Introduction
The Linux kernel organizes physical memory in units of pages of a certain size called base pages. For example, the default base page size when running on Intel processors is 4KB. These pages are allocated to user and kernel tasks as they need memory. When processing large amounts of data from slower disk devices, the Linux kernel uses a page cache to cache contents, like disk blocks, to speed up access to frequently accessed data. See this article for more details on how various caches are used by the Linux kernel. This has the positive effect of improving overall system performance but the memory for page cache must come from the same memory pool that is used by rest of the system. The kernel allocates all the memory not currently in use to the page cache. As the kernel needs to allocate more memory for other tasks, it can reclaim pages from the page cache since the contents in the page cache can be restored from disk blocks when the need arises. Reclamation happens as the kernel starts to run low on free memory pages. Individual memory pages are the base pages. As pages are reclaimed, any contiguous base pages are grouped together (compaction) to form higher order pages. Higher order pages are groups of 2^n physically contiguous pages where n is the page order. Higher order pages can then be used to satisfy higher order page allocation requests, for example if an allocation request is for 8 pages, that allocation will be made from order 3 page group.
The kernel recovers physical memory in the event of a shortage by page reclamation and/or compaction. Both methods are implemented in a similar fashion. As the amount of free memory falls below the low threshold (watermark), memory pages are reclaimed asynchronously via kswapd or compacted via kcompactd. If the free memory continues to fall below a minimum watermark, any allocation request is forced to perform reclamation/compaction synchronously before it can be fulfilled. The latter synchronous method is referred to as the “direct” path and is considerably slower owing to being stalled waiting for memory to be reclaimed. The corresponding stall in the caller results in a non-deterministic increased latency for the operation it is performing and is typically perceived as an impact on performance.
Direct compaction and reclamation will be avoided if their asynchronous counterparts can reclaim memory more quickly than is consumed. Conversely, if memory is consumed more quickly than it may be reclaimed, then stalling can be delayed or possibly avoided only by increasing the watermark at which the asynchronous daemons are activated. However, this increases the risk of excessive reclamation/compaction activity when there is no real threat of memory exhaustion. This situation is further exacerbated by the fact that different workloads have different memory consumption patterns. Some workloads allocate and free memory at a steady rate like a media streaming program that is reading disk blocks, rendering the media, freeing up already rendered data and fetching more data to render. Other workloads like scientific modeling might allocate a large number of pages over a period of time to read in data from disk, then they perform data computation on this accumulated data while allocating smaller amounts of memory and finally they may release all the memory holding data before starting next modeling run. Still some workloads like transaction processing have periodic spikes of memory allocation requests that keep recurring over long periods of times. This makes it hard to define static watermarks that work across large number of workloads. Long running workloads can also have different memory consumption patterns over the course of their life which makes a static watermark a compromise at best.
A better approach to managing watermarks would be to monitor the overall memory consumption pattern on a system and autotune the watermarks dynamically in response to that pattern. This blog introduces a project, adaptivemm that uses a mathematical forecasting technique to identify imminent memory exhaustion with a view to averting it by preemptive memory reclamation. The objective is to reduce stalls even under high rates of memory consumption and avoid compaction or page reclamation until absolutely necessary. adaptivemm source code has been released under GPLv2.
Page Reclamation and Compaction
There are three watermarks that trigger various actions for free memory management:
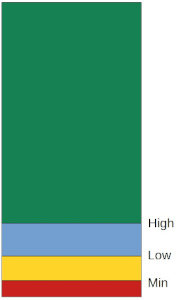
When the number of free pages reaches the low watermark, kswapd wakes up and starts scanning page cache for reclaimable pages. When it completes a scan of page cache, it may wake up kcompactd to compact any contiguous free pages:
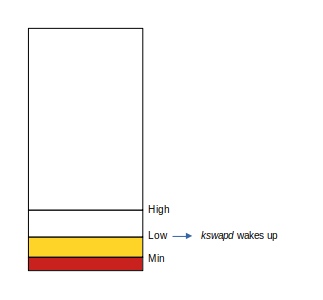
If memory consumption continues at high rate, the number of free pages can reach the min watermark. At this point, any non-GFP_ATOMIC requests to allocate memory causes processes to enter direct reclamation/compaction path. Only GFP_ATOMIC allocation requests are fulfilled without reclamation once free memory drops below the min watermark. In case of direct reclamation/compaction, the requesting process is put on a wait queue until enough free pages become available to satisfy the allocation request. This results in an allocation or compaction stall:
Allocation/compaction stalls can cause a significant performance impact on the workload. This impact can be non-deterministic and depends upon how often the stalls happen and how long each instance last.
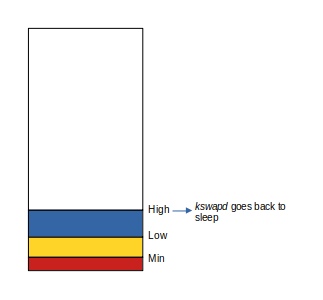
As kswapd continues to reclaim available pages, the number of free pages eventually reaches the high watermark at which point, reclamation stops:
The kernel responds to low memory events after they have happened. When the rate of memory consumption is high, going from the low watermark to the min watermark can become a recurring event. This causes frequent memory stalls. To reduce such occurrences, one could increase the distance between the min and low watermarks, and low and high watermarks. The kernel provides an interface /proc/sys/vm/watermark_scale_factor to do this. By changing this value, the low and high watermarks can be raised and lowered. The kernel keeps a minimum amount of free memory pages to satisfy PF_MEMALLOC^1 allocations, exposed to userspace as /proc/sys/vm/min_free_kbytes. This minimum amount is reflected in the min watermark. The kernel computes the values for the three watermarks by using min_free_kbytes and watermark_scale_factor in __setup_per_zone_wmarks() in mm/page_alloc.c:
tmp = (u64)pages_min * zone_managed_pages(zone);
do_div(tmp, lowmem_pages);
....
....
zone->_watermark[WMARK_MIN] = tmp;
....
/*
* Set the kswapd watermarks distance according to the
* scale factor in proportion to available memory, but
* ensure a minimum size on small systems.
*/
tmp = max_t(u64, tmp >> 2,
mult_frac(zone_managed_pages(zone),
watermark_scale_factor, 10000));
zone->watermark_boost = 0;
zone->_watermark[WMARK_LOW] = min_wmark_pages(zone) + tmp;
zone->_watermark[WMARK_HIGH] = min_wmark_pages(zone) + tmp * 2;
The value for min_free_kbytes is calculated by init_per_zone_wmark_min() in mm/page_alloc.c:
int __meminit init_per_zone_wmark_min(void)
{
unsigned long lowmem_kbytes;
int new_min_free_kbytes;
lowmem_kbytes = nr_free_buffer_pages() * (PAGE_SIZE >> 10);
new_min_free_kbytes = int_sqrt(lowmem_kbytes * 16);
if (new_min_free_kbytes > user_min_free_kbytes) {
min_free_kbytes = new_min_free_kbytes;
if (min_free_kbytes < 128)
min_free_kbytes = 128;
if (min_free_kbytes > 262144)
min_free_kbytes = 262144;
} else {
pr_warn("min_free_kbytes is not updated to %d because user defined value %d is preferred\n",
new_min_free_kbytes, user_min_free_kbytes);
}
The value of min_free_kbytes was capped at 64M until this commit which raised the cap to 256M. Increasing min_free_kbytes results in more reasonable watermarks for machines with large amounts of physical RAM but it is still a fixed value irrespective of workloads.
Raising the distance between watermarks can cause kswapd to start reclamation earlier and reclaim a higher number of pages before going back to sleep. This works well during periods of high memory consumption. When the rate of memory consumption drops, leaving the watermarks high causes fewer pages to be available to page cache which in turn affects performance by reducing cache effect. To resolve this, the watermarks must be lowered during periods of low memory demand. This makes the case for an adaptive system where watermarks are not fixed at all times.
Proactive and Adaptive Free Memory Management
Most workloads follow a pattern of memory usage. It often can be a short term pattern. By analyzing the current memory usage pattern of the workload, it becomes possible to forecast a memory usage pattern in the immediate future. This in turn makes it possible to forecast any upcoming free page or higher order page exhaustion on the system if current consumption and free patterns hold.
The project adaptivemm uses a least square fit method to calculate a trend line that fits the number of free pages plotted along a time axis. It collects data points periodically for the number of free pages of each order by reading /proc/buddyinfo. Consider the following data set collected periodically which shows the total number of free pages:
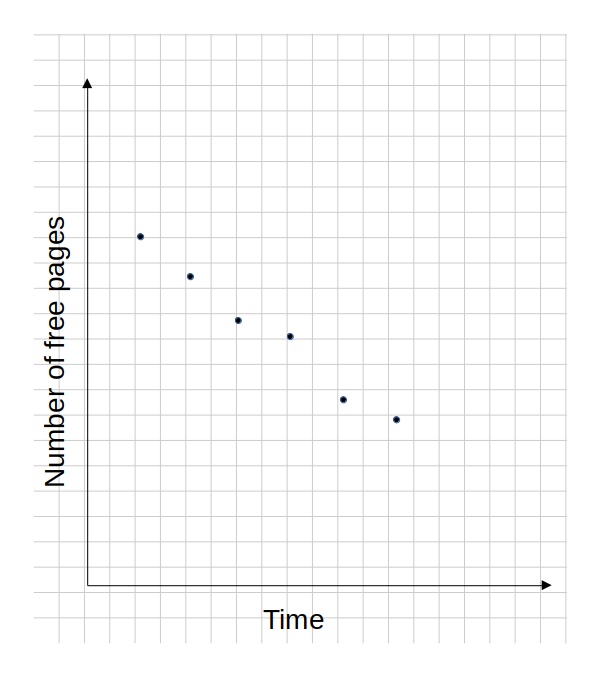
Using the least square method, a line can be fit to these data points to show a linear trend:
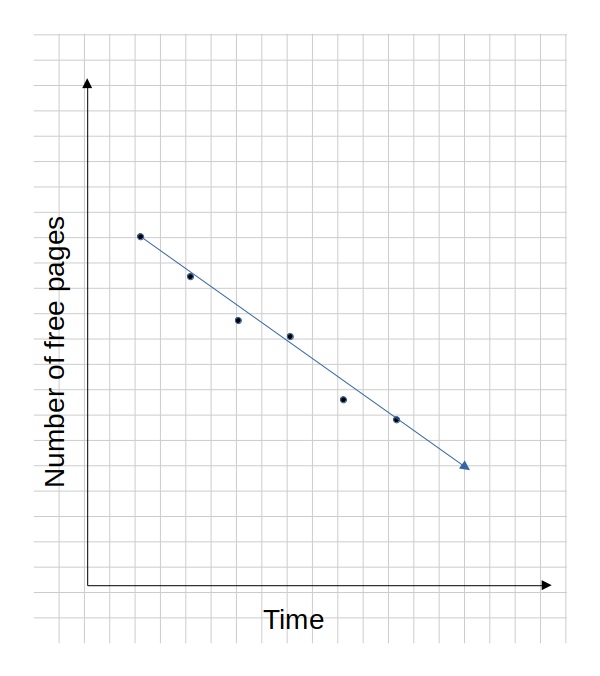
This line can be represented as f = a + bx where f is the number of free memory pages, a and b are constants representing the intercept and slope, and x is time. This equation can then be used to project when the number of free pages will reach the high or low watermark by solving for x with the low and high watermark values of f. A similar trend line can be computed for each order page and the trend line can be projected forward to determine when pages of each order will be exhausted. Similarly a trend line can be computed for page reclamation by gathering pgsteal data from /proc/vmstat. A trend line for compaction rate can be computed by calculating the number of higher order pages created across datapoints from /proc/buddyinfo. With a trend line available for reclamation and a trend line available for tge number of free pages, adaptivemm can compute how far in advance it needs to adjust the watermarks to ensure free pages will not be exhausted.
adaptivemm computes trend lines for data points inside a sliding window. This sliding window covers the last n data points (where n=8 for the implementation at the time this blog was written). The sliding window is advanced at each data collection interval and thus can be used to effectively compute the current trend even as the memory consumption trend for the workload changes. adaptivemm raises the watermarks by changing watermark_scale_factor as memory consumption rises and it also lowers the watermarks as memory consumption drops. This allows free memory management to be proactive as well as adaptive.
Measuring Stalls
To measure the effect of changes targeting memory allocation stalls, a workload is needed that reliably causes stalls in a reasonable amount of time. A workload that performs a large number of I/O operations, modifies the filesystem at a high rate allocating a large number of pages of various orders and can result in large number of page cache pages that also have a short enough life to be reclaimed quickly was developed. This workload can help measure the effectiveness of the reclamation/compaction algorithm. The following mix of tasks was used to create the workload:
- dd 66GB of zero’s (from /dev/zero) to a file on one SSD. Run three such tasks at the same time.
- dd 131GB of zero’s (from /dev/zero) to a file on one SSD. Run three such tasks at the same time.
- dd 262GB of zero’s (from /dev/zero) to a file on one SSD. Run three such tasks at the same time.
- Run “make -j60 clean; make -j60 all” in a loop on a filesystem on another SSD.
This workload was run on a server with following specs:
-
Server: Oracle X7-2
-
CPU: Dual Intel(R) Xeon(R) Platinum 8160 CPU @ 2.10GHz, for total of 48 cores or 96 threads
-
Memory: 768GB
The following script launches the dd tasks and loops over these 3 times to smoothen out any jitter. /proc/vmstat provides stall information:
#!/bin/bash
cat /proc/vmstat | grep -i stall
echo "-----------------"
time for i in `seq 3`
do
for i in 1 2 3; do dd if=/dev/zero of=/mnt/d${i}/foo bs=4k count=64000000 & done
for i in 1 2 3; do dd if=/dev/zero of=/mnt/d${i}/foo2 bs=4k count=32000000 & done
for i in 1 2 3; do dd if=/dev/zero of=/mnt/d${i}/foo3 bs=4k count=16000000 & done
wait
done
echo "-----------------"
cat /proc/vmstat | grep -i stall
Another script launches kernel compile tasks in parallel in a loop to run continuously:
while true; do make -j60 clean; make -j60 all; done
This produces output like:
allocstall_dma 0 allocstall_dma32 0 allocstall_normal 0 allocstall_movable 0 compact_stall 0 ----------------- allocstall_dma 0 allocstall_dma32 0 allocstall_normal 418 allocstall_movable 2339 compact_stall 357
This shows 2757 allocation stalls and 357 compaction stalls for a total of 3114 stalls over the test run.
Impact Measurement
Using the test workload described above, test runs were made for kernel.org 5.10 kernel, UEK6, UEK5 and UEK4 kernels. Each set of test runs was done with and without adaptivemm running. While the improvements made to the reclamation algorithm in newer kernels have resulted in a reduction in the number of stalls, stalls still continue to be a negative impact on system performance. The total number of stalls are shown below:
The reduction in the number of stalls with adaptivemm adjusting watermarks proactively is significant for each kernel and that translates to higher workload performance.
References
[1]: https://lwn.net/Articles/594725/ Avoiding memory-allocation deadlocks