After I posted last weeks blog post on identifying analytic queries that benefit from Database In-Memory, I got the following question, “Why didn’t Database In-Memory improve the performance of my query?”
I’ve simplified the query in question down to the following,
SELECT Count(DISTINCT cust_id)
FROM ssh.sales
WHERE amount_sold > 1;
So, why didn’t Database In-Memory improve the performance of this query?
The answer is becomes a little clearer if you look at the SQL Monitor report for the query. Even with the SALES table fully populated into the In-Memory column store (IM column store), the query is completely bottlenecked on the aggregation / sorting step.
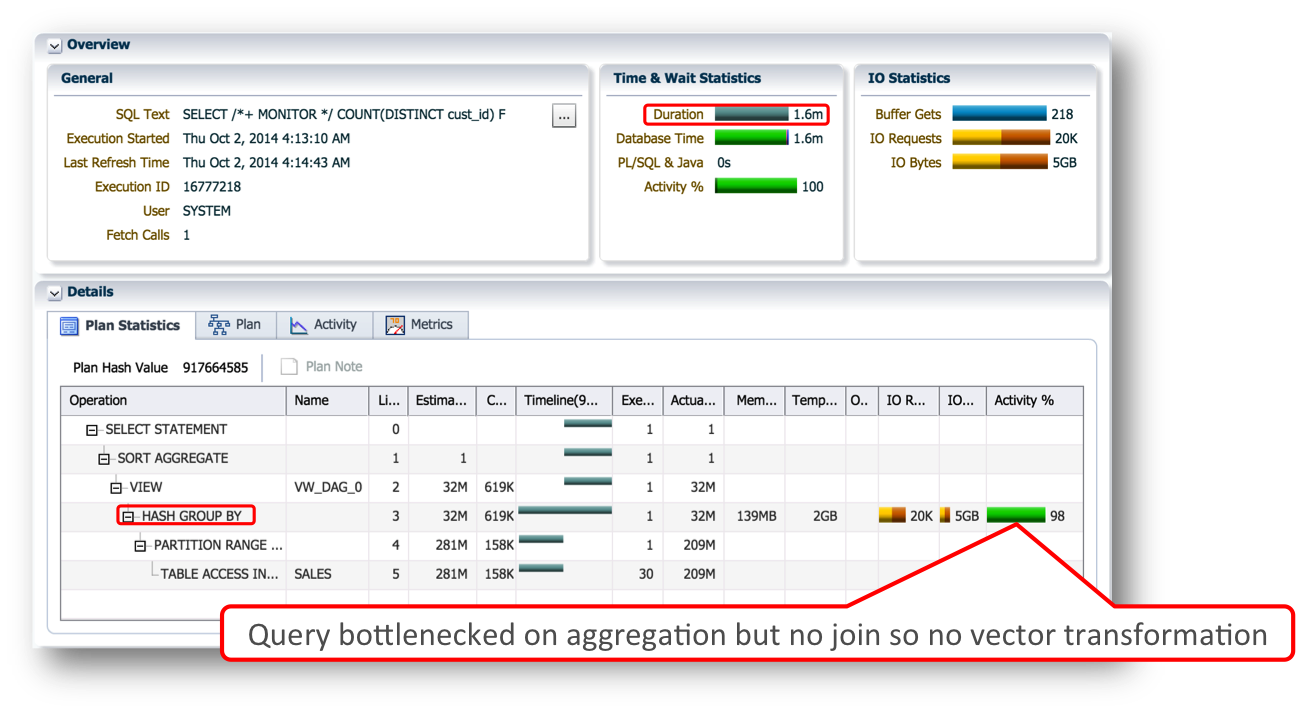
Since there is only one table involved in the query In-Memory Aggregation or Vector Transformation won’t kick in, as it needs a join to be present.
So, what can we do to speed up this query?
One option open to us in Oracle Database 12c is to replace the COUNT DISTINCT with the new APPROX_COUNT_DISTINCT function.
The APPROX_COUNT_DISTINCT function uses a HyperLogLog algorithm, which enables the processing of large amounts of data significantly faster than a COUNT DISTINCT, with negligible deviation from the exact result.
This technique was originally designed to improve the performance of statistics gathering and is used by the DBMS_STATS package to calculate the number of distinct values in a column when the ESTIMATE_PERCENT parameter is set to AUTO_SAMPLE_SIZE (the default) from 11g onwards.
There are in fact many real-world use cases where an approximate answer is good enough. For example ‘how many distinct visitors came to our website last month?’ it may not be necessary in this case to have a precise answer. An approximate answer that is for example within 1% of the actual value would be sufficient.
Luckily for me that was the case here and we were able to replace the COUNT DISTINCT with new APPROX_COUNT_DISTINCT function.
SELECT Approx_count_distinct(cust_id)
FROM ssh.sales
WHERE amount_sold > 1;
So, just how much faster would it be?
Let’s take a look at the SQL Monitor report.

By replacing the COUNT DISTINCT with new APPROX_COUNT_DISTINCT
function the query is no longer bottlenecked on the aggregation /
sorting step and we were able to improve the performance by a factor of
4X.
What about the actual query results?

In this case the difference between the COUNT DISTINCT and the APPROX_COUNT_DISTINCT function was negligible (3%).
However, given that this is an approximation (be it a very good one) it may not always be possible to replace every COUNT DISTINCT with the new APPROX_COUNT_DISTINCT function. For example, financial period close calculations couldn’t be modified to use this, but it can certainly help improve the performance of a lot of workloads, especially if it’s used in conjunction with Oracle Database In-Memory!
Original publish date: March 25, 2016
