I was interviewed recently by Dave Vellante on TheCUBE and wanted to share some thoughts on the discussion. We talked about database consolidation and why it still matters even when databases are deployed in the Cloud.
What is Database Consolidation?
Consolidation refers to running multiple databases on a single Virtual Machine or a single Bare Metal machine without virtualization. Most Cloud deployments of databases are done in Virtual Machines. I originally gained experience with database consolidation early in my career because we wanted to manage costs by purchasing larger machines and running multiple databases on them. The primary issues we were trying to solve were:
- Reduce administrative effort & cost
- Reduce costs by increasing asset utilization
The most striking example of “administrative effort” was a colleague of mine who personally managed more than 60 servers. He suffered a heart attack and unfortunately passed away (at a quite young age), and everyone realized it was really too much burden for one person to bear. It’s hard to know if the stress of his job contributed to his medical condition, but the loss of this critical employee certainly left the organization in a difficult position. Running fewer, larger machines with databases consolidated onto them would certainly reduce administrative effort. We have also known for a long time that any single database will not fully utilize whatever machine it runs on, so we could seriously reduce costs by increasing asset (server) utilization.
Average Utilization will be 15-20%
While utilization can vary widely, the average utilization of any server or Virtual Machine running a database will be in the range of 15% to 20% across any sufficiently large population of databases. We know this historically, and this number has not changed just because of the Cloud. We saw this with physical servers back in the days when customers deployed databases on dedicated servers. We saw this again when customers deployed databases inside dedicated Virtual Machines. We are now seeing the same when databases are deployed in dedicated virtual machines or “instances” in the Cloud. Whether deployed on-premises or in the Cloud, some utilization will be higher and some will be lower, but the average CPU utilization of any Virtual Machine will be in the range of 15% to 20%. The following graph shows a recent “live” production example where a customer deployed 181 databases on Virtual Machines in a Cloud service.
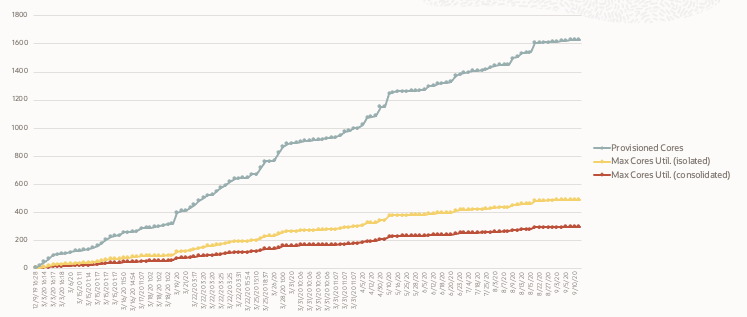
This graph shows what happened when an Oracle customer deployed databases onto Amazon’s Relational Database Service (RDS) starting in December 2019 through September 2020. Using system utilization metrics from Oracle Enterprise Manager, we graphed provisioned versus utilized cores (each vCPU is equal to 1/2 processor core) as the databases were provisioned over that period of time. The customer experienced average utilization of 17% (the red line) with the SUM of stacked hourly peaks at 26% (the yellow line) of the provisioned processor cores in Amazon’s Relational Database Service (RDS). The customer had contacted us to evaluate sizing for their entire Oracle Database estate and they noted the RDS service was proving to be much more expensive than they anticipated. If you are paying for 100% of the provisioned cores (the grey line) but using only 17% of those cores, the service is obviously going to be expensive. It’s important to note this is nothing unique to Amazon. It’s simply a fact of low system CPU utilization when resources are specifically dedicated to a database and databases are isolated onto dedicated Virtual Machines.
Example of Bursting for End of Month
We often see that customers have processing that will be more intensive during certain periods such as by day, week, month, fiscal quarter, year, or other frequency. Many retail customers typically see peaks during a holiday periods, while others might see peak processing periods for “back to school” shopping or other common peaks. Tax preparers see peaks during tax season, and government elections authorities see near zero activity most of the time, but extreme peaks during the days surrounding an election. The following graph shows a database deployed on Amazon RDS that experienced peaks around the end of each month.
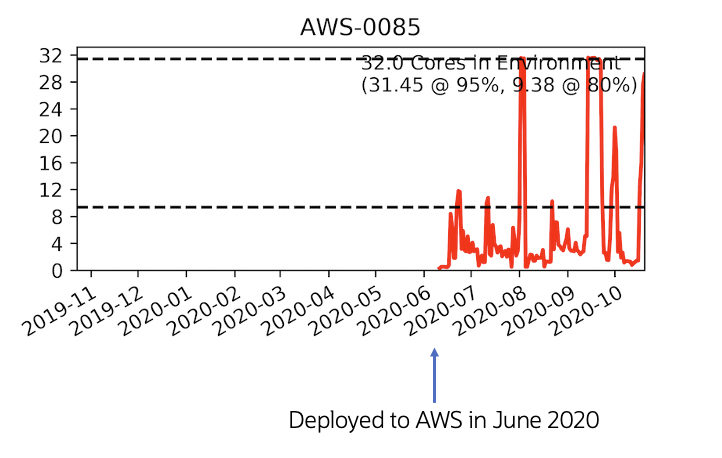
This graphic shows the CPU utilization of a Virtual Machine running a database that experiences peaks around the end of each month, but relatively low activity at other times. Unfortunately, the activity never completely stops, so it would be difficult to take an outage to scale the VM up and down. Again, this is a factor of the application and the business usage of the database, not a problem that’s unique to Amazon’s Cloud. Databases are “stateful” services unlike application servers, so it’s not possible to simply spin-up additional servers to handle the load (not without Oracle Real Application Clusters). The server name (AWS-0085) has been obfuscated in this case to protect customer confidentiality. This database was deployed in June 2020, and immediately showed a very bursty activity near the end of each month. The 80th percentile utilization is 9.38 processor cores, but the database actually saturated the system at the fully provisioned size of 32 cores in September of 2020.
This particular workload is bursty and is obviously related to some sort of monthly processing. We don’t know details of the particular application, but it could be related to financial processing or possibly monthly analysis of sales or other business process with a monthly cadence. Regardless of the business function, the fact remains that this database experiences a bursty workload that will be less active most of the time, but needs access to additional resources (such as CPU) during fairly short periods each month.
Example of Excess Provisioned Capacity
Another common issue in large scale deployments is the provisioning of more capacity than is truly needed. We can easily see cases of excess provisioned capacity by simply looking at graphs of CPU utilization using metrics collected by Oracle Enterprise Manager. The following graph shows 2 databases that each reside on dedicated Virtual Machines, which are provisioned with 16 processor cores but using less than 1 core (2 vCPU) on average.
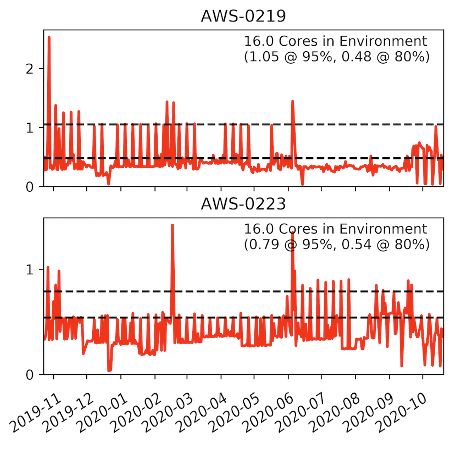
These appear to be obvious cases where the number of processor cores should be reduced from 16 (32 vCPU) to something more reasonable. The virtual machine AWS-0219 (obfuscated for customer confidentiality) could be reduced to 3 or 4 processor cores and the virtual machine AWS-0223 could be reduced to 2 processor cores and still contain the peaks. Discussion with the application owners will be required to determine why it was provisioned so large. The application team might anticipate future expansion of business activity, or this might have been an oversight. This customer has 181 databases deployed on AWS RDS, so this conversation has to happen with each and every database (181 times over), with each business area, and with each application owner to determine how to better manage the capacity. Downtime is required to scale the VM up or down, so these decisions can’t be taken lightly. In practice, there is no practical way to effectively manage capacity and therefore COST in such an operating environment.
Target 50% Utilization (N+1) with RAC
Increasing utilization from 17% to just 50% provides approximately 3X higher utilization and therefore 3X lower cost. We can use Oracle Real Application Clusters (RAC) on Oracle Exadata Cloud Service to ensure availability. We also recommend configuring applications with Oracle Application Continuity (AC) to allow the application to continue operating in the event of an Instance failure.

When a database instance fails, the application connections are automatically transferred to another instance and the application continues operating. There will be a slight period of slow-down (usually a few seconds), but no outage for the application. We recommend configuring and managing Exadata Cloud Service systems at 50% capacity in a 2-node configuration, or using the N+1 approach for larger deployments. If the application demand for database CPU equals the capacity of 2 instances, customers should deploy 3 for redundancy. Simply provisioning 1 extra node (or N+1 where N is the amount of resource required) and using Oracle Application Continuity will ensure continuous availability.
Isolation is Needed!
Isolation vs. Consolidation is not a binary choice, so it’s not one extreme or the other. We recommend being pragmatic and using isolation where needed and consolidation where it makes sense. We don’t recommend literally putting EVERY database into a single VM. In fact, we have identified 6 categories of business requirements for isolation as follows:

We recommend looking at each of these reasons why isolation is required before deciding how to deploy databases. The most common configuration is 4 systems, with separation of production versus non-production databases, as well as sites for production versus disaster recovery. Dedicated “disaster recovery” sites are much less common, with customers opting for an A/B methodology, where site A runs some production and some non-production, and site B does the same. In the A/B methodology, both are considered to be “production” sites and the “disaster recovery” copy for a given database might be at site A or site B.
Isolation Methods
Using Exadata, we have 5 methods for providing isolation between databases. We can isolate databases across different physical Exadata Cloud Service systems. We can isolate databases using virtual machines such as Multiple Virtual Clusters in Exadata Cloud@Customer. Databases can be isolated on different copies of the Oracle software or using multiple Container Databases (Oracle Multitenant). Finally, we can provide RESOURCE isolation (CPU, Memory, Processes, and I/O) using the Resource Management capabilities of Oracle Database and Exadata.
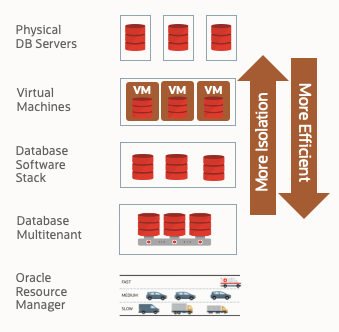
Matching Isolation Requirements vs. Methods
With an understanding of the 6 business requirements for isolation and the 5 methods available for isolating databases, the next task is to determine how to use those capabilities. The following table shows how we recommend matching isolation needs to capabilities:
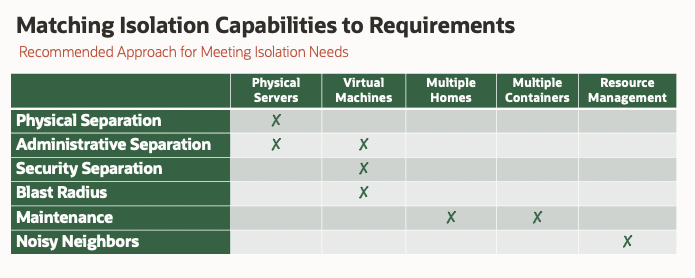
Physical separation dictates use of physically separate servers. These might reside in different geographic locations such as different Cloud Regions, or might reside in different areas of the same data center, or within different Availability Domains (AD) within a single Oracle Cloud Region. Administrative separation such as separation of DEV/TEST (i.e. non-production) from production is sometimes done by deploying on separate physical systems such as separate Exadata Cloud Service systems. In some cases, this level of separation is achieved by deploying on separate virtual machines (like separate Virtual Clusters in Exadata Cloud@Customer).
Isolation for security reasons is quite common, especially where customers have data that requires additional security measures such as meeting HIPAA or PII data security requirements. Some customers also have separate high-security networks to isolate all systems, network traffic, and databases from others in the environment. If the first 3 reasons for isolation don’t provide some level of sub-division, we might also add a degree of isolation for “blast radius” purposes. We have a high degree of redundancy built into Exadata, but it’s still great to have some amount of isolation.
Once we have provided the first 4 levels of isolation, the next level is maintenance. We can normally meet the isolation for maintenance purposes by simply providing a separate Oracle software stack (separate Oracle Homes) for databases that use a different maintenance or upgrade schedule. Maintenance cycles also extend to Oracle Multitenant Container Databases, where we can stack multiple databases into a single container to improve system resource utilization as well as reduction in administrative burden.
Once we have accounted for the prior 5 levels of isolation the last consideration is noisy neighbors. Rather than using Virtual Machines simply to control resources, we recommend using Oracle’s built-in Resource Management capabilities. In Exadata environments (including Exadata on-premises, Exadata Cloud@Customer, and Exadata Cloud Service), we have integrated resource management that include CPU, memory, system processes, parallel processes, I/O bandwidth, IOPS, and even FlashCache space. These features allow much more effective control of resources, while still allowing sharing of resources during periods of lower usage.
DR vs. HA
Disaster Recovery isn’t a suitable replacement for High Availability. The following chart shows a comparison between Virtual Machine restart after failure, failover to local standby, and RAC instance failure on the Exadata platform.
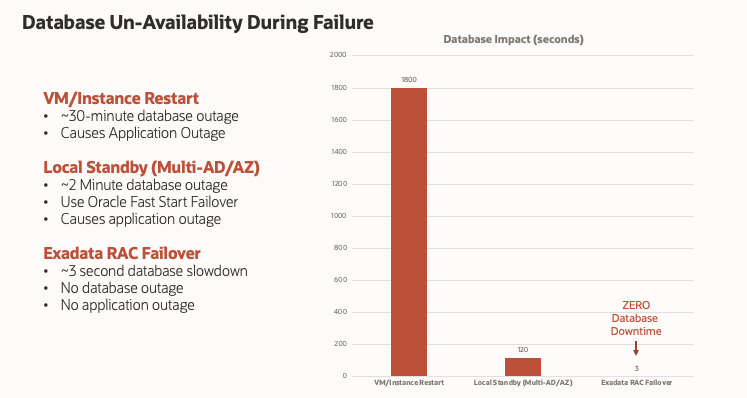
The ability to restart a Virtual Machine (or Cloud “instance”) within 30 minutes following a failure is extremely good, but represents a significant outage for most businesses. Failover to a local standby or a standby in another Availability Zone (what Oracle calls an Availability Domain) normally takes about 2 minutes (120 seconds) to restore service. Both of these cases represent downtime for the database. Application tier re-start is often required in these situations, which often adds another 30 minutes of downtime as seen by the end-user.
Failure of a RAC instance on Exadata is normally detected within about 3 milliseconds, and most databases will experience a performance impact for approximately 3 seconds. While there is an “impact” in these situations, there is no downtime for the database and applications using Application Continuity do not experience an outage or reconnect.
We consider a local standby to be a Disaster Recovery (DR) solution, not a High Availability (HA) solution. Failure of individual servers or Virtual Machines is much more common than failure of an entire Region or Availability Domain/Zone. High Availability requires redundancy and fault tolerance at the VM (instance) level, and clustering of Virtual Machines is the only method that provides fault tolerance without forcing database or application downtime. Even the 120 seconds required to failover to local standby is not fast enough to be considered an “HA” solution and it does not prevent an outage.
