See how I/O drives much of the efficiency of JEP 444’s thread revolution.
Virtual threads, as implemented in JEP 444, are arguably the most anticipated feature of Java 21. This article brings together several technical topics that Java Magazine has previously discussed on the subject of threading, in particular the relationship and interaction between the following:
- Java I/O
- The operating system and the Java thread bottleneck
- Virtual threads
This journey will explain not only how virtual threads work but also why they work.
Starting with Java I/O
You may have already met the traditional form of Java I/O in “Modern file input/output with Java Path API and Files helper methods” and the modern form (the Path API) in “Modern file input/output with Java: Let’s get practical” as well as native I/O in “Modern file input/output with Java: Going fast with NIO and NIO.2.” If you haven’t already read those articles, you might want to give them a glance; but if you don’t, that’s OK too.
Still, take a moment to think about the difference between the forms of I/O. Start with blocking I/O, which has the advantage of being conceptually simple. For example, the Socket class exposes methods such as getInputStream(), which allows you to write code such as the following single-threaded user code that reads (one line at a time) from the socket and prints the data, in a blocking manner:
try (var sock = new Socket(hostname, port);
var from = new BufferedReader(
new InputStreamReader(sock.getInputStream()))) {
for (String l = null; (l = from.readLine()) != null; ) {
System.out.println(l);
}
}
Note that if the InputStream returned from getInputStream() was backed by a channel in nonblocking mode, the input stream’s read operations would throw a java.nio.channels.IllegalBlockingModeException—in other words, this stream must be in blocking mode.
The blocking nature of the read calls bubbles up through the decorating classes, InputStreamReader and BufferedReader, which provide a much more useful interface for humans than the low-level socket reads. However, this simplicity comes with potential downsides.
- You must read the data from the file and bring it into the Java heap as objects (one String object per line).
- The thread will be unable to do anything else until the file operation finishes.
You can fix the first of these problems by using the Channels API (part of Java’s NIO library) to read the file contents into a memory buffer that is not part of the Java heap, as follows:
var file = Path.of("/Users/bje/reasonable.txt");
try (var channel = FileChannel.open(file)) {
var buffer = ByteBuffer.allocateDirect(1_000_000);
var bytesRead = channel.read(buffer);
System.out.println("Bytes read [" + bytesRead + "]");
BusinessProcess.doSomethingWithFile(buffer);
} catch (IOException e) {
e.printStackTrace();
}
However, this code is still blocking, and you need to do something more elaborate to solve that issue. One possibility is to use the nonblocking asynchronous I/O classes from NIO.2; with those, I/O calls return immediately regardless of whether the I/O operation has finished or not.
An object is returned to the caller, and that object represents the result of the asynchronous operation. Typically, the result is still pending and will be fully materialized only after the operation has been completed.
A simple example, which reads up to 100 megabytes from a file, and then gets the result (which will be the number of bytes actually read), might look like the following:
var file = Path.of("/Users/bje/enormous.txt");
try (var channel = AsynchronousFileChannel.open(file)) {
var buffer = ByteBuffer.allocateDirect(100_000_000);
Future<Integer> result = channel.read(buffer, 0);
while (!result.isDone()) {
BusinessProcess.doSomethingElse();
}
var bytesRead = result.get();
System.out.println("Bytes read [" + bytesRead + "]");
BusinessProcess.doSomethingWithFile(buffer);
} catch (IOException | ExecutionException | InterruptedException e) {
e.printStackTrace();
}
Note that the return type from read() is Future<Integer>, which is a container type that can hold either an incomplete or completed result. (Java’s Future objects are quite similar to promises in JavaScript.)
The fact that read() returns immediately while the actual copying of the file into memory happens on another thread (and is handled automatically by the runtime) allows this single-threaded user code to do something else while you’re waiting for the long-running copy to be completed.
You can use periodic checks (using the isDone() method) and then call the get() method to retrieve the results when the asynchronous I/O activity has been completed.
This is obviously more complicated than the blocking case, as it requires you to think about the asynchronous aspects. In particular, the program must be structured in such a way that tasks unrelated to the data—such as doSomethingElse() in the example above—can be performed while the I/O operation is underway.
Another, more subtle, aspect is that despite the similarity of their names, AsynchronousFileChannel and FileChannel are almost entirely unrelated classes. In fact, the only common inheritance they have is that both classes implement java.nio.channels.Channel, which only has two methods.
public interface Channel extends Closeable {
public boolean isOpen();
public void close() throws IOException;
}
Notably missing from this definition are the read methods, which have different signatures in the two classes.
// FileChannel public abstract int read(ByteBuffer dst) throws IOException; // AsynchronousFileChannel public abstract Future<Integer> read(ByteBuffer dst, long position);
This difference between the two classes is designed to emphasize, rather than hide, the different nature of the calls. This was a conscious and deliberate choice on the part of the Java language designers.
Other approaches
In case you are curious, some other programming languages, such as C#, have adopted an async-await approach to nonblocking I/O, which attempts to provide a flexible and general way to turn normal single-threaded blocking code into an asynchronous, nonblocking version.
Note the following about the C# version of this approach:
- The
asynckeyword turns a method into an asynchronous method, referred to as an async method. - When execution reaches a method call decorated with the
awaitkeyword, the calling method is suspended and yields the thread back to its caller method. - The
awaitkeyword can be used only inside a method marked withasync; attempting to do otherwise causes a compilation error.
The async-await approach is achieved by the compiler automatically converting the async method into a state machine.
Similarly, Kotlin’s coroutines are based on essentially the same idea, which is to use special keywords to indicate that the compiler should construct a state machine, as explained in this book.
Incomplete results also need to be represented in the case of an async task that returns a value. In Kotlin this role is performed by instances of the type Deferred<T>, whereas in C# they’re of the type Task<TResult>.
This pattern, sometimes referred to as the task-based asynchronous pattern (TAP), offers flexibility and generality. However, it has some drawbacks—the main one being the extra complexity—that led the Java language designers to explore a different path than simply adding a state machine–based async-await approach to the language.
The whole point of the pattern is to try to hide the difference between synchronous and asynchronous calls, but in practice this is difficult to achieve. For starters, the return type of a synchronous method must be boxed into a container type similar to a Future to allow the incomplete state to be represented.
In languages that support the async-await approach, the source code compiler must, therefore, add in code to automatically box and unbox results. This can combine badly with type inference, where the actual return type can differ from what’s expected.
A more serious issue is that when synchronous code is converted to an asynchronous form, you’ll often find that the code works better if the asynchronous code both calls and is called by other asynchronous code. This can lead to larger and larger parts of the codebase becoming asynchronous, which in turn makes it more difficult to reason about the code.
This is sometimes known as asynchronous contagion or colored functions, named as such in the 2015 blog post “What Color is Your Function.” By the way, the author of that post, Bob Nystrom, incorrectly predicted that Java was planning to support the async-await approach.
Back to Java
Observing the experience of programmers using the async-await approach in other languages led the Java language team to conclude that it was not the right direction for Java, so they explored other options. As you might guess, Java’s eventual solution to the problem is (spoiler alert) virtual threads.
However, before tackling that subject, there is one more aspect of blocking versus nonblocking I/O to consider.
Java’s traditional I/O API was originally blocking, but Java 13’s JEP 353, which reimplemented the legacy Socket API, and Java 15’s JEP 373, which reimplemented the legacy DatagramSocket API, changed all that.
Note that because of when those two JEPs were delivered, if your applications are running on Java 17 (or the latest feature release), you are already using these enhancements. On the other hand, if your applications are still based on Java 8 or Java 11, you aren’t using those enhancements.
The original socket implementation was based on the nonpublic PlainSocketImpl class with support from SocketInputStream and SocketOutputStream. The new implementation relies on the new NioSocketImpl class, which merges the implementation of socket code with native I/O.
This means that, although the blocking API is maintained for the programmer, under the covers, nonblocking I/O is being used. But why does this matter, and how does it relate to virtual threads? There’s a story to be told.
Operating systems and the thread bottleneck
Java version 1.0, which first appeared in 1995, was the first mainstream programming platform to include threads in the core language. Before threads existed, to perform multiprocessing, programming languages had to use multiple processes and various mechanisms to pass data around.
From the point of view of the operating system, threads are independent execution units that belong to a process. Each thread has an execution instruction counter and a call stack but shares a heap with every other thread in the same process.
Threads are scheduled and managed by the OS. To change which execution units are running, a context switch is performed. Because they share the same heap, it is cheaper to switch between two threads in the same process than between two threads in different processes. This leads to a lightweight context switch.
Threads represent a significant performance improvement (especially for throughput), because all the data that needs to be communicated stays in memory and within the same process heap. However, the involvement of the OS in the management of threads causes some scalability problems that are not easy to resolve.
The key to understanding this issue is that when the OS creates a thread, it allocates a stack segment, which is a fixed amount of memory that is reserved by the OS within the process virtual address space for each thread. The memory is reserved when a thread is created, and it is not reclaimed until the thread exits.
For JVM processes running on Linux x64, the default stack size is 1 MB, and this space is reserved by the OS each time you launch a new thread. This makes the math pretty simple. For example, 2,000 threads means that 20 GB of stack space needs to be reserved.
You can see that this creates a massive discrepancy between the number of objects a Java program can create (millions or even billions) and the possible number of platform threads the OS can create and manage, largely due to the stack space requirements. Effectively, the stack space requirement imposes a limit on the number of threads in a process, which is referred to as the thread bottleneck.
By the way, the thread bottleneck is in no way specific to Java: The stack space requirement comes from the OS, and all programming environments are subject to it. No matter the language, this bottleneck is an increasingly serious problem because modern server processes (whether written in Java or another programming language) need to manage a much larger number of in-flight execution contexts than they did historically.
This leads to a tension between using threads in the simplest and most natural way—where every thread performs one sequential task—and the constraints that the OS and platform impose on the number of threads. Because of the stack space requirements, the idea of creating a new platform thread to handle each incoming request is not feasible, especially if you want the application to scale.
Enter virtual threads
Java’s solution to this problem, which allows you to increase thread density while keeping the code simple, is virtual threads provided by Project Loom.
Project Loom was discussed in the article “Coming to Java 19: Virtual threads and platform threads” and (in a much earlier form of the project, which may not be strictly accurate compared to what was actually delivered) in “Going inside Java’s Project Loom and virtual threads.” You can read the description of virtual threads in those articles, but for the sake of completeness, here’s a short discussion of this new language feature.
The following are the two main aspects of virtual threads that are different compared to platform threads:
- To remove the role of the OS in creating and managing virtual threads
- To replace the static allocation of thread segments with a more flexible model
In both cases, the JVM runtime takes over the role normally played by the OS for platform threads.
The first point is that virtual threads are simply runnable Java objects. They require a platform thread (known as a carrier thread in the context of virtual threads) to run upon, but these platform threads are shared. This removes the 1:1 relationship between Java threads and OS threads, and it instead establishes a temporary association of a virtual thread to a carrier thread—but only while the virtual thread is executing.
The second point is that virtual threads use Java objects within the garbage-collected heap to represent stack frames. This is much more dynamic and removes the static bottleneck caused by stack segment reservation.
Taken together, this means that the number of virtual threads can theoretically scale in a similar manner to the number of Java objects.
Virtual threads and I/O
Removing the thread bottleneck is a great achievement, but at this point, you may still be wondering how virtual threads connect with I/O handling and the initial discussion in this article.
Look at the state model for a platform thread in Figure 1. In this model, the OS scheduler moves platform threads on and off the core (that is, it performs the context switches).
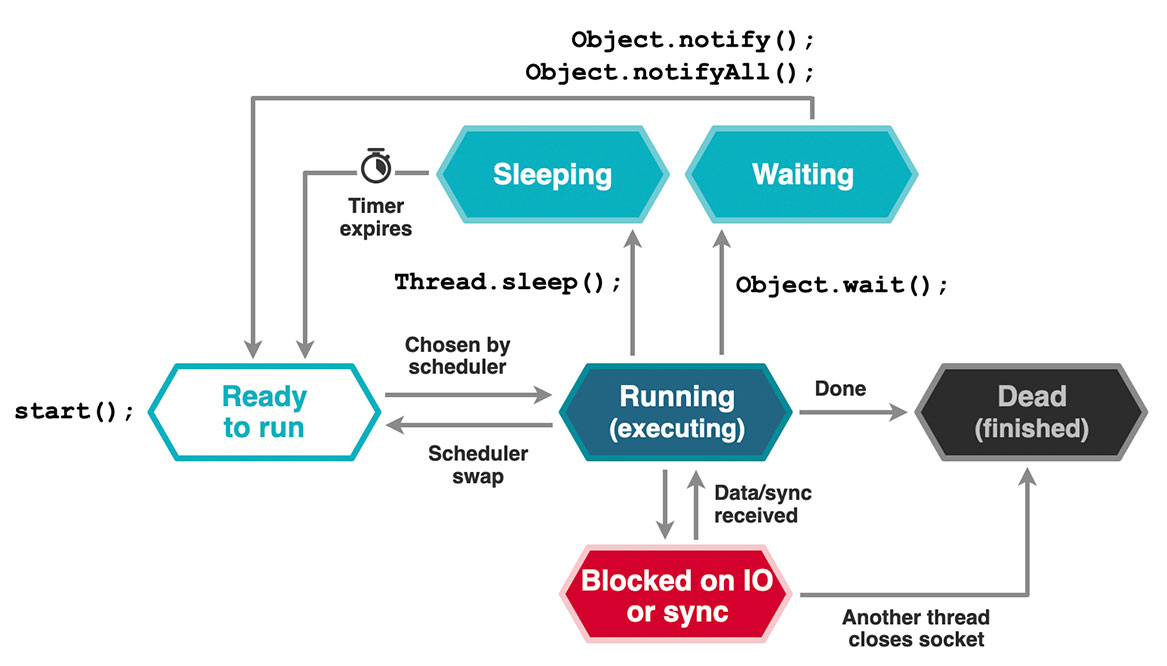
Figure 1. Platform thread states
There are several ways in which a platform thread can leave the core.
- The thread can exit—but this case is not very interesting.
- The thread can pause voluntarily and temporarily (yield) and give up its remaining currently allocated time. It can do so either for a fixed amount of time, via
Thread.sleep(), or until a condition is met, viaObject.wait(). - The thread can run without encountering any blocking calls to the standard library or any sleep or wait instructions. In this case, at the end of the thread’s allocated time (sometimes called a time quantum), the scheduler moves the thread to the back of the run queue to wait until it reaches the front of the queue and is eligible to run again. (The time quantum is usually 10 milliseconds—or 100 milliseconds in older operating systems.) However, apart from compute-bound tasks, this case is not seen that often in practice.
- The thread can encounter a blocking call, for example, an I/O operation. That is how I/O connects with virtual threads.
How are these conditions handled? The introduction of virtual threads means that not all threads are scheduled by the OS—only platform threads are. Therefore, virtual threads do not appear as schedulable entities to the OS. Instead, the JVM now has an additional, VM-level scheduler that is responsible for controlling access to the shared carrier threads.
Those carrier threads belong to a thread pool, specifically a ForkJoinPool executor. (Note that this thread pool is different from the shared common pool used for parallel streams.)
If a thread encounters a blocking call, it proceeds normally if it is a platform thread. However, if it is a virtual thread (and is, therefore, temporarily mounted on a carrier thread), the runtime simply dispatches the I/O operation and then yields, unmounting the virtual thread from the carrier.
Remember that I/O is now done in a nonblocking fashion by the runtime, per JEP 353 and JEP 373, in Java 15 and later. Therefore, the carrier is now free to mount a different virtual thread and continue executing, while the blocking I/O from the first virtual thread proceeds in the background.
The VM-level scheduler will not reschedule the blocked virtual thread until the I/O operation has been completed and there is data to retrieve.
Today, most of the common blocking operations have been retrofitted to support virtual threads. However, some operations, such as Object.wait(), are not yet supported and instead capture the carrier thread. In this case, the thread pool responds by temporarily increasing the number of platform threads in the pool to compensate for the captured thread.
In addition to captured threads, there is also the possibility of pinned threads. This occurs when a virtual thread executes a native method or encounters synchronized code. In this case, the virtual thread is not unmounted; instead, it retains ownership of the carrier thread. The thread pool does not create an additional thread, and the effective size of the thread pool is reduced for the duration of the pin.
What all this means
Virtual threads are an enhancement to the JVM. This facility is fundamentally different to the async-await approach adopted by Kotlin, C#, and other languages.
In particular, there is no real fingerprint of virtual threads in the bytecode, because virtual threads are just threads, and the handling of them is part of the platform (that is, the JVM), not the user code.
The aim of virtual threads is to allow Java programmers to write code in the traditional thread-sequential style they are already used to. Once virtual threads have become mainstream, there should be no need to explicitly manage yielding or to use nonblocking, callback-based or reactive operations in user code.
There are other benefits as well, such as allowing debuggers and profilers to work in the same way with virtual threads as they do with traditional threads. Of course, this means there’s extra work for toolmakers and library designers to do to support virtual threads.
However, in general, the Java environment tries to reduce the cognitive burden on end user Java developers and shift that complexity into the platform and libraries. In that sense, the design of virtual threads is a classic Java trade-off.
Getting started with virtual threads
The inheritance hierarchy of Thread has been enhanced by the arrival of virtual threads, as you can see in Figure 2.
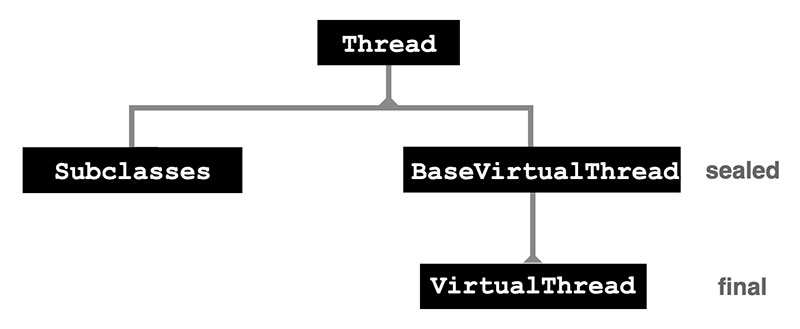
Figure 2. The thread hierarchy
Note that the class VirtualThread is explicitly declared as final and cannot be subclassed. Therefore, any existing class that extends Thread directly will be a platform thread. This is part of the principle that the arrival of virtual threads must not change the semantics of any existing Java code.
Thread builders are another important new feature of virtual threads: The VirtualThread class is nonpublic, and there must be some way for a developer to create virtual threads. Therefore, new static factory methods have been added to Thread to produce builder objects, as shown below.
jshell> var tb = Thread.ofVirtual() // or .ofPlatform() tb ==> java.lang.ThreadBuilders$VirtualThreadBuilder@b1bc7ed
Builders can set a name and a Runnable task.
jshell> var t = tb.name("MyThread").unstarted(() -> System.out.println("Virtual World"))
t ==> VirtualThread[#24,MyThread]/new
This creates the Thread in the NEW state, so that it can be started in the usual way. You can also create and immediately start the thread by calling start() directly on the builder object. Note the slightly different .toString() output that virtual threads produce.
Thread factories are also available from builders.
jshell> var tf = tb.factory() tf ==> java.lang.ThreadBuilders$VirtualThreadFactory@c4437c4
These factories can then be used just like any other thread factory that you may have encountered when working with platform threads.
Virtual thread guidelines
Virtual threads have been designed to be as similar to existing threads as possible, but there are some key differences. Here are some guidelines to keep in mind as you start adopting virtual threads in your own Java applications.
- Check the date of any articles, on Java Magazine or elsewhere, that discuss virtual threads, because a lot has changed from the various preview versions.
- Don’t think of virtual threads as a free lunch.
- Learn what types of problems virtual threads can help with.
- Don’t use virtual threads for compute-bound tasks because they need blocking calls to yield automatically.
- Expect to learn some new intuitions and patterns for virtual threads.
- Don’t use synchronized blocks or call synchronized methods from virtual threads.
- Don’t use
Thread.yield()for virtual threads; it works but using it is discouraged.
To learn all this will take time, and the Java community needs to adjust to virtual threads.
In particular, the choice between virtual threads and platform threads for any specific task is an important design activity. The programmer must decide whether a given task is compute-bound (and so should be handled by a platform thread) or whether it is fundamentally a task centered around I/O (and is, therefore, well-suited for a virtual thread).
Conclusion
As of Java 21 (available in September 2023), virtual threads will be available as a standard, final feature. How much direct usage of virtual threads there will be—as opposed to virtual threads being primarily used by libraries and frameworks—remains to be seen.
However, the continued evolution of Java’s concurrency—which virtual threads represent—is a sign of the platform’s overall vitality and longevity.
Dig deeper
- JEP 444: Virtual threads
- Java 21
- Coming to Java 19: Virtual threads and platform threads
- Going inside Java’s Project Loom and virtual threads
- Java’s evolution into 2022: The state of the four big initiatives
- Amber, Lambda, Loom, Panama, Valhalla: The major named Java projects
- The promise of using Java virtual threads with Oracle WebLogic Server