In our previous posts we discussed the basic architecture of the In-Memory column store (IM column store) and now we want to drill down into some of the unique performance enhancing features. Push-down is one of the optimizations that makes scanning columns in the IM column store very efficient. Oracle Database In-Memory has the ability to push predicates, aggregations and group-bys down into the scan of a column or columns. This ability to push-down allows us to take advantage of other performance enhancing features of Database In-Memory like SIMD vector processing and storage indexes.
Let’s take a look at a very simple query with two aggregations and see if we can find out what’s happening. We’ll use the following query:
select min(lo_quantity), max(lo_ordtotalprice) from lineorder;
The LINEORDER table in this example has 11,997,996 rows and has been populated into the IM column store using the default in-memory compression, which is “memcompress for query low”
In order to do a meaningful comparison we will use the IM session statistics to verify what is happening. In particular, the statistic “IM scan rows projected“, which indicates the number of rows being returned from the IM column store. Two other statistics are also useful for this investigation, “IM scan rows“, which is the total number of rows in all of the In-Memory Compression Units (IMCU) that were accessed, and “IM scan CUs memcompress for query low“, which is the total number of IMCUs that were touched.
So let’s take a look at what happens when the query is run in sqlplus. The session level statistics are listed by running the script imstats.sql which is simply a join between v$statname and v$mystat that selects any statistic that starts with ‘IM ‘.
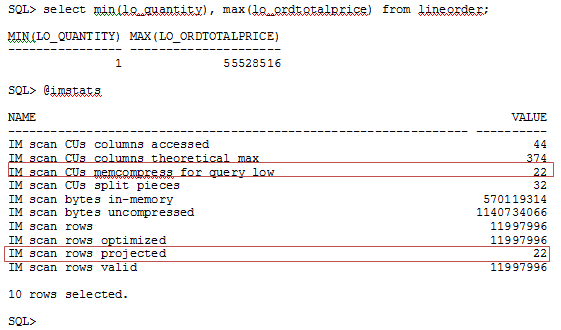
From the statistic output we see that the query accessed 22 IMCUs (IM scan CUs memcompress for query low) and a total of 11,997,996 rows in those 22 IMCUs (IM scan rows), but only “returned” 22 rows (IM scan rows projected) from the IM column store. So how does Oracle return the correct aggregations when it only returns 22 rows from the query? The optimization that is happening is that Database In-Memory is returning the aggregations at the IMCU level back to the query layer. Most of the aggregation work occurs during the actual scan of the IMCUs and this is where considerable time is saved, especially when scanning very large objects. The query layer has much less work to do to complete the aggregation (i.e. over 11 million rows versus just 22).
Now how does that differ from looking at all of the rows in the table? In other words, without the aggregations what do the statistics look like?

We still looked at 22 IMCUs (IM scan CUs memcompress for query low) and we know that we scanned 11,997,996 rows (IM scan rows), but now we see that the “IM scan rows projected” statistic also reflects the total number of rows that are returned.
Let’s look at one more query, this one finds “What is the most expensive air-mail order we have received to date?” It has both an aggregation and a filter predicate.

Now we see three additional statistics, specifically “IM scan CUs predicates applied“, “IM scan CUs predicates received” and “IM scan segments minmax eligible“. These statistics tell us two things. The first is that we applied our filter predicate (lo_shipmode = ‘AIR’) to the 22 IMCUs (IM scan CUs predicates applied/received) that comprise the LINEORDER table, and that we accessed the In-Memory Storage Index on the lo_shipmode column and compared min/max values for the 22 IMCUs (IM scan segments minmax eligible). And again we returned just 22 rows back to the query layer as a result of the aggregation performed at the IMCU level (IM scan rows projected). So we can conclude that not only was the aggregate “pushed” into the scan as in our first example, but the where clause predicate lo_shipmode = ‘AIR’ was also “pushed” into the scan and evaluated for each IMCU accessed. All of these optimizations result in a much faster scan with fewer rows returned than a traditional row based scan.
I hope that this posting was helpful in showing another one of the optimizations that have been made to make scans of the IM column store as fast as possible with Database In-Memory.
Original publish date: March 31, 2015
