One of the big advantages of Database In-Memory is the ability to convert a hash join using Bloom filters into a scan and filter operation. I always talk about this as one of the Optimizer features available with Database In-Memory when I give conference presentations or customer talks. In fact, Maria (@SQLMaria) blogged about this, and joins in general, back in 2014 in this post: Getting started with Oracle Database In-Memory Part IV – Joins In The IM Column Store.
Normally we only talk about hash joins with Database In-Memory since Database In-Memory accesses a table with a TABLE ACCESS INMEMORY FULL operation and does not use traditional Oracle Database indexes. Since most analytic queries access large amounts of data, a hash join is usually the most efficient way of joining data in the IM column store, and if there are filter predicates on the dimension table(s) then Database In-Memory can leverage Bloom filters to effectively change a hash join into a scan and filter operation.
The following is an example using the SSB schema. Using the following SQL:
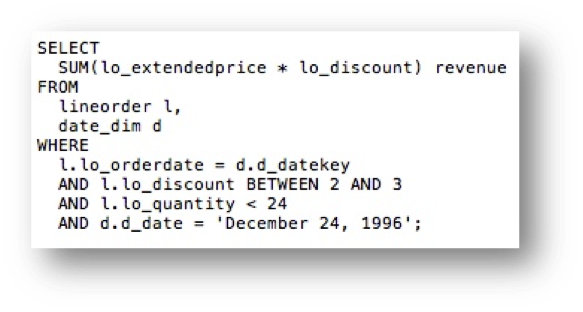
Accessing the LINEORDER and DATE_DIM tables with no indexes and a filter predicate on the DATE_DIM table results in the following execution plan:
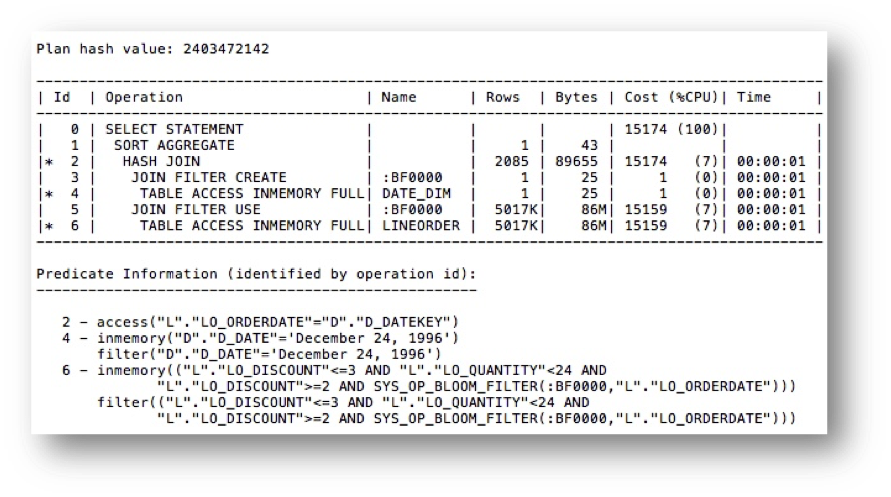
Notice that a hash join was used (line 2) and a Bloom filter was created from the DATE_DIM table (line 3) and used when accessing the LINEORDER table (line 5).
But what if the LINEORDER table had an index, say on the LO_ORDERDATE column? Starting in Oracle Database 12.2, Database In-Memory and the Optimizer can combine in-memory access on one table with index access on another table using a nested loops join if the cost is less than other options.
Here’s an example of the same query, but with an index on the LO_ORDERDATE column of the LINEORDER table:
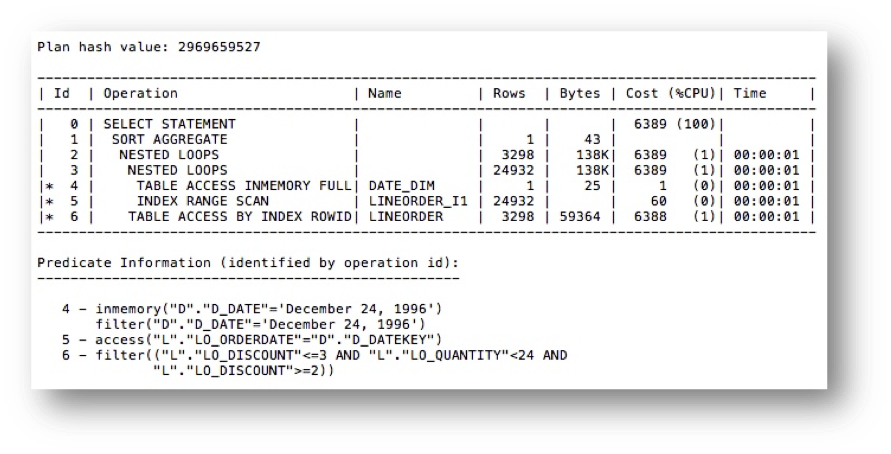
Notice that the total cost dropped from 15174 down to 6389 and we used a nested loops join (line 3) and accessed the DATE_DIM table in-memory (line 4) and the LINEORDER table using the LINEORDER_I1 index (line 5). This was an enhancement we made in 12.2 and provides another example of the improvements that are continually being added to Database In-Memory.
What was the response time difference between the two queries? In this case the first query using the hash join ran in 0.13 seconds and the second query using the nested loops join ran in 0.10 seconds. Now my LINEORDER table only has about 60 million rows, and the costs on larger tables may tip the balance from an index access to an in-memory access, or the other way around. However, that’s the beauty of the implementation of Database In-Memory, it’s a cost based decision. The Optimizer decides at parse time the best execution plan based on the cost, which as we’ve pointed out many times, is why you don’t have to change your SQL to take advantage of this optimization and Database In-Memory in general.
This is not to say that you should have analytic indexes on all of your tables. The actual resource usage may be close enough between an in-memory access and an index access that the DML impact of having the index or indexes may not make sense. Remember that indexes are not free. They take up disk space, many times in mature applications tables will have more space used for indexes than the table data itself, plus the index must be maintained during DML operations and will generate undo and redo to allow rollback and recovery.
Original publish date: 3/26/2019
