Introduction
This is part 1 of a 3-part series, the goal of which is to provide a brief introduction on BCC and how to get started using it to trace kernel and userspace applications. This page is written assuming the reader isn’t familiar with Linux tracing. So, as a general introduction, we’ll first briefly go over general tracing terminology and then dive into BCC. If you’re already familiar with tracing terminology and just want to jump into BCC, feel free to skip ahead to that section.
In this first part I will give an introduction to tracing, BPF, and BCC at a high level. Part 2 of this series will dive into two BCC script examples. Lastly, part 3 will dive into more advanced BCC script examples in QEMU and in kernel.
Much of the information on these pages comes from the book BPF Performance Tools by Brendan Gregg and the resources in the BCC GitHub /docs repository (e.g. reference_guide.md, tutorial_bcc_python_developer.md, etc.), but will not touch as many topics listed in these resources. Once you get the hang of using BCC, you’ll definitely want to check out these resources to further expand your capabilities with BCC. Links for these resources (and many others) will be in the References section at the end of this page.
Linux Tracing
Before jumping into using BCC, it’s important to at least familiarize yourself with the common tracing terminology used today. There are many ways to observe and trace things; knowing the extent of what you’d like to observe and the capabilities of tracing frontends (including BCC!) will save you lots of time and frustration.
The following are terms used to classify analysis techniques and tools:
- Tracing – event-based recording
- BCC uses this type of instrumentation
- Synonymous with snooping or event dumping
- Can run small programs on traced events to do on-the-fly processing
- Sampling – taking a subset of measurements to create a rough profile of a target
- Perf uses this type of instrumentation
- Synonymous with profiling
- Lower performance overhead vs. tracing
- Observability – understanding a system through observation, and classifies the tools that accomplish this
- Depends on what is needed to gain understanding for a targeted system or application
- Can use tracing and/or sampling to accomplish this
- Visibility – the ability to observe or trace something
- I.e. GDB provides visibility into code execution
- Dynamic tracing has no visibility on inlined functions
- Static tracing has visibility on inlined functions
- Events – an action in software that causes a probe or tracepoint to “fire” (send information)
- Loosely defined; an event can be simply hitting a function, a special case in a function, the end of the function, beginning of a routine, etc.
- User essentially defines the event based on what probe/tracepoint they’ve enabled and when/where it would fire
Tracing Terminology:
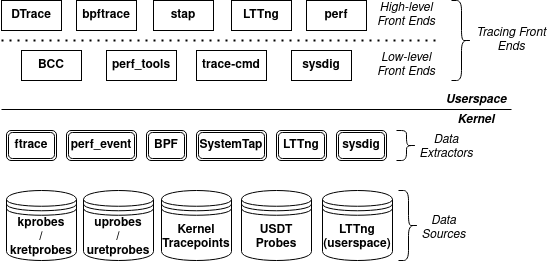
This diagram is essentially a big picture look into Linux tracing. It’s important to note that this isn’t a complete list of everything that is out there, and not every frontend uses every data extractor or data source.
This page doesn’t go over everything in the diagram above in detail. We’ll focus instead on the data sources, more specifically kprobes/kretprobes, uprobes/uretprobes, kernel tracepoints, and USDT probes. Understanding the different data sources and their capabilities is key to understanding the capabilities of a tracing frontend. For example, sysdig uses none of the data sources listed, and only has visibility on system calls.
One thing worth mentioning is BCC’s relation to the diagram above. As mentioned, BCC is a tracing frontend. A tracing frontend is an application that provides tracing techniques and capabilities (and sometimes sampling as well, like perf).
There are two categories to tracing frontends: low-level and high-level frontends. A high-level frontend is typically a more user-friendly tracing tool suite that you can use to get quick observability on your target. Some high-level tracing frontends are built ontop of low-level frontends, such as bpftrace being build on top of BCC. A low-level tracing frontend is typically more bare bones and less user-friendly, requiring a bit more work on the developer’s side to make use out of them. The benefit of low-level frontends is that you get a bit more flexibility and control over events, data processing and display (although DTrace and bpftrace can provide some of that flexibility and control as well).
BCC is considered a low-level frontend because, well, we have to write our own scripts to use it! In other words, there’s no command to call like there is for DTrace and bpftrace, we’ll be calling our own (typically Python) scripts instead.
One last note: in case you’re unfamiliar, BCC stands for BPF Compiler Collection. The BPF data extractor in the diagram above is this BPF. BPF (or eBPF) provides visibility both in kernel (kprobes/kretprobes, kernel tracepoints) and userspace (uprobes/uretprobes, USDT probes), making BCC a competitive and flexible frontend.
Dynamic and Static Tracing:
The data sources we’re going to be looking at are kprobes/kretprobes, kernel tracepoints, uprobes/uretprobes, and USDT probes. They are very powerful and are typically categorized by their dynamic and static tracing capabilities. kprobes/kretprobes and uprobes/uretprobes are a form of dynamic instrumentation whereas kernel tracepoints and USDT probes are a form of static instrumentation.
Dynamic Tracing – inserting instrumentation points into live software (e.g. in production)
- Also known as dynamic instrumentation
- kprobes/kretprobes: dynamic instrumentation for kernel-level functions
- kprobes fire when execution hits the beginning of the target kernel function being traced
- kretprobes fire when execution returns from the target kernel function being traced
- uprobes/uretprobes: dynamic instrumentation for userspace-level C functions
- uprobes fire when execution hits the beginning of the target userspace C function
- uretprobes fire when execution returns from the target userspace C function
- Pros: zero overhead when not in use, no recompiling or rebuilding needed
- Cons: functions can be renamed or removed from one software version to the next (interface stability issue), no visibility on inline‘d functions
Static Tracing – inserting stable tracepoints that are statically defined in software
- Also known as static instrumentation
- Defined and implemented by the developer
- Kernel Tracepoints: static instrumentation for kernel-level code
- Currently defined kernel tracepoints for a Linux machine can be found in /sys/kernel/debug/tracing/events/*
- Define new kernel tracepoints in include/trace/events
- USDT Tracepoints: static instrumentation for userspace-level C code
- Also known as USDT probes, user markers, userspace tracepoints, etc.
- Can be added to an application using headers and tools from the systemtap-sdt-dev package, or with custom headers
- Pros: can be placed anywhere in code (including inline‘d functions), high visibility on variables (including structs), more stable API
- Cons: many defined tracepoints can become a maintenance burden, requires recompile/rebuild to add new tracepoints, non-zero overhead for disabled tracepoints (nop instruction at tracepoint)
Linux Tracing: Summary
Tracing has several technologies that many frontends are able to interact with, the most powerful ones being kprobes, uprobes, kernel tracepoints and USDT probes/tracepoints. Having a frontend that uses both static and dynamic tracing, in most cases, is going to be your best bet on getting observability across your systems.
Remember that kprobes and uprobes are dynamically inserted, meaning that they’re already there in live production, the tracer just needs to hook onto and enable them for them to become active. The benefit of dynamic tracing is that the overhead of disabled probes is zero, as well as the fact that they’re already in kernel and userspace. The drawback to dynamic tracing is that any tracing tools using them may break over future software versions. This is because the functions that kprobes and uprobes attach to (e.g. the name of the function and it’s parameters and return value) can change over time, thus changing the scope of the probe.
On the other hand, kernel tracepoints and USDT tracepoints are statically inserted, meaning that they need to be defined and implemented by the developer. One benefit of static tracing is that it has a more stable API, since the developer can define the name and parameters to whatever they want. Following that, another big benefit is that you can trace whatever wherever in the targeted function. That is, while you are limited to tracing the parameters and return values in dynamic tracing, static tracing lets you trace whatever variable (including structs) is visible in the function where the tracepoint resides. Consequently, one of the drawbacks to this is maintenance. As more tracepoints are defined, there’s more of a risk that one of these tracepoints no longer becomes compatible as software versions change.
As a general recommendation, it is best to use static tracing first and then switch to dynamic tracing when static tracing is unavailable.
Intro to BCC
BCC (BPF Compiler Collection) was the first higher-level tracing framework developed for BPF (Berkeley Packet Filter). BPF was an obscure technology developed in 1992 to improve the performance of network packet filtering. In 2013, BPF was rewritten and further developed into eBPF (extended BPF) and included in the Linux kernel in 2014. This rewrite of BPF turned it into a general-purpose execution engine, increasing the potential of the BPF technology drastically.
This new technology provides the means to run mini programs on a wide range of kernel and userspace application events, such as disk I/O or QEMU. Essentially, it makes the kernel fully programmable, empowering kernel and non-kernel developers to tailor and control their systems in any way they see fit (and BCC makes it quite straightforward to do this).
BPF is considered as a virtual machine due to its virtual instruction set specification (not to be interpreted as another machine layer on top of the processor). These instructions are executed by a Linux kernel BPF runtime, which includes an interpreter and JIT compiler for turning BPF instructions into native instructions for execution.
BPF also uses a verifier that checks BPF instructions for safety, ensuring the BPF program will not crash or corrupt the kernel. However, it’s not perfect, as it doesn’t prevent the user from writing illogical (but executable) programs. An implicit divide by zero error, for example, would not be caught by the verifier. An unbound for loop, however, would be caught by the verifier.
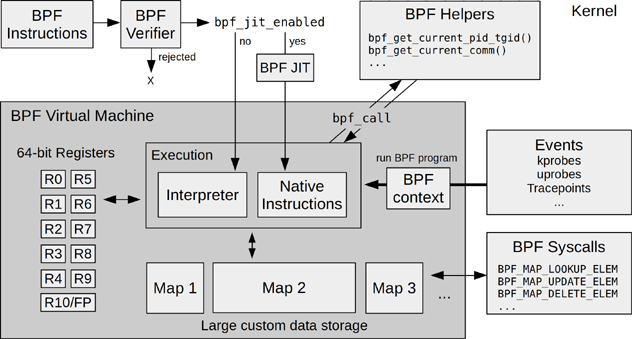
Why Should We Care About BCC?
If the real powerhouse behind BCC is really BPF, then what does BCC really do for us? Well, before BCC, the only frontends to BPF (recall the BPF data extractor in the Linux big picture diagram) were raw BPF byte code, C, and perf. While the raw potential of these tools/frontends are very high, it’s very difficult, if not impractical, to make full use out of BPF with these. In other words, the learning curve is too steep for most and other tracing technologies would be chosen instead (trading capability for simplicity).
BCC preserves the raw potential of BPF and also makes it much more accessible to the average developer. It provides a C programming environment for writing kernel BPF C code (also known as embedded C) and Python, Lua, or C++ for a userspace interface. In other words, you can use embedded C to extract data from traced events and use a Python script, Lua, or C++ program to further handle and display the data the way you want. The learning curve to get started making your own BPF program with BCC is greatly reduced (and fairly straightforward), especially now as it’s had time to mature over the years it’s been out, more documentation, etc.
Aside from making the potential of BPF much more tangible, the BCC repository also contains more than 70+ ready-to-go BPF programs for performance analysis and debugging. As you can see in the diagram below, there’s a script for pretty much anything across the stack! These are ready-to-go out of the box, along with thorough documentation and example usages for each of them. There’s also a plethora or resources and even guides to help you get started developing your own BPF programs.
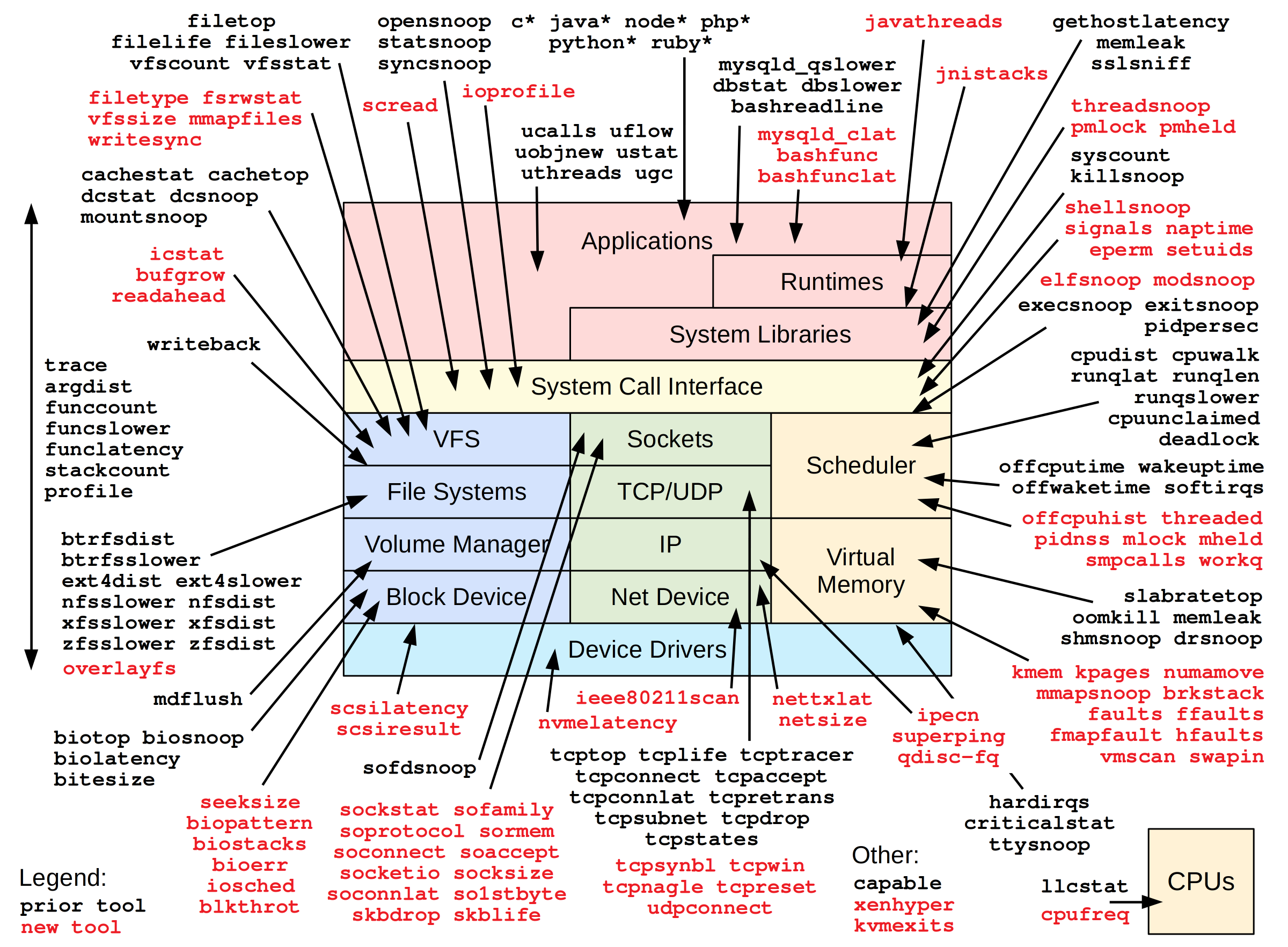
Who Would be Interested in BCC?
To be fair, writing a C program to extract data and writing up a Python or C++ program to handle and display the data isn’t the fastest thing to do in tracing, especially when you can use a one-liner on a different frontend to get the same result (although BCC does have the BPF tool trace.py that gives that “one-liner” ability).
In my opinion, these might be some of the reasons why someone would find BCC useful over other tracing frontends:
- you want something like perf but more control on the data collected and displayed
- you want to collect custom statistical data, watch for specific events, etc.
- you want to create a custom analysis tool for a system/subsystem
- you want full control over traced events, data handling, and output display
- you need to use BPF (for whatever reason)
- one of the pre-made BPF tools does something close to what you want (and you want to edit it)
Of course this isn’t every reason why someone would use BCC, but it covers most cases. Essentially, BCC is great when you need a deeper view into what’s going on in a system and you want total control over the data you’re collecting.
BCC Features:
The lists below are full lists of what BCC has to offer us, including kernel-level features, user-level features, and a few highlighted pre-made BPF tools. Note that most of the features listed below are not covered in this page. Since this is an introduction, we’ll focus on the basics of what you’ll want to know first to get started. Once you’re comfortable with the basics, you can then start to explore the other features BCC offers.
Kernel-Level Features
BCC can use a number of kernel-level features, such as BPF, kprobes, uprobes, etc. The following list includes some implementation details (in parentheses):
- Dynamic tracing, kernel-level (BPF support for kprobes)
- Dynamic tracing, user-level (BPF support for uprobes)
- Static tracing, kernel-level (BPF support for kernel tracepoints)
- Timed sampling events (BPF with perf_event_open())
- PMC events (BPF with perf_event_open())
- Filtering (via. BPF programs)
- Debug output (bpf_trace_printk())
- Per-event output (bpf_perf_event_output())
- Basic variables (global and per-thread variables, via BPF maps)
- Associative arrays (via BPF maps)
- Frequency counting (via BPF maps)
- Histograms (power-of-two, linear, and custom; via BPF maps)
- Timestamps and time deltas (bpf_ktime_get_ns() and BPF programs)
- Stack traces – kernel (BPF stack map)
- Stack traces – userspace (BPF stack map)
- Overwrite ring buffers (perf_event_attr.write_backward)
- Low-overhead instrumentation (BPF JIT, BPF map summaries)
- Production safe (BPF verifier)
For more information and background on these kernel-level features, please see Chapter 2: Technology Background in the BPF book by Brendan Gregg.
User-Level Features
BCC also provides a number of user-level features from the BCC user-level frontend. Implementation details (in parentheses):
- Static tracing, user-level (SystemTap-style USDT probes via. uprobes (e.g. DTRACE_PROBEn()))
- Debug output (Python with BPF.trace_pipe() and BPF.trace_fields())
- Per-event output (BPF_PERF_OUTPUT macro and BPF.open_perf_buffer())
- Interval output (BPF.get_table() and table.clear())
- C struct navigation, kernel-level (BCC rewriter maps to bpf_probe_read())
- Symbol resolution, kernel-level (kysm() and kysmaddr())
- Symbol resolution, user-level (usymaddr())
- Debuginfo symbol resolution support
- BPF tracepoint support (via. TRACEPOINT_PROBE)
- BPF stack trace support (BPF_STACK_TRACE)
For more information and background on these user-level features, again, see Chapter 2: Technology Background in the BPF book by Brendan Gregg.
Other Features: Tutorials, Premade Tools, Reference Guide
Aside from all of the technological features that BCC has to offer, it also comes with a plethora of examples, tutorials, and pre-made tools. These are all very useful and you’re definitely going to want to check them out if you haven’t already.
There are two tutorials included in the BCC repository: a tutorial for using BCC tools to solve performance, troubleshooting, and networking issues, and a BCC BPF Python developer tutorial to get you started making your own BPF programs in C and Python. This is what we’ll be doing when creating some examples in the next section, except these examples are my own and meant to compliment BCC’s Python developer guide. That is, once you’ve gone through my examples, you’ll want to also go through the BCC developer guide’s examples as well.
- docs/tutorial.md: Using BCC tools to solve performance, troubleshooting, and networking issues
- docs/tutorial_bcc_python_developer.md: Developing new BCC BPF programs using the Python interface
The pre-made BPF tools that come with BCC can be found in tools/*, and there are lots of them! Each tool comes with their own *.txt file that acts like a manpage for that tool. Some of these tools include:
- tools/biolatency.py/txt: summarize block device I/O latency as a histogram
- tools/cpuunclaimed.py/txt: sample CPU run queues and calculate the unclaimed idle CPU
- tools/hardirqs.py/txt: measure hard IRQ (hard interrupt) event time
- tools/klockstat.py/txt: traces kernel mutex lock events and displays lock statistics
- etc. …
You can find the complete list of these pre-made tools on the front page of the BCC GitHub repository (README.md)
Lastly, we also have the BCC reference guide. It should be noted that you may not find everything in here and there are some missing API entries (i.e. bpf_usdt_readarg()). However, most of the things you’ll need are listed here, and if not explicitly, you can find example usages in the pre-made tools and examples to help you out.
- docs/reference_guide.md: reference guide to the BCC/BPF APIs
Further Reading:
This intro section to BCC isn’t a comprehensive summary of the BCC and BPF technology. I’ve only lightly summarized a few of the key points to BCC and BPF. If you would like to take a deeper dive into the internals of BPF and BCC, again, I highly recommend you check out the BPF Performance Tools book by Brendan Gregg (link in Resources section). More specifically, Chapter 1: Introduction, Chapter 2: Technology Background and Chapter 4: BCC. Ignore the bpftrace sections, as we’re not looking at bpftrace at the moment.
In part 2 of this series we’ll start diving into getting set up with BCC and get some examples going. Again, once you get through the examples in part 2 and part 3, you’ll definitely want to check out BCC’s Python developer guide to expand your knowledge (and capabilities) with BCC.
References
BPF Performance Tools by Brendan Gregg (O’Reilly E-Book):
BCC GitHub Repository:
- https://github.com/iovisor/bcc
- Installation: INSTALL.md – README: README.md – BCC Python Developer Tutorial: tutorial_bcc_python_developer.md
- BCC + BPF Reference Guide: reference_guide.md
LWN.net Kernel Tracepoints Guide (TRACE_EVENT() macro):
- Part 1: https://lwn.net/Articles/379903/
- Part 2: https://lwn.net/Articles/381064/
- Part 3: https://lwn.net/Articles/383362/
- sched_switch Example: https://lwn.net/Articles/379952/
LWN.net Using Userspace Tracepoints w/ BPF (DTRACE_PROBEn() macro):
Other LWN.net Tracing / BPF / BCC Articles:
- Tracepoints with BPF: https://lwn.net/Articles/683504/
- A Thorough Introduction to eBPF: https://lwn.net/Articles/740157/
- An Introduction to the BPF Compiler Collection: https://lwn.net/Articles/742082/
- Some Advanced BCC Topics: https://lwn.net/Articles/747640/
Brendan Gregg’s Blog / Website:
- Linux Extended BPF (eBPF) Tracing Tools: http://www.brendangregg.com/ebpf.html#perf
- Choosing a Linux Tracer (2015): http://www.brendangregg.com/blog/2015-07-08/choosing-a-linux-tracer.html
- perf Examples: http://www.brendangregg.com/perf.html
- perf-tools GitHub: https://github.com/brendangregg/perf-tools
Other Resources:
- Technical Paper on BPF (1992, PDF): http://www.tcpdump.org/papers/bpf-usenix93.pdf
- eBPF Lost Events: http://blog.itaysk.com/2020/04/20/ebpf-lost-events
- Linux Tracing with BPF, BCC, and More: https://www.accelevents.com/e/OSSELCEU2020/portal/schedule/69241
- Linux Tracing Systems (Blog): https://jvns.ca/blog/2017/07/05/linux-tracing-systems/
- Linux Systems Performance (2016, slidedeck): https://www.slideshare.net/brendangregg/linux-systems-performance-2016