Setting Up Independent In-Memory Column Stores
In previous posts we’ve talked about how to use RAC services to enable the IM column store to be run on a subset of nodes in a RAC environment. We also mentioned that it is possible, using RAC services and the DUPLICATE sub-clause on engineered systems, to enable rolling patches and upgrades when running the IM column store on a subset of nodes.
In this article we’re going to talk about how to set up independent IM column stores on a RAC cluster using services and some database initialization parameters.
But first let’s ask and answer the question, why would you want to do this?
This might be a good idea if you are trying to enforce application affinity at the node level and don’t want to allow inter-instance parallelism.
This technique could be used to allow the running of all of the workload for a given application, along with any Database In-Memory workload to support that application, on just a single node in a RAC environment. This technique can also be used to support multiple “independent” IM column stores if, for example, you wanted to partition multiple applications across nodes in your RAC environment. However, the objects populated in the IM column stores in this example have to be distinct, you cannot intermix objects between multiple IM column stores. In other words, you cannot cheat and try to set up duplication of objects. That will only work on engineered systems.
So how do we get started?
The following will take you through setting up three “independent” IM column stores on a three node RAC, and then we will populate objects into two separate IM column stores and see how it all works. We’re going to assume though, that we already have the three node RAC running and that we’ve allocated an IM column store on each instance by setting the INMEMORY_SIZE parameter to a non-zero value.
Network and Service Connections
First we will add services and appropriate TNS entries so that we can connect to each of our RAC instances independently. This will be required to insure that we only populate and access the IM column store that we intend to use for each or our application(s).
srvctl add service -db dgrac -service IM1 -preferred rac srvctl add service -db dgrac -service IM2 -preferred rac2 srvctl add service -db dgrac -service IM3 -preferred rac3 srvctl start service -db dgrac -service "IM1,IM2,IM3"
If we query the services they should look something like the following. Note that the RAC instance names in this example are rac, rac2 and rac3. The database unique name is dgrac:
$ srvctl status service -db dgrac Service IM1 is running on instance(s) rac Service IM2 is running on instance(s) rac2 Service IM3 is running on instance(s) rac3 $
Add a TNS entry for each service:
IM1 =
(DESCRIPTION=
(ADDRESS=(PROTOCOL=TCP)(HOST=rac1)(PORT=1521))
(ADDRESS=(PROTOCOL=TCP)(HOST=rac2)(PORT=1521))
(ADDRESS=(PROTOCOL=TCP)(HOST=rac3)(PORT=1521))
(CONNECT_DATA=
(SERVICE_NAME=IM1)
)
)
IM2 =
(DESCRIPTION=
(ADDRESS=(PROTOCOL=TCP)(HOST=rac1)(PORT=1521))
(ADDRESS=(PROTOCOL=TCP)(HOST=rac2)(PORT=1521))
(ADDRESS=(PROTOCOL=TCP)(HOST=rac3)(PORT=1521))
(CONNECT_DATA=
(SERVICE_NAME=IM2)
)
)
IM3 =
(DESCRIPTION=
(ADDRESS=(PROTOCOL=TCP)(HOST=rac1)(PORT=1521))
(ADDRESS=(PROTOCOL=TCP)(HOST=rac2)(PORT=1521))
(ADDRESS=(PROTOCOL=TCP)(HOST=rac3)(PORT=1521))
(CONNECT_DATA=
(SERVICE_NAME=IM3)
)
)
Verify service name connection:
SQL> connect ssb/ssb@im1 Connected. SQL> select instance_name from v$instance; INSTANCE_NAME ---------------- rac SQL> connect ssb/ssb@im2 Connected. SQL> select instance_name from v$instance; INSTANCE_NAME ---------------- rac2 SQL> connect ssb/ssb@im3 Connected. SQL> select instance_name from v$instance; INSTANCE_NAME ---------------- rac3 SQL>
Parallelism
Next we need to set the initialization parameter PARALLEL_FORCE_LOCAL to TRUE. This has implications for all parallel processing since we will effectively be preventing inter-node parallelism, whether it’s for Database In-Memory parallel queries or any other parallel queries. In other words, parallel server processes will be restricted so that they can only run on the node on which the SQL statement was executed.
We have one more step in this setup and that is to set the PARALLEL_INSTANCE_GROUP parameter on each of our RAC instances. The PARALLEL_INSTANCE_GROUP parameter restricts parallel query operations to just the instances supported by the service name or specified by the instance_groups parameter on the instance where it is set. In our case we will set the PARALLEL_INSTANCE_GROUP parameter to the service_name we defined for each of our three instances. In other words:
On node1 we define PARALLEL_INSTANCE_GROUP = IM1, on node2 PARALLEL_INSTANCE_GROUP = IM2 and on node3 PARALLEL_INSTANCE_GROUP = IM3. This will only allow population of the IM column store to occur on the node where we first access the object(s) that we want populated.
$ sqlplus system@im1 SQL*Plus: Release 12.1.0.2.0 Production on Wed Jul 29 16:05:55 2015 Copyright (c) 1982, 2014, Oracle. All rights reserved. Enter password: Last Successful login time: Wed Jul 29 2015 16:05:38 -07:00 Connected to: Oracle Database 12c Enterprise Edition Release 12.1.0.2.0 - 64bit Production With the Partitioning, Real Application Clusters, OLAP, Advanced Analytics and Real Application Testing options SQL> alter system set parallel_instance_group=IM1 scope=both sid='rac'; System altered. SQL> alter system set parallel_instance_group=IM2 scope=both sid='rac2'; System altered. SQL> alter system set parallel_instance_group=IM3 scope=both sid='rac3'; System altered. SQL>
Priority
To insure that specific objects are populated into specific IM column stores we will have to set the population priority to NONE for the objects that we want to access in the IM column store, and we will have to access the object(s) (e.g. run a select) to start it’s population connected to the instance that we want the object(s) populated on.
Not to confuse the issue, but what happens if you set the priority to a level other than NONE? The answer is that you will not be able to control which node the population occurs on. At instance or database startup the population will be eligible to begin and it won’t be possible to specify which objects should be populated into which IM column stores. This defeats the purpose of populating based on specific node/service combinations to achieve application affinity. Note that this also prevents any kind of distribution since we’ve limited parallelism to just the node that we execute from.
Population
Now that we have the connectivity set up let’s see how we’ll populate two of the IM column stores with tables from our SSB schema. First we will connect to the IM1 service (e.g. the rac instance) and we will alter the CUSTOMER table to be in-memory with a priority of none. We will then select from it to initiate the population.
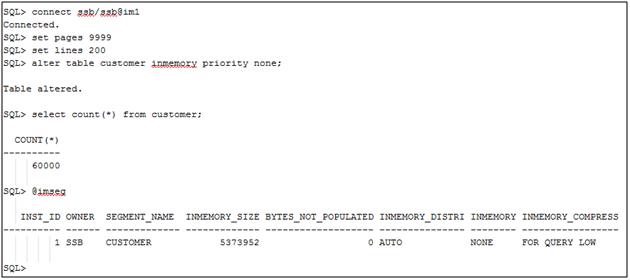
Now we’ll populate the SUPPLIER table to the IM column store for the IM2 service (e.g. the rac2 instance).
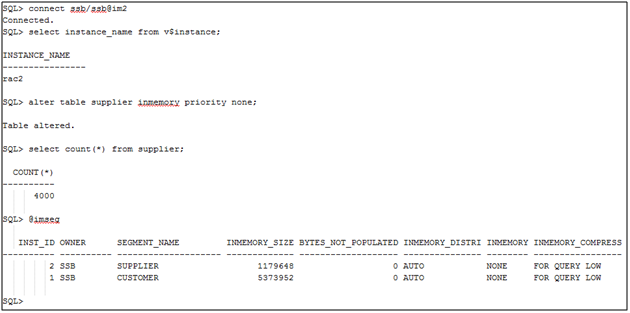
Note that we now have the CUSTOMER table entirely populated within the inst_id 1 IM column store and the SUPPLIER table entirely populated within the inst_id 2 IM column store.
Queries
So we now have our two tables populated into separate IM column stores in a single RAC environment. Please remember that this is just a simple example. We would really be populating the tables for an entire application into a single IM column store, not just one table as in this example. So what happens if we connect to our IM2 service (e.g. the rac2 instance) and query each of the tables? Let’s give it a try.
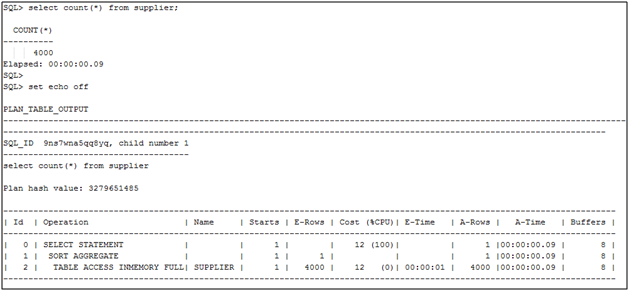
In this first query we have performed a simple count for the SUPPLIER table. From the execution plan and timing it looks like we’ve accessed the table through the IM column store and if we take a look at the statistics we can verify this:

We see that we have IM statistics and that we accessed all 4000 rows from the IM column store (e.g. that is IM scan rows projected is 4000). Now let’s do the same for the CUSTOMER table, but remember that we’re connected to the IM2 service and the CUSTOMER table is populated in the IM column store for the IM1 service which is on instance 1 (e.g. the rac instance).
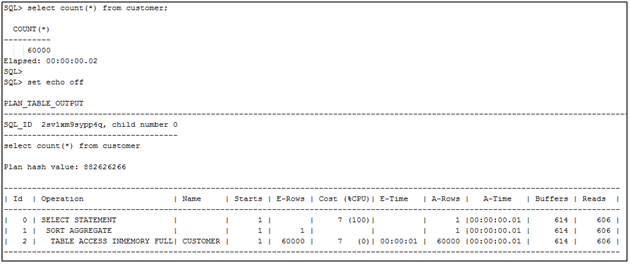
Now that’s strange. The explain plan indicates that we accessed the CUSTOMER table in-memory as well. Let’s see what the statistics tell us.
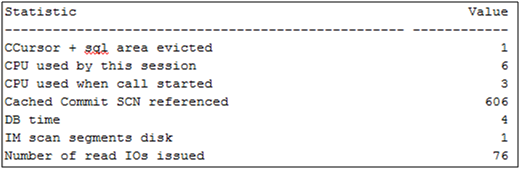
Whoops, no IM related stats other than IM scan segments disk and if we look further down the list we see that we did not get the 60,000 rows in the table from the IM column store (e.g. table scan disk non-IMC rows gotten):

So this is really just meant to show that once you decide to use separate IM column stores for application affinity, if you need to access in-memory objects from a different node then you will have to go to the buffer cache/disk. Of course the whole point of setting up separate IM column stores was so that you could isolate an application to just one node, and why we had to set parallel_local_force = true and the parallel_instance_group parameter to the service name for each of the instances.
Original publish date: August 4, 2015
