As we continue our series of Q&A style blogs on Oracle Database In-Memory, I’ve got a chance to go back to my old life as the optimizer lady as I’ve been inundated with questions about the In-Memory option and the Optimizer.
Below are the answers to the questions I gotten so far.
If there is something else you want to know about how these two fascinating pieces of the Oracle technology work together just email me and I will include it in an upcoming post.
Is there a new Optimizer to deal with queries against the In-Memory column store?
No, there is no new Optimizer in Oracle Database 12.1.0.2. But the existing cost-based Optimizer has been enhanced to make it aware of the In-Memory column store (IM column store) and the objects that reside in it. The cost model has been enhances to consider in-memory scans, joins and aggregations.
For example, If a query is looking up a small number of records (rows), and an index on the WHERE clause column exists, the Optimizer will select an index access path (via the buffer cache), as this execution plan will be both more efficient (lowest cost) and more scalable in a multi-user environment.
Alternately, for an analytic query that accesses a small number of columns from a large number of rows, the Optimizer will select a full table or partition scan via the In-Memory column store.
Are there new Optimizer hints for In-Memory?
Yes, the different aspects of the In-Memory option- in-memory scans, joins and aggregations – can be control at a statement or a statement block level via the use of optimizer hints. As with most optimizer hints, the corresponding negative hint for each of these is preceded by word ‘NO_’.
For example, the INMEMORY hint allows the scan of in-memory objects to be enabled at the statement block level.
Will the same optimizer trace event work with In-Memory objects?
Yes, the same Optimizer trace event (10053) will work, even if some or all of the tables accessed in a query reside in the In-Memory column store (IM column store).
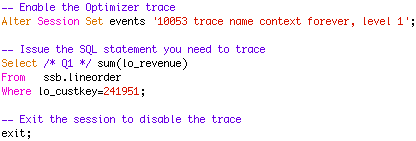
Or alternatively you can use the new diagnostic events infrastructure introduced in Oracle Database 11g.

What should I look for in the optimizer trace to determine if a column format table is being considered?
Under the BASE STATISTICAL INFORMATION section in the 10053 trace file you will see the In-Memory statistics that are automatics collected for any table currently populated into the In-Memory column store.

In the Access path analysis section for each of these table,s you will also see the CPU costing being calculated for the In-Memory scan of the table.
Are any additional Optimizer statistics required?
No, you don’t need to gather any additional statistics. The additional statistically information for the objects currently populated in the IM column store is automatically generated for the Optimizer.
Do I need to change the way I gather statistics if my table has been populated into the column store?
No, you don’t need to change the way you gather statistics today, assuming your existing method follows Oracle best practices for statistics gathering. Remember, you do still need to provide a representative set of statistics for each table accessed in a query as the decision to use the IM column store is a cost based decision that relies on accurate table statistics and the new in-memory statistics automatically supplied to the Optimizer.
What changes must I make to my existing applications to take advantage of the Oracle Database In-Memory option?
No changes are necessary to your existing applications in order to take advantage of the Oracle Database In-Memory option. Any query that will benefit from the In-Memory column store will be automatically directed there, by the Optimizer. However, additional speedups may be achieved using existing performance improving techniques in-conjunction with the IM column store.
In some cases, eliminating existing indexes that are used only for reporting or other analytics can improve overall throughput. The safest ways to remove indexes is to first mark the indexes invisible and thereby allow the optimizer to select an in-memory based plan more often. If you are happy with the performance improvements achieved, you can eliminate (drop) the unnecessary indexes, which will enable your application to run faster as fewer indexes will need to be maintained, and will reduce the size of your database.
Join performance can also be improved in some cases by creating a Materialized View that pre-join tables. By placing that Materialized View in-memory, the compression techniques employed by the IM column store will greatly reduce the data growth that typically occurs when tables are pre-joined and the use of vector processing can greatly accelerate the scan of the Materialized view.
Should I replace all of indexes with the In-Memory column store to make it easier for the Optimizer?
No, we do not recommend replacing all existing indexes with the In-Memory column store. Indexes provide an extremely efficient and scalable access path to table data when a small number of rows is requested. The In-Memory column store does not improve upon these types of queries. To ensure your applications perform as well as they do today, we recommend you leave the indexes that support referential integrity and OLTP accesses intact.
Original publish date: July 6, 2014
