Accessibility Policy
Skip to content
Oracle
Oracle Integration
Search
Exit Search Field
Clear Search Field
Menu
Blogs Home
RSS
Oracle Integration
Follow:
RSS
Facebook
Twitter
LinkedIn
YouTube
Instagram
3
GoldenGate & Oracle Integration Workshops – June & July ...
Jürgen Kress
1 minute read
Accelerating Enterprise Automation using Agentic AI in Oracle ...
Biman Sarkar
Prakash Masand
Venkat Chowdhury
11 minute read
Bringing OCI Generative AI Models to Oracle Integration Agentic AI
Steve Tindall
5 minute read
Search Oracle Blogs
Search this site
Type your search term and press Enter.
Subscribe to the integration newsletter
Stay connected
Recent Posts
Intelligent Document Processing with AI Agents and Oracle 26ai RAG ...
Ganesh Babu GM
10 minute read
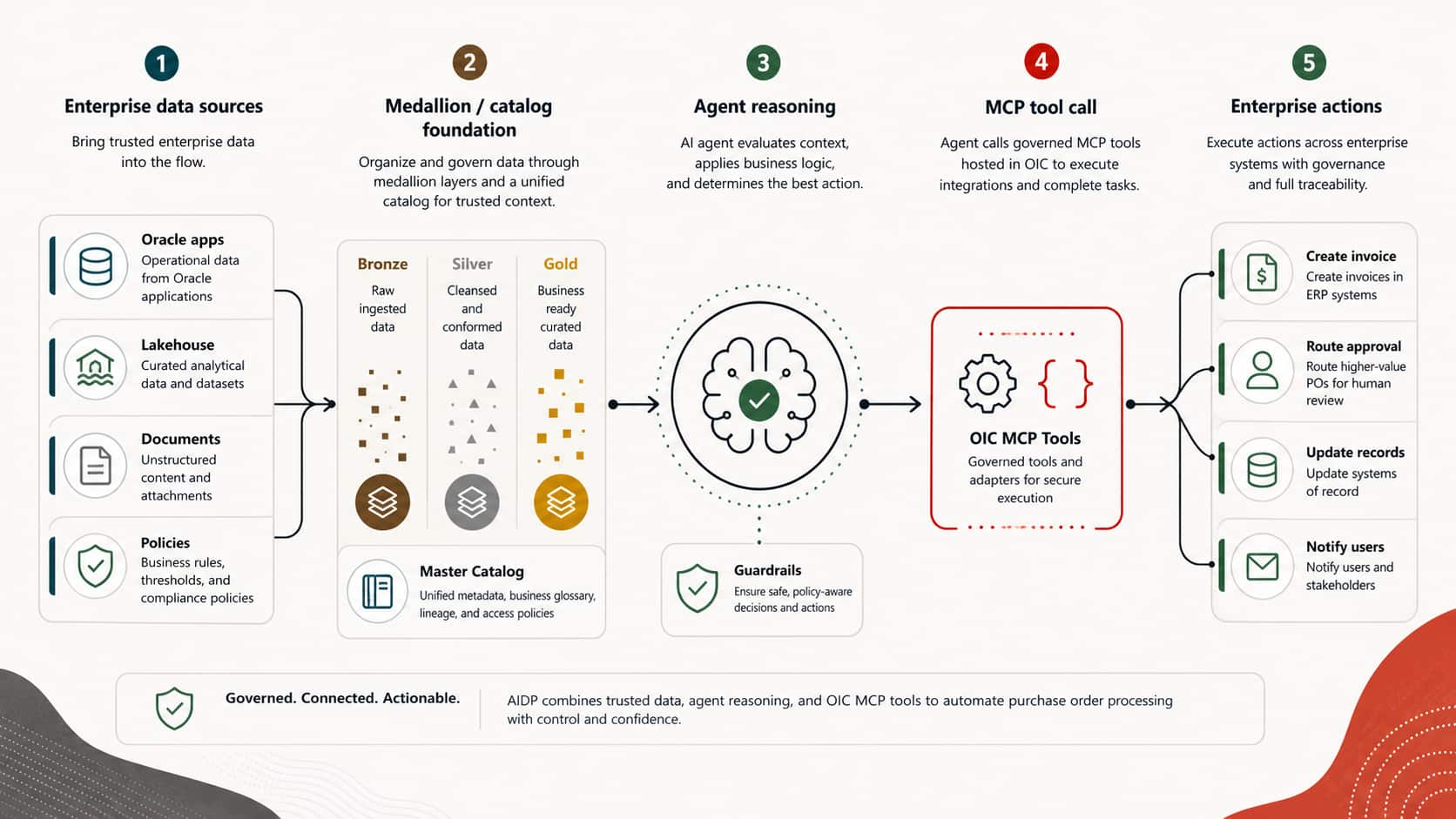
Connecting Oracle AI Data Platform Agent Flows to OIC MCP Tools for ...
Sandhya Lakshmi Gopalan
14 minute read
From Headset to ATP: How OIC Turns Support Calls into Searchable ...
Biman Sarkar
8 minute read
New Adapters and Connectivity Enhancements in Oracle Integration 26.07
Madhav Poosarla
13 minute read
What’s New in Oracle Integration 26.07
Niall Commiskey
5 minute read
Action Required: Retirement of SAP SuccessFactors Basic ...
Madhav Poosarla
3 minute read
Action Required – Migrate Salesforce Adapter Resource Owner Password ...
Madhav Poosarla
2 minute read
Processing Comma-Separated Lookup Values in Oracle Integration Cloud ...
Devkiran Tomar
4 minute read
Oracle Integration Customer Success Webcast May 2026: Unlocking HCM ...
Ravi Chablani
2 minute read
Oracle Integration Enters the Age of AI — Product Update Webcast June ...
Jürgen Kress
1 minute read
Powering the Employee Onboarding Experience with OIC AI Agent and ...
Kishore Katta
9 minute read
How Equinix is Redefining Enterprise Integrations with Agentic AI in ...
Pradyumna Kodgi
8 minute read
View more
Subscribe to the integration newsletter
Stay connected
Resources for
About
Careers
Developers
Investors
Partners
Startups
Why Oracle
Analyst Reports
Best CRM
Cloud Economics
Corporate Responsibility
Security Practices
Learn
What is Customer Service?
What is ERP?
What is Marketing Automation?
What is Procurement?
What is Talent Management?
What is VM?
What's New
Try Oracle Cloud Free Tier
Oracle Sustainability
Oracle COVID-19 Response
Oracle and SailGP
Oracle and Premier League
Oracle and Red Bull Racing Honda
Contact Us
US Sales 1.800.633.0738
How can we help?
Subscribe to Oracle Content
Try Oracle Cloud Free Tier
Events
News
© 2026 Oracle
Privacy
/
Do Not Sell My Info
Ad Choices
Careers