure (struct args) and submit them one by one
- I did try to do this with a 2D char array but the verifier didn’t like it
syscall_execve(…): Here we notice that the function name has changed and there are more parameters added to our BPF C function, exactly as they are defined in its original definition.
- To access the parameters of a syscall, you must define the name of your BPF C function as syscall__<syscall name>
- Note that struct pt_regs *ctx is still defined first. This is important, as this parameter must come first before the rest of the arguments to execve
PT_REGS_RC(ctx): Fetches the return value of the current context (e.g. execve in our example).
- Although for execve, the return value is normally 0 and not too interesting in this case… but good to know how to retrieve the return value!
Further Reading
In the third and last part of this blog series, we’ll take a look at some more complex BCC scripts and learn how to setup userspace and kernel static tracepoints in QEMU and in the Linux kernel.
References
BPF Performance Tools by Brendan Gregg (O’Reilly E-Book):
BCC GitHub Repository:
- https://github.com/iovisor/bcc
- Installation: INSTALL.md
- README: README.md
- BCC Python Developer Tutorial: tutorial_bcc_python_developer.md
- BCC + BPF Reference Guide: reference_guide.md
LWN.net Kernel Tracepoints Guide (TRACE_EVENT() macro):
- Part 1: https://lwn.net/Articles/379903/
- Part 2: https://lwn.net/Articles/381064/
- Part 3: https://lwn.net/Articles/383362/
- sched_switch Example: https://lwn.net/Articles/379952/
LWN.net Using Userspace Tracepoints w/ BPF (DTRACE_PROBEn() macro):
Other LWN.net Tracing / BPF / BCC Articles:
- Tracepoints with BPF: https://lwn.net/Articles/683504/
- A Thorough Introduction to eBPF: https://lwn.net/Articles/740157/
- An Introduction to the BPF Compiler Collection: https://lwn.net/Articles/742082/
- Some Advanced BCC Topics: https://lwn.net/Articles/747640/
Brendan Gregg’s Blog / Website:
- Linux Extended BPF (eBPF) Tracing Tools: http://www.brendangregg.com/ebpf.html#perf
- Choosing a Linux Tracer (2015): http://www.brendangregg.com/blog/2015-07-08/choosing-a-linux-tracer.html
- perf Examples: http://www.brendangregg.com/perf.html
- perf-tools GitHub: https://github.com/brendangregg/perf-tools
Other Resources:
- Technical Paper on BPF (1992, PDF): http://www.tcpdump.org/papers/bpf-usenix93.pdf
- eBPF Lost Events: http://blog.itaysk.com/2020/04/20/ebpf-lost-events
- Linux Tracing with BPF, BCC, and More: https://www.accelevents.com/e/OSSELCEU2020/portal/schedule/69241
- Linux Tracing Systems (Blog): https://jvns.ca/blog/2017/07/05/linux-tracing-ystems/
- Linux Systems Performance (2016, slidedeck): https://www.slideshare.net/brendangregg/linux-systems-performance-2016