I’m finally going to make good on a promise I made way back in part 3 of our getting started with In-Memory series, to explain how you could control which queries use the In-Memory column store (IM column store) and which don’t.
As with all new query performances enhancing features in the Oracle Database, a number of initialization parameters and hints have been introduce that enable you to control when and how the IM column store will be used. This post provides information on the initialization parameter, while the details on the Optimizer hint that control the use of the IM column store can be found on the Optimizer blog.
When it comes to controlling the use of the IM column store the most powerful parameter at your disposable is INMEMORY_QUERY (default value is ENABLE). Setting INMEMORY_QUERY to DISABLE either at the session or system level disables the use of the IM column store completely. It will blind the Optimizer to what is in the IM column store and it will prevent the execution layer from scanning and filtering data in the IM column store.
Let’s take a look at an example using the simplest of queries that asks the question, “What is the most expensive order we have received to date?”
SELECT Max(lo_ordtotalprice) most_expensive_order
FROM lineorder;
The LINEORDERS table has 23,996,604 rows and it’s been fully populated into the IM column store. If we run the query with all default parameter settings, it completes 0.04 seconds.

If we check the execution plan, you can see that the query did a full table scan via the IM column store.

Now let’s set INMEMORY_QUERY to DISABLE at the session level and rerun our simple query.

The elapsed time is considerably longer this time, over 36 seconds. If we examine the execution plan you’ll see that we still have the same SQL_ID (53xrbdufu4h4q) but a new child cursor (child number 1) has been created because although we still do a full table scan it’s not an in-memory scan.

What’s even more interesting is the plan hash value (2267213921) is the same, even though the plan text is different. The plan hash value doesn’t change because the keyword INMEMORY is not actually considered when the plan hash value is determined. The reason the keyword is ignored actually goes back a lot further than Database In-Memory.
When Oracle Exadata was first introduced in 2008, a new keyword STORAGE was added to TABLE ACCESS FULL operation to indicate that the scan was being offloaded to the Exadata storage and would potentially benefit from smart scan. In order to ensure the new keyword wouldn’t trigger automatically testing tools to consider the smart scan as a plan change, it was decided that all keywords such as STORAGE and INMEMORY would be ignore when determining the plan hash value.
But I digress; let’s get back to our discussion on controlling the use of the IM column store.
If you want to prevent the Optimizer from considering the information it has about the objects populated into the IM column store (in-memory statistics), or in other words, revert the cost model back to what it was before In-Memory came along, you have two options;
Set OPTIMIZER_FEATURES_ENABLE to 12.1.0.1 or lower.
This would force the Optimizer to use the cost model from that previous release, effectively removing all knowledge of the IM column store. However, you will also undo all of the other changes made to the Optimizer in the subsequent releases, which could result in some undesirable side effects.
- Set the new OPTIMIZER_INMEMORY_AWARE parameter to FALSE.
This is definitely the less dramatic approach, as it will disable only the optimizer cost model enhancements for in-memory. Setting the parameter to FALSE causes the Optimizer to ignore the in-memory statistics of tables during the optimization of SQL statements.
I should point out that even with the Optimizer in-memory enhancements disabled, you might still get an In-Memory plan. Let’s go back to our simple query, so you can see what I mean. In a new session I’ve set the OPTIMIZER_INMEMORY_AWARE parameter to FALSE and executed our query.
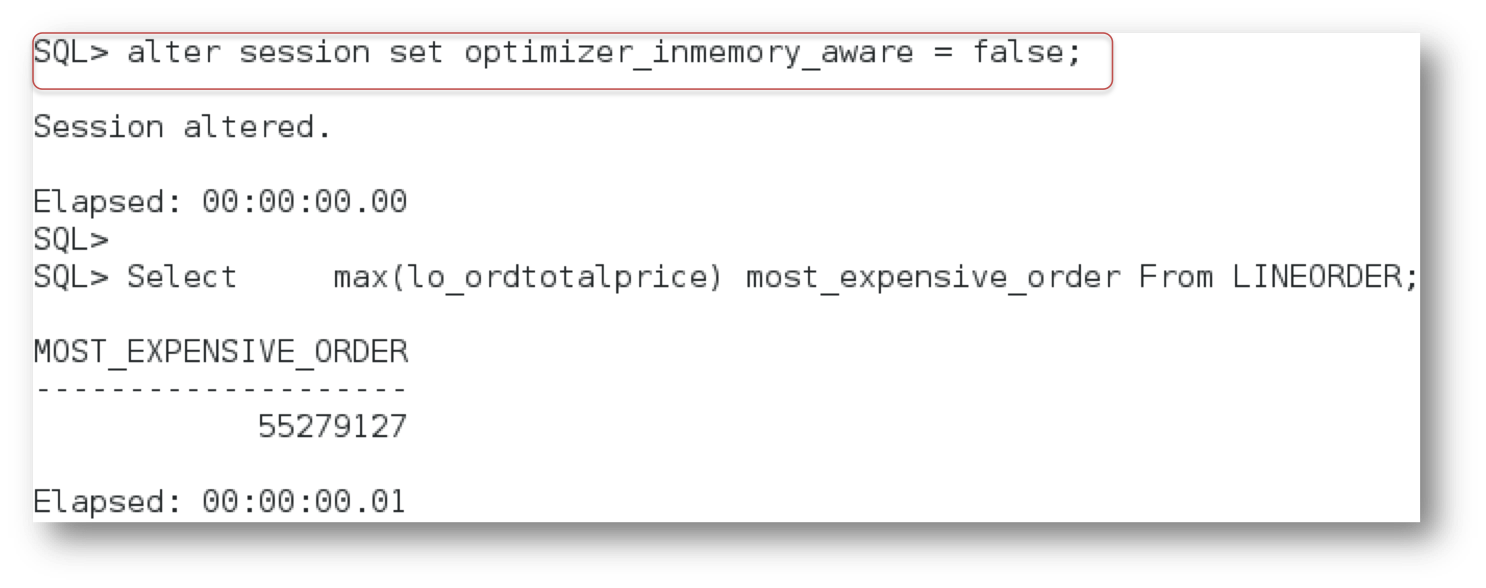
As you can see, we still get a sub-second response time and the execution plan below shows we get a TABLE ACCESS INMEMORY FULL, so does that mean the parameter change didn’t take effect?
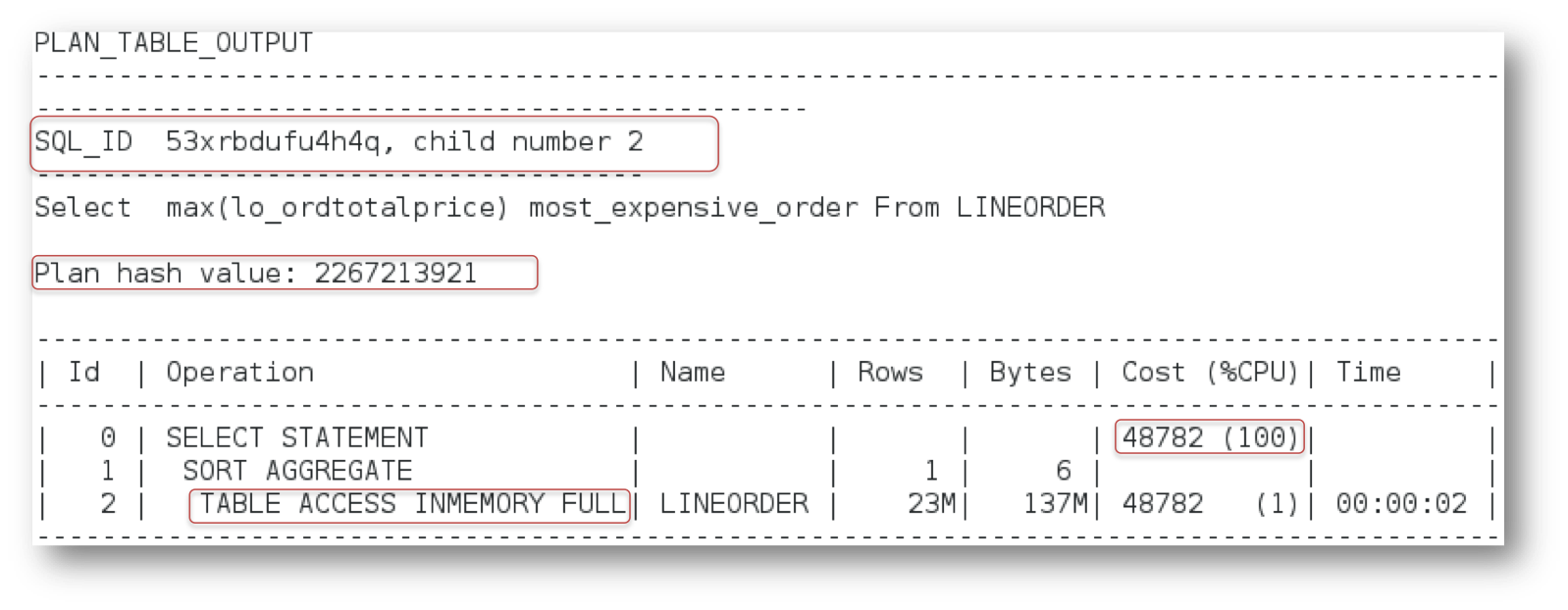
No, the parameter definitely did take effect. The change in the Optimizer environment forced a new child cursor to be created (child number 2). You can confirm this by querying v$SQL_OPTIMIZER_ENVIRONMENT.
SELECT c1.name,
c1.value,
c2.value,
c3.value
FROM v$sql_optimizer_env c1,
v$sql_optimizer_env c2,
v$sql_optimizer_env c3
WHERE c1.sql_id = ‘53xrbdufu4h4q’
AND c2.sql_id = ‘53xrbdufu4h4q’
AND c3.sql_id = ‘53xrbdufu4h4q’
AND c1.child_number = 0
AND c2.child_number = 1
AND c3.child_number = 2
AND c1.name = c2.name
AND c1.name = c3.name
AND c1.value != c3.value;

We can also see the effect of the parameter on the cost of the plan. If you look back at the original two plans, you’ll see that the default In-Memory plan had a cost of just 2,201, while the non In-Memory plan had a cost of 48,782. The new plan also has a cost of 48,782. So although the Optimizer didn’t consider the in-memory statistics for the table, it still came up with a full table scan plan based on the disk statistics hence the high cost.
But that doesn’t explain why the keyword INMEMORY still shows up in the plan? The keyword remains in the plan because we actually executed the scan via the IM column store.
If you would rather influence the use of the IM column store at an individual statement level then you can do so using the INMEMORY and the NO_INMEMORY hints. There’s been a lot of confuse about what these hints actually control, so check out the full story on the Optimizer blog.
Hopefully this post has made it clear how you can use the new initialization parameters control the use of the In-Memory column store and the In-Memory statistics.
Original publish date: May 8, 2015
