In part 3 of our series on Oracle Database In-Memory in a RAC
environment we are going to explore the DUPLICATE and DUPLICATE ALL sub-clauses.
Before we get into the technical details I should point out that the DUPLICATE
sub-clause is only applicable on Engineered Systems. If you specify it on a non-Engineered
System it will simply be ignored. We should
also do a quick review of the components in the Oracle Database In-Memory
Column Store (IM column store). The IM column store is comprised of In-Memory
Compression Units (IMCU) and Snapshot Metadata Units (SMU). The IMCUs are read
only structures that store the actual columnar data and can be thought of in
the same way as tablespace extents.
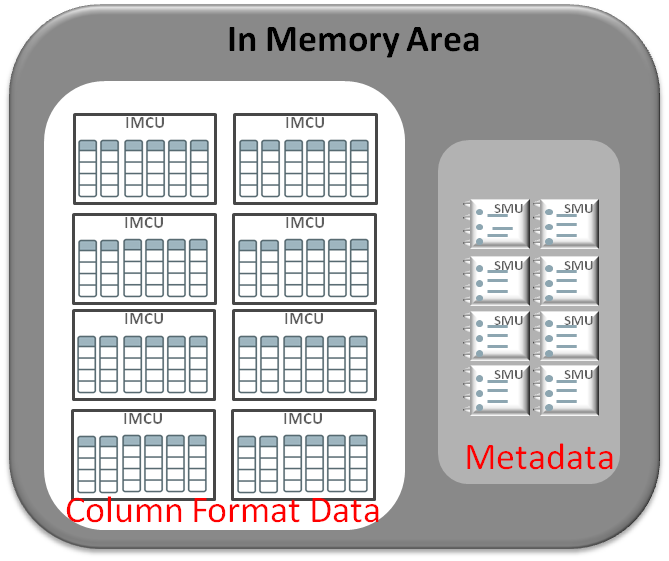
Each object in the IM column store will be made up of one or more IMCUs and it is these IMCUs that are affected by the DUPLICATE sub-clauses.
If you recall from part 1 of our RAC series, data populated into memory in a RAC environment will be distributed across all of the IM column stores in the cluster. If a RAC instance should fail, then the data, or IMCUs, in the IM column store on that RAC instance will no longer be available. This means that the data in those IMCUs will have to be read from somewhere else, either the buffer cache, flash, or disk, unless there are copies of those IMCUs in another IM column store.
DUPLICATE sub-clause
Specifying the DUPLICATE sub-clause will cause each IMCU for an object to be mirrored in memory, with a primary copy on one RAC instance and a secondary copy on another instance. If a RAC instance should fail then the data, or IMCUs, are simply read from the other side of the mirror or from another IM column store thus preventing the necessity to read any data from the buffer cache or disk. It should be noted that the DUPLICATE sub-clause can be specified at the tablespace or object level and the memory requirements will double for an object when the DUPLICATE sub-clause is used. But I should also point out that not all objects in the IM column store have to use the DUPLICATE sub-clause. It’s possible to specify the DUPLICATE sub-clause on a subset of objects. For example, you may specify DUPLICATE on just this year’s partitions while leaving others partitions from the same table not duplicated.
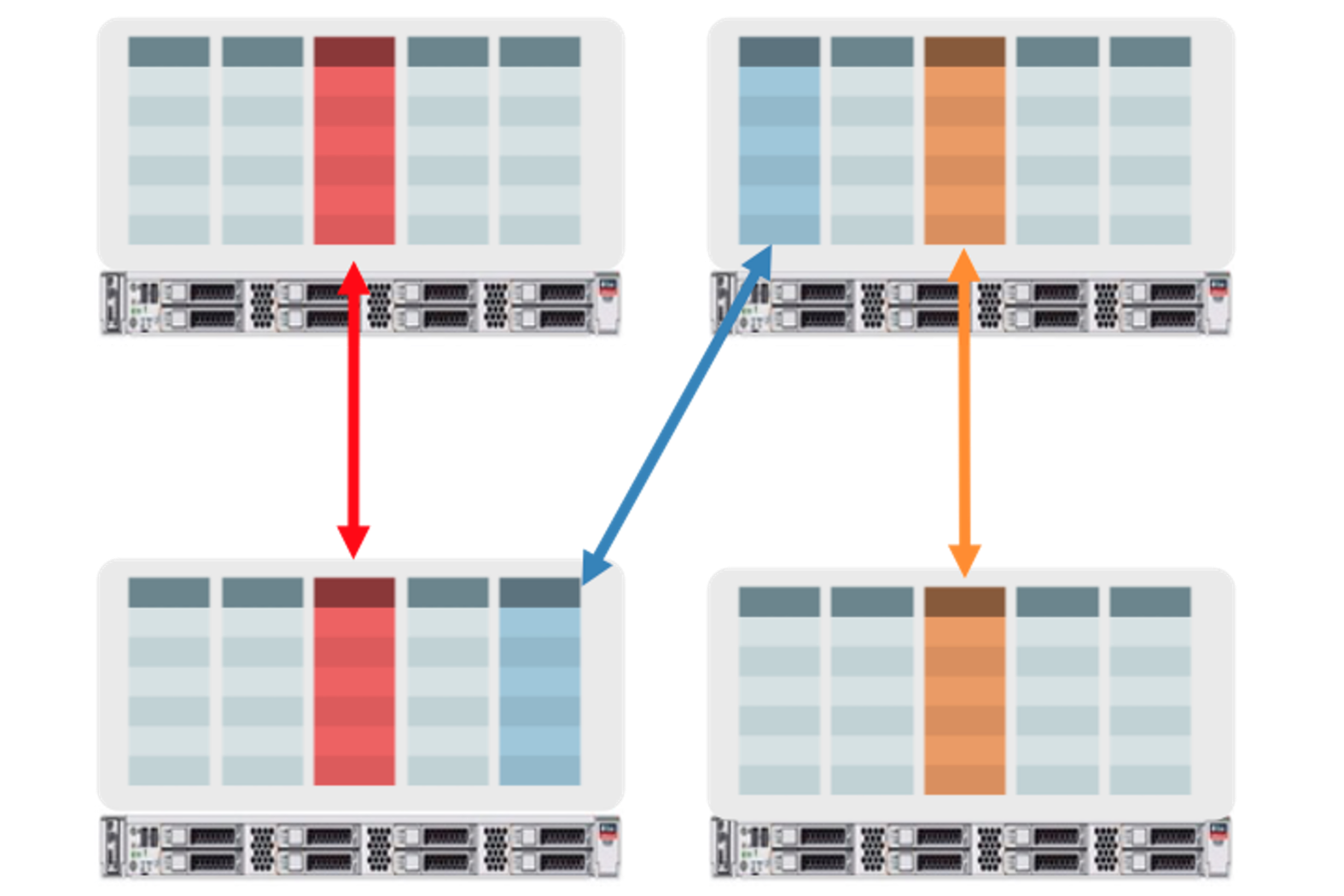
DUPLICATE sub-clause and RAC Services
Earlier in this series we also discussed how RAC services could be used to enable IM column stores to be run on a subset of nodes in a RAC environment. The service was configured to insure that a query will always run from an instance that has an IM column store. This is a requirement to insure that the parallel query coordinator can find the home locations of all the IMCUs in the participating RAC instances. Remember that the only way to access all of the IMCUs that have been distributed across multiple RAC instances is to use parallel query.
The combination of RAC services and the DUPLICATE sub-clause presents us with another opportunity, rolling patches / upgrades. If a RAC service has been set up to direct client queries that rely on Database In-Memory to the RAC instances supporting IM column stores, then when using the DUPLICATE sub-clause it is possible to selectively take an instance out of service without impacting response time SLAs, assuming that there are enough resources on the other RAC instances in the service to handle the workload of the instance being removed. Not only does the DUPLICATE sub-clause preserve query performance in the event of a single instance failure by providing a secondary copy of all IMCUs in-memory on another instance, it also has the potential to provide the facility for maintenance to be performed on single instances without impacting availability or response time SLAs.
DUPLICATE ALL sub-clause
What’s the difference between the DUPLICATE and DUPLICATE ALL sub-clauses? As we’ve said above, the DUPLICATE sub-clause will create a copy of each IMCU and distribute the IMCU to two different IM column stores in the RAC cluster. The DUPLICATE ALL sub-clause will create a copy of each IMCU in all of the available IM column stores in the RAC cluster. In the case of DUPLICATE ALL each object specified will be mirrored across all of the IM column stores. This means that the DISTRIBUTE sub-clause will not matter since all IMCUs for the object will be distributed and it also means that the IM column store will not scale out for that object’s space. In other words, a 500MB object will take 500MB in each IM column store in the RAC cluster, rather than being divided across the available IM column stores. But again you should remember this is an object based decision and not objects in the IM column store need to be DUPLICATE ALL.
Why might someone use the DUPLICATE ALL sub-clause instead of just DUPLICATE? There are several reasons but I’ve outlined the two most obvious reasons below.
The first is for very high availability, where it is necessary to have each table entirely in-memory in each database instance. That way it’s possible to sustain N-1 RAC instance failures in a RAC environment with N instances.
The second would be to improve join performance in a Star schema between smaller dimension tables and a large partitioned fact table. In this case the dimension tables would be duplicated across all instances (DUPLICATE ALL), while the fact table would be simply distributed by partition or sub-partition. Joins could then take place entirely within each instance since all of the data needed for each join would be in-memory. This is analogous to a partition-wise join since the entire dimension table would be resident in each IM column store.
To summarize, running Oracle Database In-Memory on a subset of nodes in a RAC environment with the DUPLICATE sub-clause can help insure that if a node fails or needs to be taken out of service for maintenance that critical data is always available in at least one In-Memory column store. Services, along with the appropriate client configuration, can insure that there is little or no impact to client availability and response time. The DUPLICATE ALL sub-clause can be used to provide very high availability by duplicating IMCUs across all IM column stores and can provide improved performance for star query type joins.
Original publish date: December 31, 2014
