We’ve written a number of blog posts on how Database In-Memory behaves in a RAC environment but recently we’ve gotten a lot of questions regarding what happens if one of the RAC nodes should fail. So, I thought I would tackle this question today and point out a couple of other interesting aspects of running Database In-Memory on RAC in this post.
Quick Recap
If you recall from part 1 of our RAC series each RAC node has it’s own In-Memory column store (IM column store). When a table is populated into memory in a RAC environment it will be distributed across all of the IM column stores in the cluster. That is to say, a piece of the table will appear in each RAC node.
Let’s take a look at an example using the LINEORDER table, which has 5 million rows in it and is approximately 550MB in size on my 3 node RAC cluster.
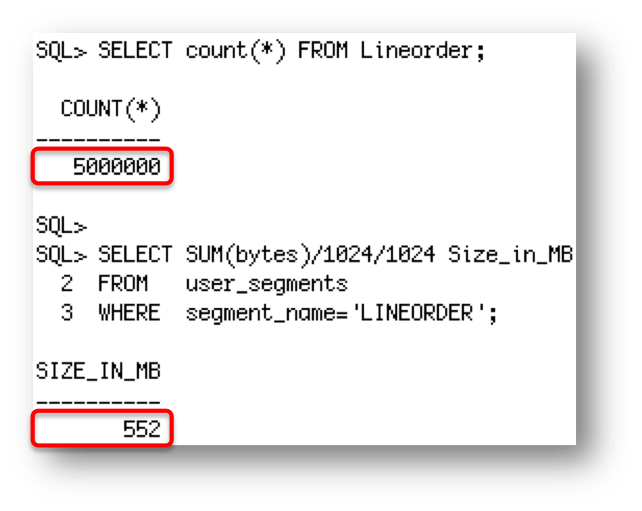
As you can see below, the INMEMORY attribute has been specified on the LINEORDER table but the IM column store on each RAC node is empty.
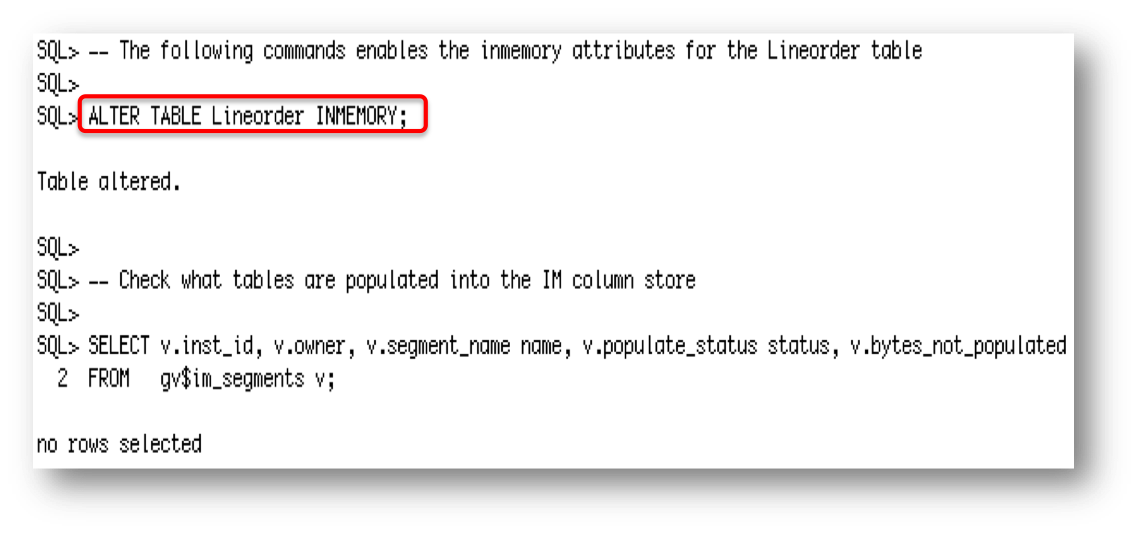
Remember, if you don’t specify the PRIORTY subclause when you apply the INMEMORY attribute to a table, then it won’t be populated into the IM column store until someone queries the table. So let’s do that now.
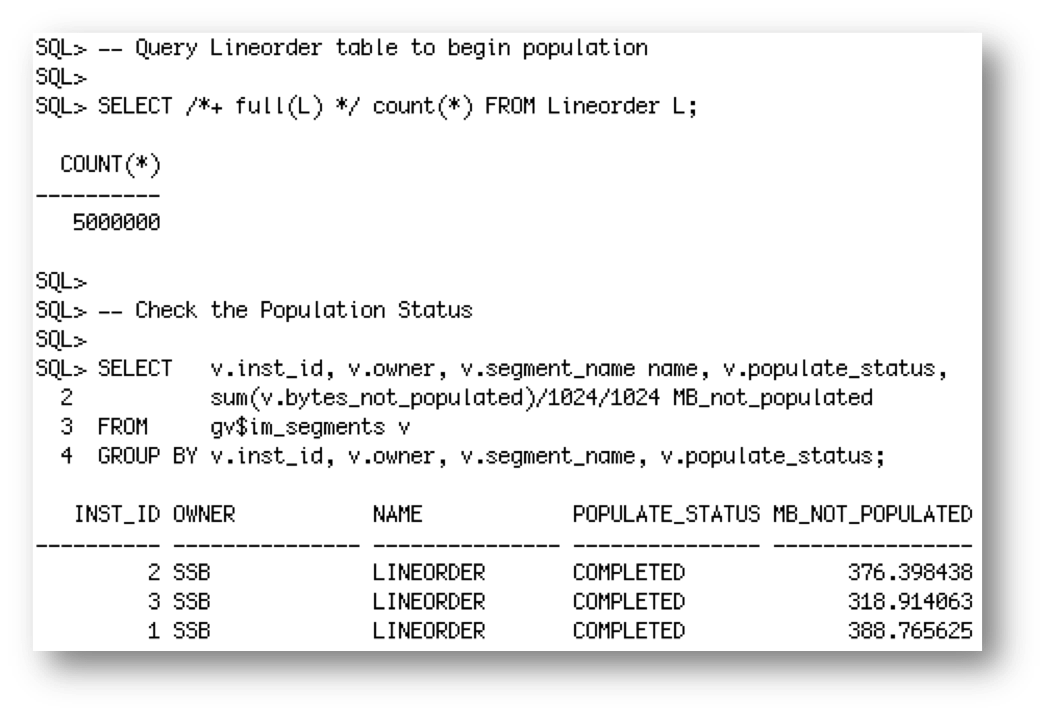
Approximately 1/3 of the LINEORDER table is now populated on each of the RAC nodes. You’ll notice that the BYTES_NOT_POPULATED column is not 0, even though the POPULATE_STATUS is COMPLETE. That’s because not all of the data for the LINEORDER table is populated on each RAC node. So, how do I know if the entire LINEORDER table got populated into memory?
In order to answer that question we need to look at a different view called gv$IM_SEGMENTS_DETAIL and compare the number of blocks in-memory on each node to the total number of blocks in the LINEORDER TABLE.
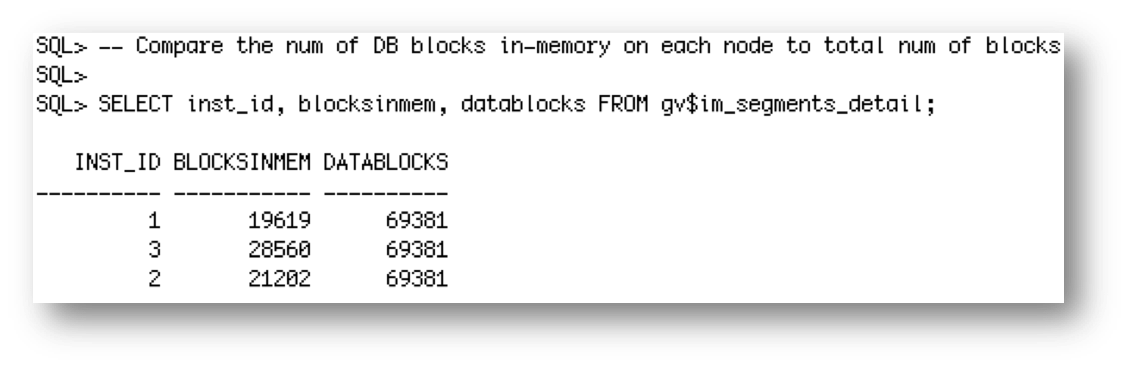
As you can see the LINEORDER table is made up of 69,381 blocks. 19,619 blocks were populated into memory on node 1, 21,202 blocks were populated into memory on node 2, and 28,560 populated into memory on node 3. Add these three values together and we see all 69,381 block from the LINEORDER table were populated.
19,619 + 21,202 + 28,560 = 69,381
But how does that correlate to the BYTES_NOT_POPULATED column that we see when we query gv$IM_SEGMENTS?
A little more math is required to generate that value. If you subtract the number of blocks in-memory on a node from the total number of blocks in the LINEORDER TABLE and multiple it by the block size (8K in my case) you get the value in the BYTES_NOT_POPULATED column.
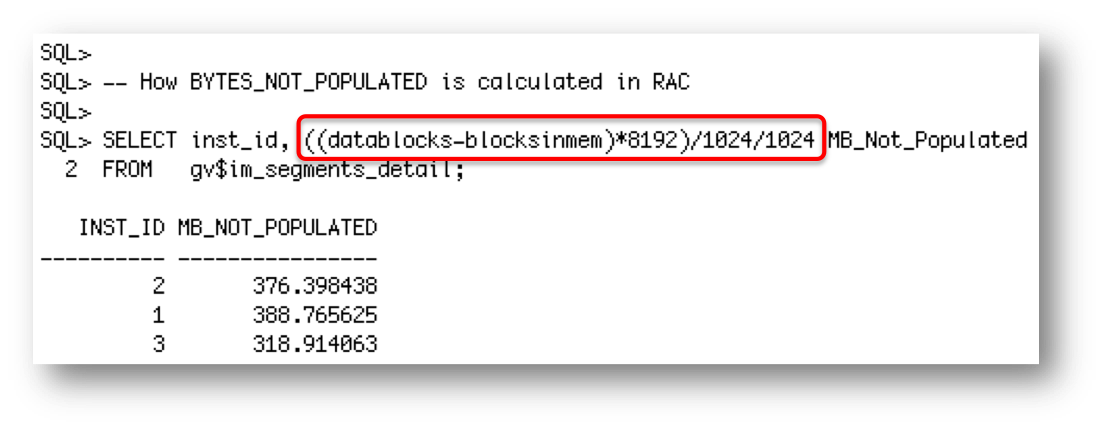
Note that I’ve been rounding up the bytes to MB to make my query output a little easier to read. But I digress; let’s get on with what happens when we have a node failure.
What happens if one of the RAC nodes fails?
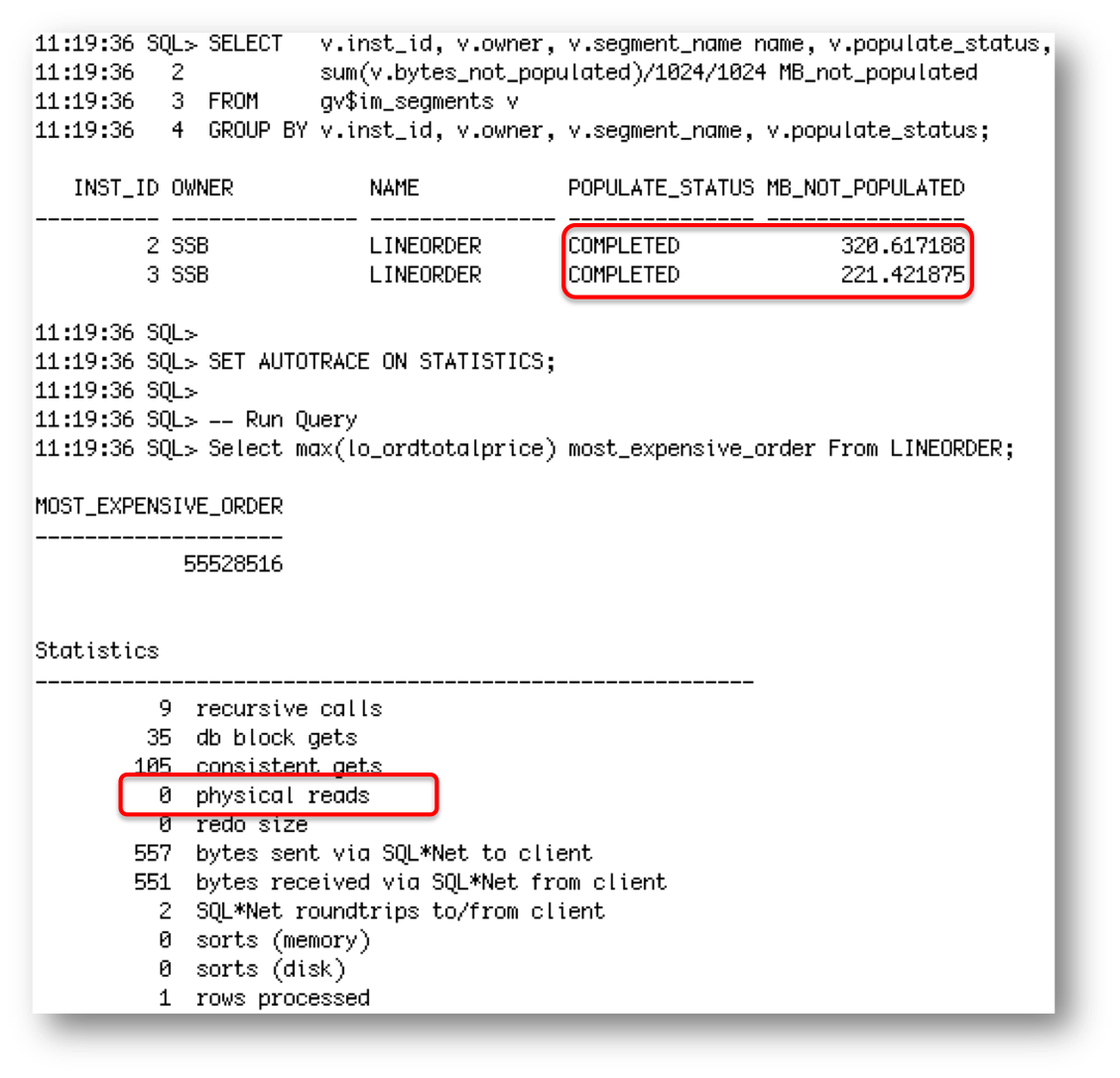
Let’s shutdown node 1 of the RAC cluster to simulate a node failure. If we look in gv$IM_SEGMENTS we see that 1/3 of the data is now missing for the IM column store.
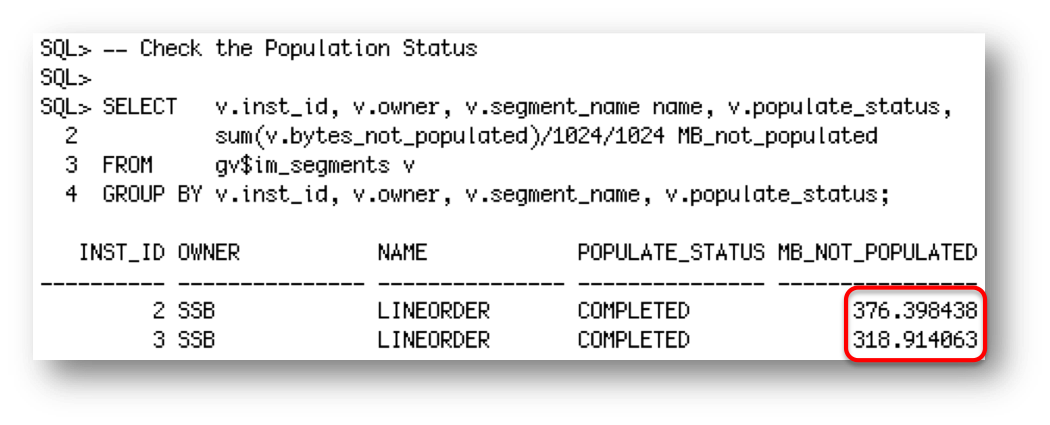
This means that if I run a query on the LINEORDER table 1/3 of the data will have to be read from somewhere else, either the buffer cache, flash, or disk.
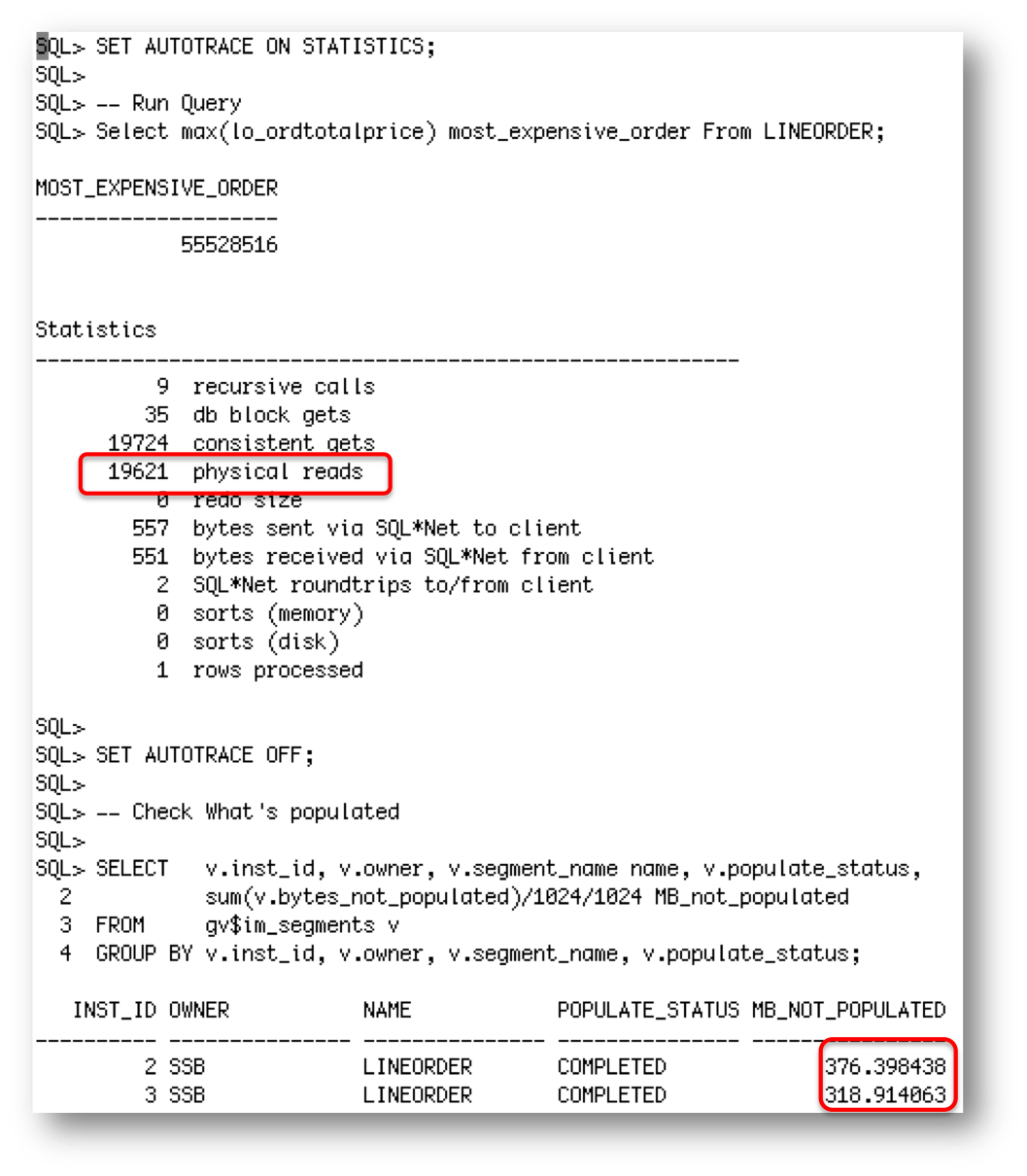
But if we were to wait 5 minutes after node 1 went down and then query the LINEORDER table again, what we will notice is the missing data is automatically populated into the two remaining RAC nodes, assuming of course there is enough free space in the IM column store to accommodate the additional data.
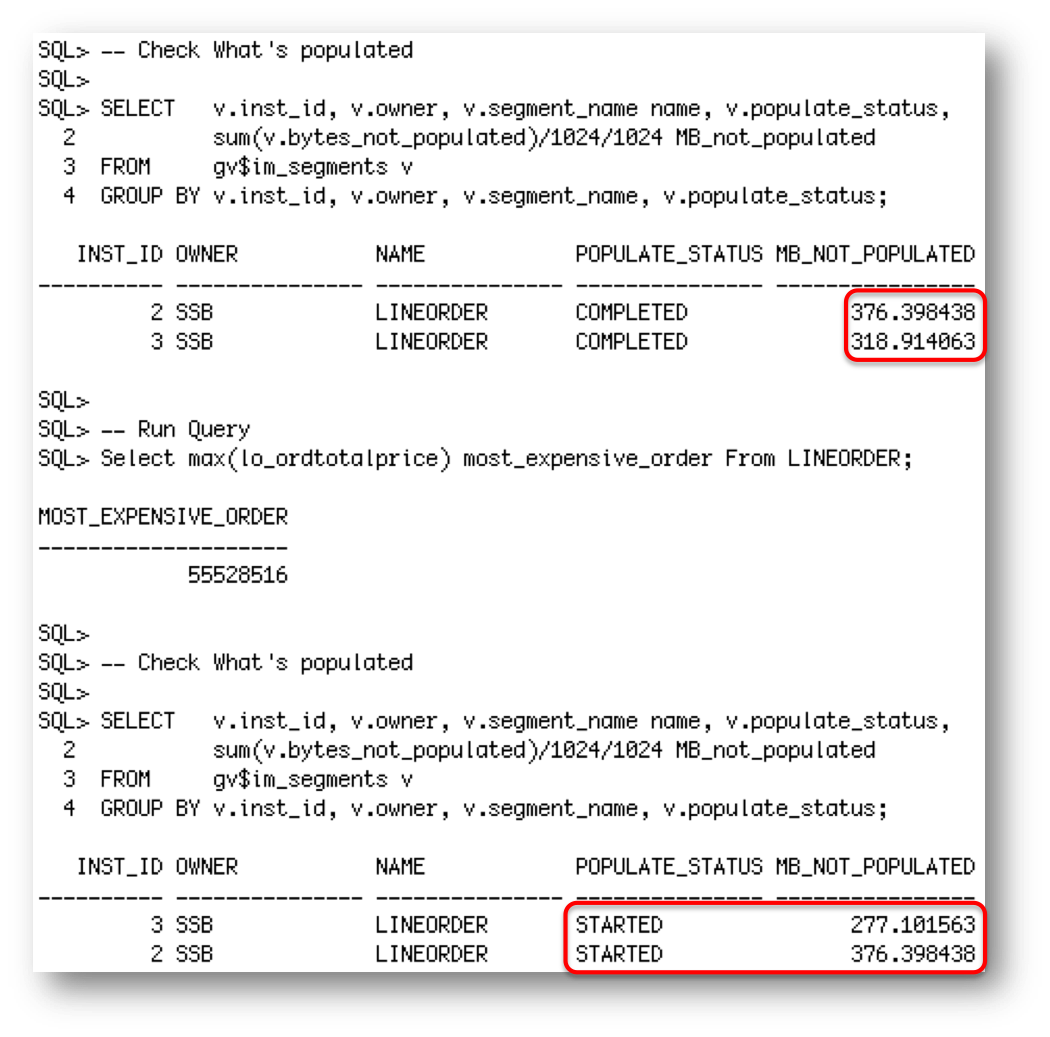
Once the population completes and we run the query again we see all of the data coming the IM column store on the two remaining RAC nodes and if we check gv$IM_SEGMENTS and gv$IM_SEGMENT_DETAILS after the population completes, we can see that all of the data for the LINEORDER table has been populated into the 2 remaining nodes in the RAC Cluster.
You may be wondering why we had to wait 5 minutes and also query the table before the automatic population of the missing data took place?
There is a 5-minute timeout in place just incase someone is simply bouncing RAC node 1 for maintenance. We don’t want to have to go to the trouble of populating the missing data on to node 2 and 3 only to have to rebalance the data again when node 1 comes back up.
The reason we had to query the table is because we didn’t specify a PRIORTY subclause when we applied the INMEMORY attribute to the table at the beginning of this post. As we saw above, you must access a table that does not have a PRIORTY specified to trigger a population.
So, what happens when node 1 is brought back up?
Nothing will happen until we issue a query against the LINEORDER table, but once we do, the data in the IM column store will be automatically redistributed across the 3 RAC nodes.
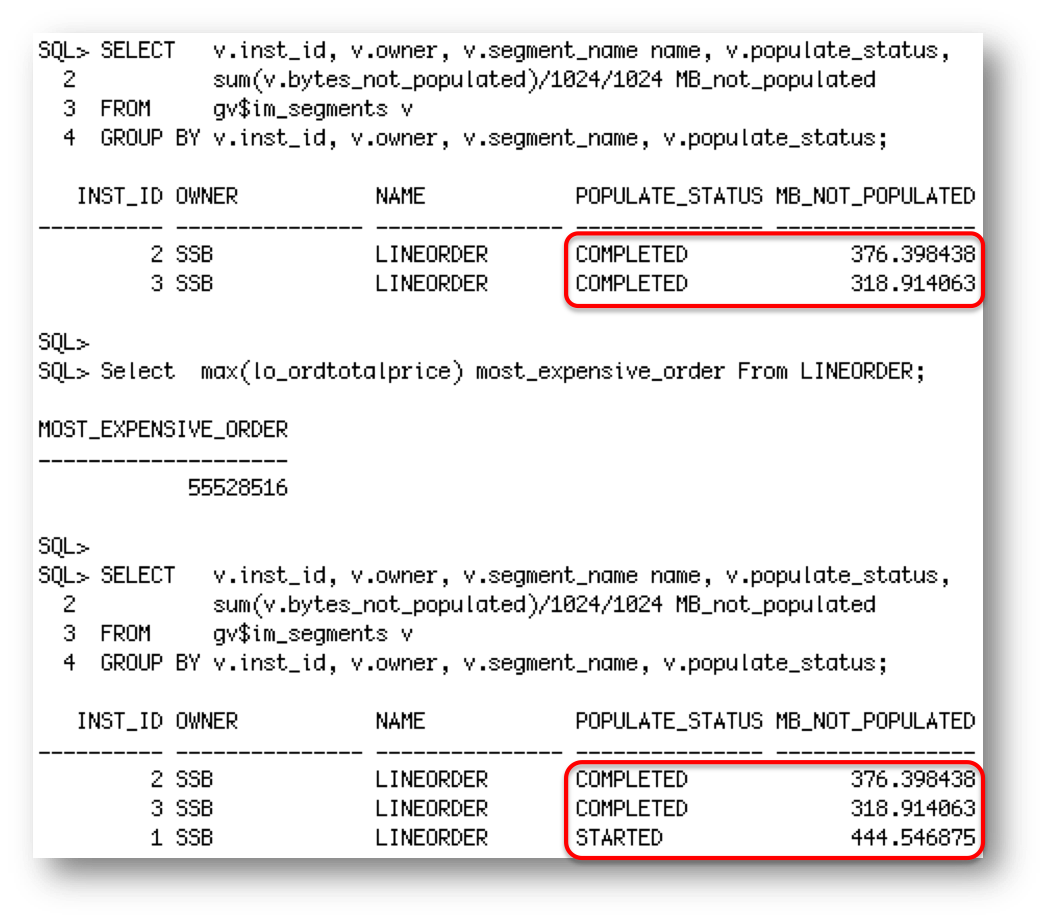
So, there you have it. In-Memory on RAC will automatically populate missing data into the remaining RAC node(s) should a node go down. It will also redistribute the data across the RAC nodes when a new node joins the cluster. Remember, these steps will happen automatically if you have specified a PRIORITY on your tables or immediately after you query the table if no PRIORITY is specified.
Original publish date: November 20, 2015
