I’d like to thank everyone who attended our two Hands On Lab sessions at Collaborate last week. We had a great time presenting them and we received some really good feedback. One of the questions that came up, and gets asked periodically, is how does In-Memory priority really work?
Many times people have the misconception that the In-Memory priority attribute affects more than just the order of population but that’s not the case. The only thing the priority affects is the order of population at database start-up. We discussed population briefly some time ago, but I think it’s worth a quick review.
There are five priority levels: CRITICAL, HIGH, MEDIUM, LOW and NONE. The following describes how the priority levels affect population:
- CRITICAL – Populate table data before data for objects with a priority of NONE, LOW, MEDIUM or HIGH.
- HIGH – Populate table data before data for objects with a priority of NONE, LOW or MEDIUM and after objects with a priority of CRITICAL.
- MEDIUM – Populate table data before data for objects with a priority of NONE or LOW and after objects with a priority of HIGH or CRITICAL.
- LOW – Populate table data before data for objects with a priority of NONE and after objects with a priority of MEDIUM, HIGH or CRITICAL.
- NONE – This is the default and the table data is populated on first access of the object. Once accessed the object will be populated regardless of the population of other objects with a priority.
The next questions people usually ask is how fast population will occur or is there a chance that population will overwhelm my system? The speed or resources consumed by the data population is controlled by the parameter INMEMORY_MAX_POPULATE_SERVERS. This parameter specifies the maximum number of background populate servers that can be used during data population and the default value is half the effective CPU count (CPU_COUNT).
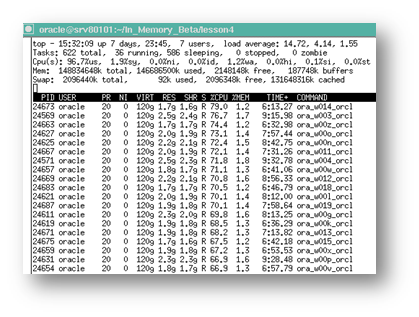
These background populate servers can be seen at the operating system level by looking for processes with names like ora_w001_orcl where orcl is the SID name of the database and w001 is a unique process name. See the figure below for an example. Don’t panic if you don’t see many populate servers when the database is idle. Just like parallel execution servers, these background processes are only spawned when they are needed.
During the initial population the populate servers will read table data directly from disk using direct path reads, which is a lot faster than reading the data through the buffer cache. This also prevents the buffer cache from being flooded with blocks from In-Memory population.
The Database Resource Manager can also be used to control resource usage during population by setting up a resource plan. By default, in-memory population is run in the ora$autotask consumer group, except for on-demand population, which runs in the consumer group of the user that triggered the population. If the ora$autotask consumer group doesn’t exist in the resource plan, then the population will run in OTHER_GROUPS. The following is an example of assigning In-Memory populate servers to a specific resource manager consumer group:
BEGIN
dbms_resource_manager.set_consumer_group_mapping(
attribute => 'ORACLE_FUNCTION',
value => 'INMEMORY',
consumer_group => 'BATCH_GROUP');
END;
After invoking this code the populate servers will be assigned to the BATCH_GROUP consumer group. This will limit the CPU utilization to the value specified by the plan directive for the BATCH_GROUP consumer group as specified in the resource plan.
Hopefully this helps clear up any misunderstandings about the In-Memory priority attribute and how it affects the population of the In-Memory column store.
Original publish date: April 24, 2015
