Load balancing via scalable task stealing
Oracle Linux kernel developer Steve Sistare contributes this discussion on kernel scheduler improvements.
The Linux task scheduler balances load across a system by pushing waking tasks to idle CPUs, and by pulling tasks from busy CPUs when a CPU becomes idle. Efficient scaling is a challenge on both the push and pull sides on large systems. For pulls, the scheduler searches all CPUs in successively larger domains until an overloaded CPU is found, and pulls a task from the busiest group. This is very expensive, costing 10’s to 100’s of microseconds on large systems, so search time is limited by the average idle time, and some domains are not searched. Balance is not always achieved, and idle CPUs go unused.
I have implemented an alternate mechanism that is invoked after the existing search in idle_balance() limits itself and finds nothing. I maintain a bitmap of overloaded CPUs, where a CPU sets its bit when its runnable CFS task count exceeds 1. The bitmap is sparse, with a limited number of significant bits per cacheline. This reduces cache contention when many threads concurrently set, clear, and visit elements. There is a bitmap per last-level cache. When a CPU becomes idle, it searches the bitmap to find the first overloaded CPU with a migratable task, and steals it. This simple stealing yields a higher CPU utilization than idle_balance() alone, because the search is cheap, costing 1 to 2 microseconds, so it may be called every time the CPU is about to go idle. Stealing does not offload the globally busiest queue, but it is much better than running nothing at all.
Results
Stealing improves utilization with only a modest CPU overhead in scheduler code. In the following experiment, hackbench is run with varying numbers of groups (40 tasks per group), and the delta in /proc/schedstat is shown for each run, averaged per CPU, augmented with these non-standard stats:
- %find – percent of time spent in old and new functions that search for idle CPUs and tasks to steal and set the overloaded CPUs bitmap.
- steal – number of times a task is stolen from another CPU.
X6-2: 1 socket * 10 cores * 2 hyperthreads = 20 CPUs
Intel(R) Xeon(R) CPU E5-2630 v4 @ 2.20GHz
hackbench
process 100000
sched_wakeup_granularity_ns=15000000
baseline
grps time %busy slice sched idle wake %find steal
1 8.084 75.02 0.10 105476 46291 59183 0.31 0
2 13.892 85.33 0.10 190225 70958 119264 0.45 0
3 19.668 89.04 0.10 263896 87047 176850 0.49 0
4 25.279 91.28 0.10 322171 94691 227474 0.51 0
8 47.832 94.86 0.09 630636 144141 486322 0.56 0
new
grps time %busy slice sched idle wake %find steal %speedup
1 5.938 96.80 0.24 31255 7190 24061 0.63 7433 36.1
2 11.491 99.23 0.16 74097 4578 69512 0.84 19463 20.9
3 16.987 99.66 0.15 115824 1985 113826 0.77 24707 15.8
4 22.504 99.80 0.14 167188 2385 164786 0.75 29353 12.3
8 44.441 99.86 0.11 389153 1616 387401 0.67 38190 7.6
|
Elapsed time improves by 8 to 36%, costing at most 0.4% more find time. CPU busy utilization is close to 100% for the new kernel, as shown by the green curve in the following graph, versus the orange curve for the baseline kernel:
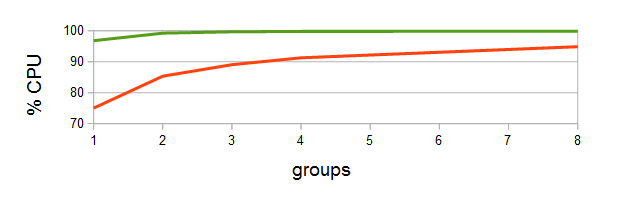
Stealing improves Oracle database OLTP performance by up to 9% depending on load, and we have seen some nice improvements for mysql, pgsql, gcc, java, and networking. In general, stealing is most helpful for workloads with a high context switch rate.
The code
As of this writing, this work is not yet upstream, but the latest patch series is at https://lkml.org/lkml/2018/12/6/1253. If your kernel is built with CONFIG_SCHED_DEBUG=y, you can verify that it contains the stealing optimization using
# grep -q STEAL /sys/kernel/debug/sched_features && echo Yes
Yes
If you try it, note that stealing is disabled for systems with more than 2 NUMA nodes, because hackbench regresses on such systems, as I explain in https://lkml.org/lkml/2018/12/6/1250 . However, I suspect this effect is specific to hackbench and that stealing will help other workloads on many-node systems. To try it, reboot with kernel parameter sched_steal_node_limit = 8 (or larger).
Future work
After the basic stealing algorithm is pushed upstream, I am considering the following enhancements:
- If stealing within the last-level cache does not find a candidate, steal across LLC’s and NUMA nodes.
- Maintain a sparse bitmap to identify stealing candidates in the RT scheduling class. Currently pull_rt_task() searches all run queues.
- Remove the core and socket levels from idle_balance(), as stealing handles those levels. Remove idle_balance() entirely when stealing across LLC is supported.
- Maintain a bitmap to identify idle cores and idle CPUs, for push balancing.