Address Space Isolation
In this blog post, Oracle Linux kernel developers Alexandre Chartre and Konrad Wilk give an update on the Spectre v1 and L1TF software solutions.
Introduction
In August of 2018 the L1TF speculative execution side channel vulnerabilities were presented (see Foreshadow – Next Generation (NG). However the story is more complicated. In particular, an explanation in L1TF – L1 Terminal Fault mentions that if hyper-threading is enabled, and the host is running an untrusted guest – there is a possibility of one thread snooping the other thread. Also the recent Microarchitectural Data Sampling, aka Fallout, aka RIDL, aka Zombieland demonstrated that there are more low-level hardware resources that are shared between hyperthreads.
Guests on Linux are treated the same way as any application in the host kernel, which means that the Completely Fair Scheduler (CFQ) does not distinguish whether guests should only run on specific threads of a core. Patches for core scheduling provide such a capability but, unfortunately, its performance is rather abysmal and as Linus mentions:
Because performance is all that matters. If performance is bad, then it’s pointless, since just turning off SMT is the answer.
However turning off SMT (hyperthreading) is not a luxury that everyone can afford. But then, with hyperthreading enabled, a malicious guest running on one hyperthread can snoop from the other hyperthread, if the host kernel is not hardened.
Details of data leak exploit
There are two pieces of exploitation technologies combined:
- Spectre v1 code gadgets – that is any code in the kernel that accesses user controlled memory under speculation
- A malicious guest which is executing the actual L1TF attack
In fact a Proof of Concept has been posted RFC x86/speculation: add L1 Terminal Fault / Foreshadow demo which does exactly that.
The reason this is possible is due to the fact that hyperthreads share CPU resources – and a well-timed attack can occur in between the time we exit in the hypervisor and go back to running the guest:
- Thread #0 performs an operation that requires the help of the hypervisor, such as cpuid.
- Thread #1 spins in its attack code without invoking the hypervisor.
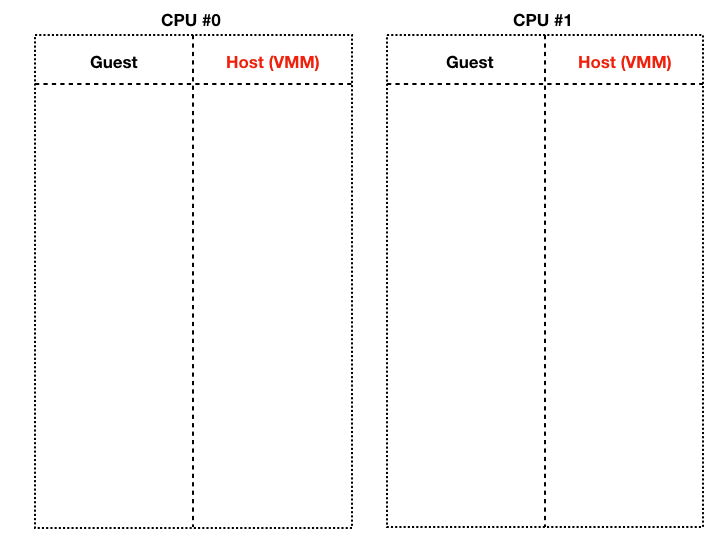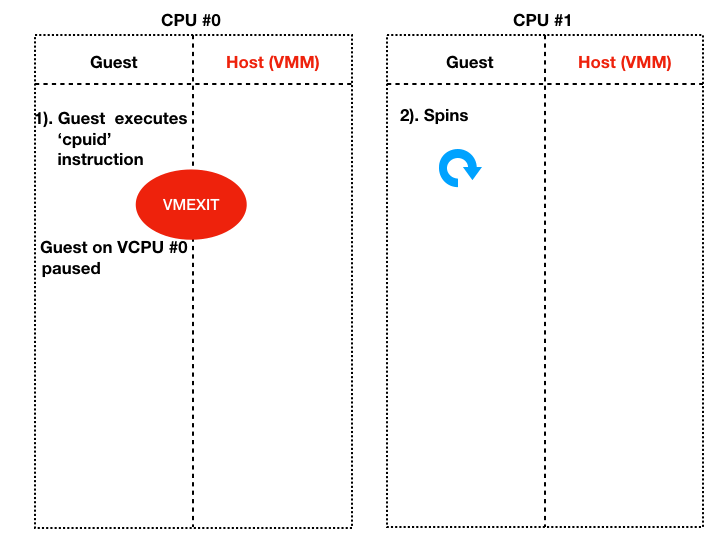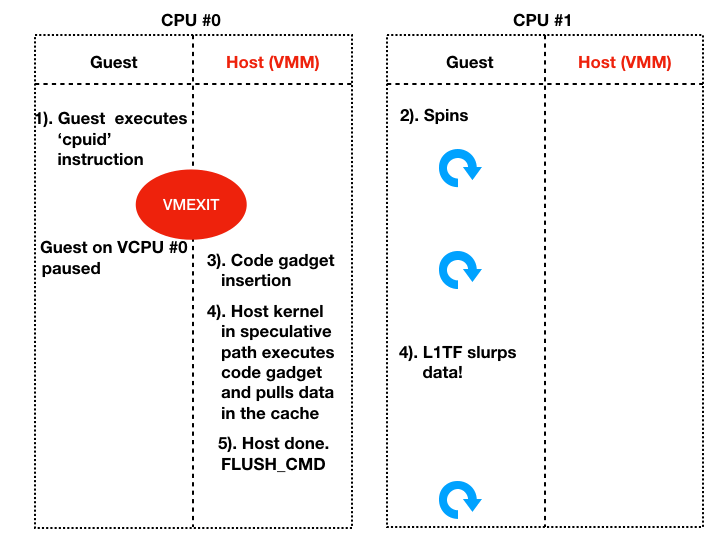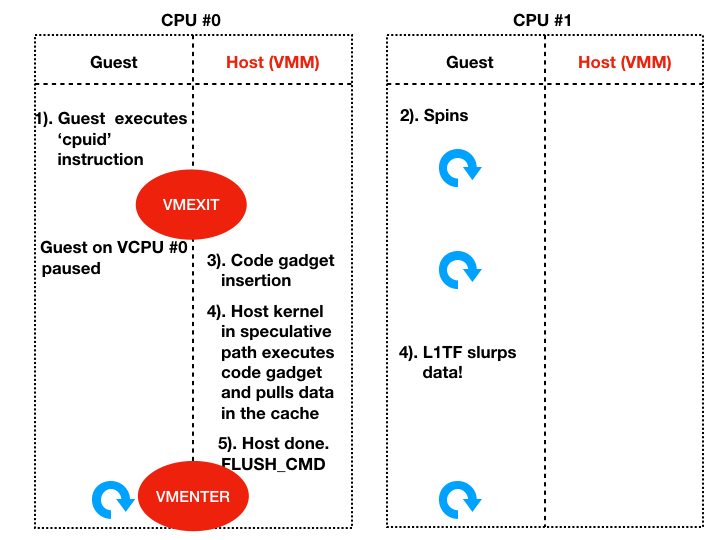
- Thread #0 pulls data in the cache using Spectre v1 code gadget.
- Thread #1 measure CPU resources to leak speculatively accessed data.
- Thread #0 flushes the cache and then resumes executing the guest.
This is how an attacker can leak the kernel data – using a combination of Spectre v1 code gadgets and using L1TF attack in the little VMEXIT windows that an guest can force.
Solutions
As mentioned disabling hyperthreading automatically solves the security problem, but that may not be a solution as it halves the capacity of a cluster of machines.
All the solutions revolve around the idea of allowing code gadgets to exist but they would either not be able to be execute in the speculative path, or they can execute – but are only be able to collect non-sensitive data.
The first solution that comes in mind is – can we inhibit the secondary thread from executing code gadgets. One naive approach is to simply always kick the other sibling whenever we enter the kernel (or hypervisor) and have the other sibling spin until we are done in a safe space.
Not surprisingly the performance was abysmal. Several other solutions that followed this path that have been proposed, including:
- Co-scheduling – modifying the scheduler to run tasks of the same group and on the same core executing simultaneously, whenever they are executed
- Core-scheduling – different implementation but the same effect.
Both of those follow the same pattern – lock-step enter the kernel (or hypervisor) when needed on both threads. This mitigates the Specte v1 issue by the guest or user space program not being able to leverage it – but it comes with unpleasant performance characteristics (on some workloads worst performance than turning hyperthreading off).
Another solution includes proactively patching the kernel for Spectre v1 code gadgets, along with meticulous nanny-sitting of the scheduler to never schedule one customer guests from sharing another customer siblings, and other low-level mitigations not explained in this blog.
However that solution also does not solve the problem of the host kernel being leaked using the Spectre v1 code gadgets and L1TF attack (see _Details of data leak exploit_ above). But what if just remove sensitive data from being mapped to that virtual address space to begin with? This would mean even if the code gadgets were found they would never be able to bridge the gap to the attacker controlled signal array.
eXclusive Page Frame Ownership (XPFO))
One idea that has been proposed in order to reduce sensitive data is to remove from kernel memory pages that solely belong to a userspace process and that the kernel don’t currently need to access.
This idea is implemented in a patch series called XPFO that can be found here: Add support for eXclusive Page Frame Ownership, earlier explained in 2016 Exclusive page-frame ownership and the original author’s patches Add support for eXclusive Page Frame Ownership (XPFO).
Unfortunately this solution does not help with protecting the hypervisor from having data leaked, just protects user space data. Which for guest to guest protection is enough – even if a naughty guest caused the hypervisor to speculatively execute Spectre v1 code gadgets along with spilling the hypervisor data using L1TF attack – the hypervisor at that point has only the naughty guest mapped on the core and not the other guest’s memory on the same core – so only hypervisor data is leaked and other guests’ vCPUs register data.
Only is not good enough – we want better security.
And if one digs in deeper there are also some other issue such as non trivial performance hit as a result of TLB flushes which make it slower than just disabling hyperthreading. Also if vhost is used then XPFO does not help at all as each guest vhost thread ends up mapping the guest memory in the kernel virtual address space and re-opening the can of worms.
Process-local memory allocations
Process-local memory allocations (v2) addresses this problem a bit differently – mainly that each process has a kernel virtual address space slot (local, or more of secret) in which the kernel can squirrel sensitive data on behalf of the process.
The patches focus only on one module (kvm) which would save guest vCPU registers in this secret area. Each guest is considered a separate process, which means that each guest is precluded from touching the other guest secret data. The “goal here is to make it harder for a random thread using cache load gadget (usually a bounds check of a system call argument plus array access suffices) to prefetch interesting data into the L1 cache and use L1TF to leak this data.”
However there are still issues – all of the guests memory is globally mapped inside the kernel. And the kernel memory itself can still be leaked in the guest.
This is similar to XPFO in that it is a black-list approach – we decide on specific items in the kernel virtual address space and remove them. And it fails short of what XPFO does (XPFO removes the guest memory from the kernel address space).
Combining XPFO with Process-local memory allocations would provide much better security than using them separately.
Address Space Isolation
Address Space Isolation is a new solution which isolates restricted/secret and non-secret code and data inside the kernel. This effectively introduces a firewall between sensitive and non-sensitive kernel data while retaining the performance (we hope).
This design is inspired by Microsoft Hyper-V HyperClear Mitigation for L1 Terminal Fault.
Liran Alon who sketched out the idea thought about this idea as follow:
-
The most naive approach to prevent the SMT attack vector is to force sibling hyperthreads to exit every time one hyperthread exits. But it introduce in-practical perf hit.
-
Therefore, next thought was to just remove what could be leaked to begin with. We assume that everything that could be leaked is something that is mapped into the virtual address space that the hyperthread is executing in after it exits to host. Because we assume that leakable CPU resources are only loaded with sensitive data from virtual address space. This is an important assumption.
-
Going forward with this assumption, we need techniques to remove sensitive information from host virtual address space.
-
XPFO and Kernel-Process-Local-Memory patch series goes with a black-list approach to remove explicitly specific parts of virtual address space which we consider to have sensitive information. The problem with this approach is that we are maybe missing here something and therefore a white-list approach is preferred.
At this point, after being inspired from Microsoft HyperClear, the KVM ASI came about.
The unique distinction about KVM ASI is that it creates a separate virtual address space for most of the exits to host that is built in a white-list approach: we only map the minimum information necessary to handle these exits and do not map sensitive information. Some exits may require more or sensitive information, and in those cases we kick the sibling hyperthreads and switch to the full address space.
Details of Address Space Isolation
QEMU and the KVM kernel module work together to manage a guest, and each guest is associated with a QEMU process. From userspace, QEMU uses the KVM_RUN ioctl (#1 and #2) to request KVM to run the VM (#3) from the kernel using Intel Virtual Machine Extensions (VMX). When an event causes the VM to return (VM-Exit, step #4) to KVM, KVM handles the VM-Exit (#5) and then transfer control to the VM again (VM-Enter). See below:
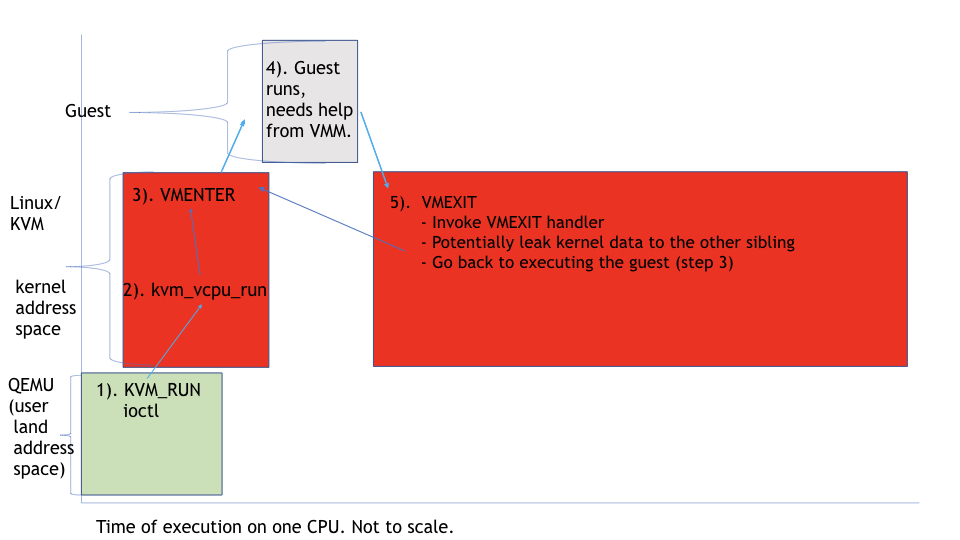
However, most of the KVM VM-Exit handlers only need to access per-VM structures and KVM/vmlinux code and data that is not sensitive. Therefore, these KVM VM-Exit handlers can be run in an address space different from the standard kernel address space. So, we can define a KVM address space, separated from the kernel address space, which only needs to map the code and data required for running these KVM VM-Exit handlers (#5 see below). This provides a white-list approach of exactly what could be leaked while running the KVM VM-Exit code (in the picture below it is yellowish).
When the KVM VM-Exit (#5a see below) code reaches a point where it does architecturally need to access sensitive data (and therefore not mapped in this isolated virtual address space), then it will kick all sibling hyperthreads outside of guest and switch to the full kernel address space. This kicking guarantees that there is no untrusted guest code running on sibling hyperthreads while KVM is bringing data into the L1 cache with the full kernel address space mapped. This overall operation happens, for example, when KVM needs to return to QEMU or the host needs to run an interrupt handler.
Note that KVM flushes the L1 cache before VM-Enter back to running guest code to ensure nothing is leaked via the L1 cache back to the guest.

In effect, we have made the KVM module a less privileged kernel module. That has three fantastic side-effects:
-
The guest already knows about guest data on which KVM operates most of the time so if it is leaked to the guest that is okay.
-
If the attacker does exploit a code gadget, it will only be able to run on the KVM module address space, not outside of it.
-
Nice side-affect of ASI is that it can also assist against ROP exploitation and architectural (not speculative) info-leak vulnerabilities because much less information is mapped in the exit handler virtual address space.`
If the KVM module needs to access restricted data or routines, it needs to switch to the full kernel page-table, and also bring the other sibling back to the kernel so that the other thread will be unable to insert code gadgets and slurp data in.
Show me the code?!
The first version, posted back in May, RFC KVM 00/27 KVM Address Space Isolation received many responses from the community.
These patches – RFC v2 00/27 Kernel Address Space Isolation posted by Alexandre Chartre are the second step in this. The patches are posted as a Request For Comments which solicits guidance from the the Linux Kernel community on how they would like this to be done. The framework is more generic with the first user being KVM but could very well be extended to other modules
Thanks
We would like also to thank the following folks for help with this article:
- Mark Kanda
- Darren Kenny
- Liran Alon
- Bhavesh Davda