Let’s consider a star schema, with one fact table and 9 dimension tables (time, customer, product, channel and demographic attributes such as age and income).
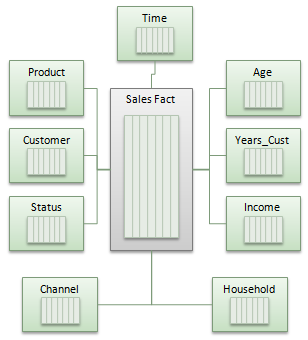
All tables have been marked INMEMORY MEMCOMPRESS FOR QUERY. The main fact table has 5 years worth of data ( 500 million row) and the fact and time table are partitioned by month. A pretty standard star schema. The fact table also uses the new attribute clustering feature.
To compare CPU usage between different plans, queries were run with and without Oracle Database In-Memory. We also executed the queries serially (with the NO_PARALLEL hint), to isolate the data access and SQL processing operations. SQL Monitor was used to report CPU time for each query.
- Query #1 represents a typical ad-hoc analytic query that would be executed by a marketing or sales analyst. It’s a 10 table join (fact plus 9 dimension tables) that selects mid-hierarchy aggregates using relatively selective filters that returns 90 rows aggregated from 35 million row.
SELECTd1.calendar_year_name,d2.all_products_name,d2.department_name,d2.category_name,d3.all_customers_name,d3.region_name,d4.all_channels_name,d5.all_ages_name,d5.age_name,d6.all_sizes_name,d6.household_size_name,d7.all_years_name,d8.all_incomes_name,d9.all_status_name,SUM(f.units),SUM(f.measure_9),SUM(f.measure_8),SUM(f.measure_6)FROM time_dim d1,product_dim d2,customer_dim d3,channel_dim d4,age_dim d5,household_size_dim d6,years_customer_dim d7,income_dim d8,marital_status_dim d9,units_fact fWHERE d1.day_id = f.day_idAND d2.item_id = f.item_idAND d3.customer_id = f.customer_idAND d4.channel_id = f.channel_idAND d5.age_id = f.age_idAND d6.household_size_id = f.household_size_idAND d7.years_customer_id = f.years_customer_idAND d8.income_id = f.income_idAND d9.marital_status_id = f.marital_status_idAND d1.calendar_year_name=’CY2014′AND d2.all_products_name =’All Products’AND d2.department_name =’Computers’AND d3.all_customers_name=’All Customers’AND d3.region_name =’Asia’AND d4.all_channels_name =’All Channels’AND d5.all_ages_name =’All Ages’AND d6.all_sizes_name =’All Household Sizes’GROUP BY d1.calendar_year_name,d2.all_products_name,d2.department_name,d2.category_name,d3.all_customers_name,d3.region_name,d4.all_channels_name,d5.all_ages_name,d5.age_name,d6.all_sizes_name,d6.household_size_name,d7.all_years_name,d8.all_incomes_name,d9.all_status_nameORDER BY d1.calendar_year_name,d2.all_products_name,d2.department_name,d2.category_name,d3.all_customers_name,d3.region_name,d4.all_channels_name,d5.all_ages_name,d5.age_name,d6.all_sizes_name,d6.household_size_name,d7.all_years_name,d8.all_incomes_name,d9.all_status_name;
- Query #2 is more of a summary level report generated by a business intelligence dashboard. It’s a 5 table join (fact plus 4 dimensional) that selects data at high levels of aggregation (year, department, region and all channels), returning 18 rows that were aggregated from over 100 million rows.
SELECTd1.calendar_year_name,d2.all_products_name,d2.department_name,d3.all_customers_name,d3.region_name,d4.all_channels_name,SUM(f.sales),SUM(f.units),SUM(f.measure_3),SUM(f.measure_4)FROM time_dim d1,product_dim d2,customer_dim_500m_10 d3,channel_dim d4,units_fact_500m_10 fWHERE d1.day_id = f.day_idAND d2.item_id = f.item_idAND d3.customer_id = f.customer_idAND d4.channel_id = f.channel_idAND d1.calendar_year_name=’CY2012′AND d2.all_products_name =’All Products’AND d3.all_customers_name=’All Customers’GROUP BY d1.calendar_year_name,d2.all_products_name,d2.department_name,d3.all_customers_name,d3.region_name,d4.all_channels_nameORDER BY d1.calendar_year_name,d2.all_products_name,d2.department_name,d3.all_customers_name,d3.region_name,d4.all_channels_name;
- Query #3 represents the data used as the starting point for more detailed market segment analysis. Its a 10 table join (fact plus 9 dimension tables) that selects data using less selective filters at high levels of aggregation, returning 6,740 rows aggregated from over 500 million rows.
SELECTd1.calendar_year_name,d2.all_products_name,d2.department_name,d3.all_customers_name,d3.region_name,d4.all_channels_name,d5.all_ages_name,d6.all_sizes_name,d6.household_size_name,d7.all_years_name,d7.years_customer_name,d8.all_incomes_name,d8.income_name,d9.all_status_name,SUM(f.measure_3),SUM(f.units),SUM(f.measure_7),SUM(f.measure_9)FROM time_dim d1,product_dim d2,customer_dim_500m_10 d3,channel_dim d4,age_dim d5,household_size_dim d6,years_customer_dim d7,income_dim d8,marital_status_dim d9,units_fact_500m_10 fWHERE d1.day_id = f.day_idAND d2.item_id = f.item_idAND d3.customer_id = f.customer_idAND d4.channel_id = f.channel_idAND d5.age_id = f.age_idAND d6.household_size_id = f.household_size_idAND d7.years_customer_id = f.years_customer_idAND d8.income_id = f.income_idAND d9.marital_status_id = f.marital_status_idAND d2.all_products_name =’All Products’AND d3.all_customers_name=’All Customers’AND d6.all_sizes_name =’All Household Sizes’AND d7.all_years_name =’All Years’AND d8.all_incomes_name =’All Incomes’GROUP BY d1.calendar_year_name,d2.all_products_name,d2.department_name,d3.all_customers_name,d3.region_name,d4.all_channels_name,d5.all_ages_name,d6.all_sizes_name,d6.household_size_name,d7.all_years_name,d7.years_customer_name,d8.all_incomes_name,d8.income_name,d9.all_status_nameORDER BY d1.calendar_year_name,d2.all_products_name,d2.department_name,d3.all_customers_name,d3.region_name,d4.all_channels_name,d5.all_ages_name,d6.all_sizes_name,d6.household_size_name,d7.all_years_name,d7.years_customer_name,d8.all_incomes_name,d8.income_name,d9.all_status_name;
With Database In-Memory disabled plans included TABLE ACCESS FULL, Bloom filters, HASH JOINS, HASH GROUP BY and SORT GROUP BY operations. With Database In-Memory enabled plans included TABLE ACCESS INMEMORY FULL, KEY VECTOR CREATE and KEY VECTOR USE for joins and VECTOR GROUP BY for aggregation.
Below are the plans for query #2 without and with In-Memory

Plan for query #2, without Database In-Memory .

Plan for query #2 using Database In-Memory.
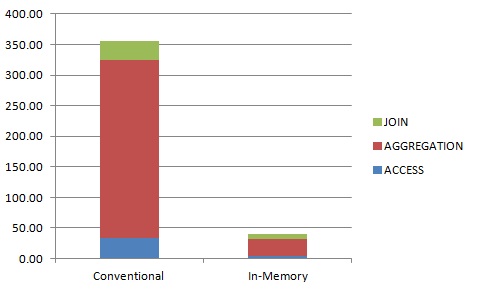
Average CPU time used for aggregation, joins and table access over three sample queries.
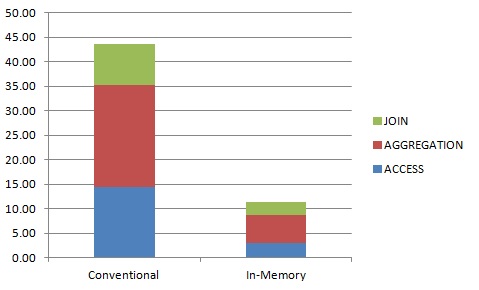
Query 2 is less selective and therefore more demanding because it aggregates a lot more rows (about 100 million). Database In-Memory reduced CPU time by 82%. Time to access and filter the tables was reduced by 54%, joins by 92% and aggregation by 84%.
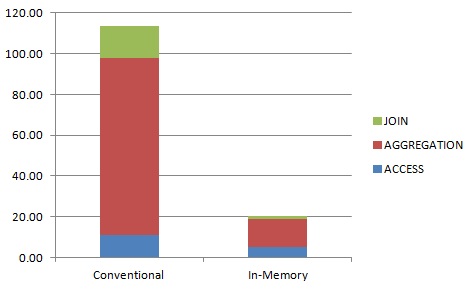
Finally query 3 is the most demanding query as it has the most joins, the most rows aggregated (about 500 million) and returns the larges result set.
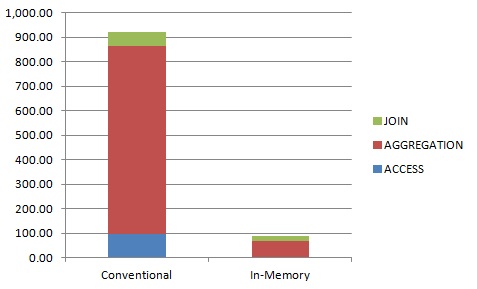
CPU time used for query #3.
Database In-Memory reduced CPU time by 90%. Time to access and filter the tables was reduced by 96%, joins by 65% and aggregation by 92%.
It is important to remember that these queries were run using the NO_PARALLEL hint and will run much faster in the real world using parallel query.
In general, as queries become more demanding with more joins and more rows aggregated Oracle Database In-Memory will provide a greater advantage by running queries faster and more efficiently, using less CPU. This leaves more capacity available for larger numbers of concurrent users or different workloads.
Original publish date: April 7, 2015
